







MaskRCNN
论文
Mask R-CNN
模型结构
Mask R-CNN的方法通过添加一个与现有目标检测框回归并行的,用于预测目标掩码的分支来扩展Faster R-CNN,通过添加一个用于在每个感兴趣区域(RoI)上预测分割掩码的分支来扩展Faster R-CNN,就是在每个感兴趣区域(RoI)进行一个二分类的语义分割,在这个感兴趣区域同时做目标检测和分割,这个分支与用于分类和目标检测框回归的分支并行执行,下图为MaskRCNN的模型结构示意图。
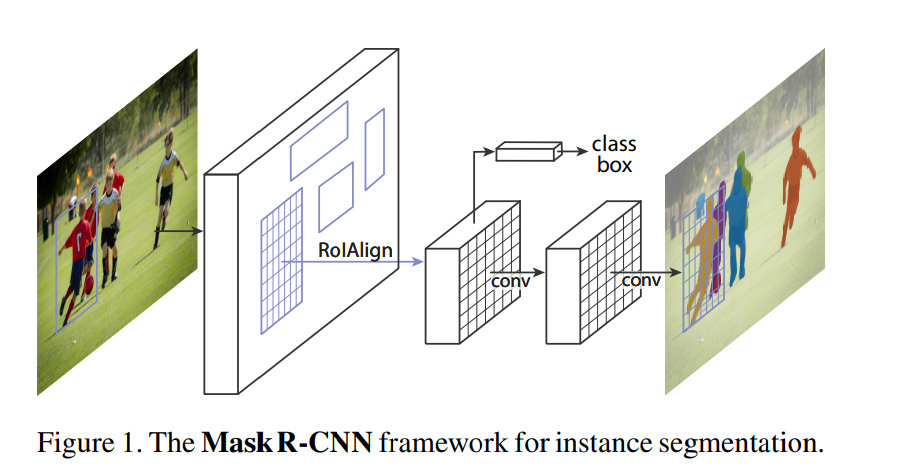
算法原理
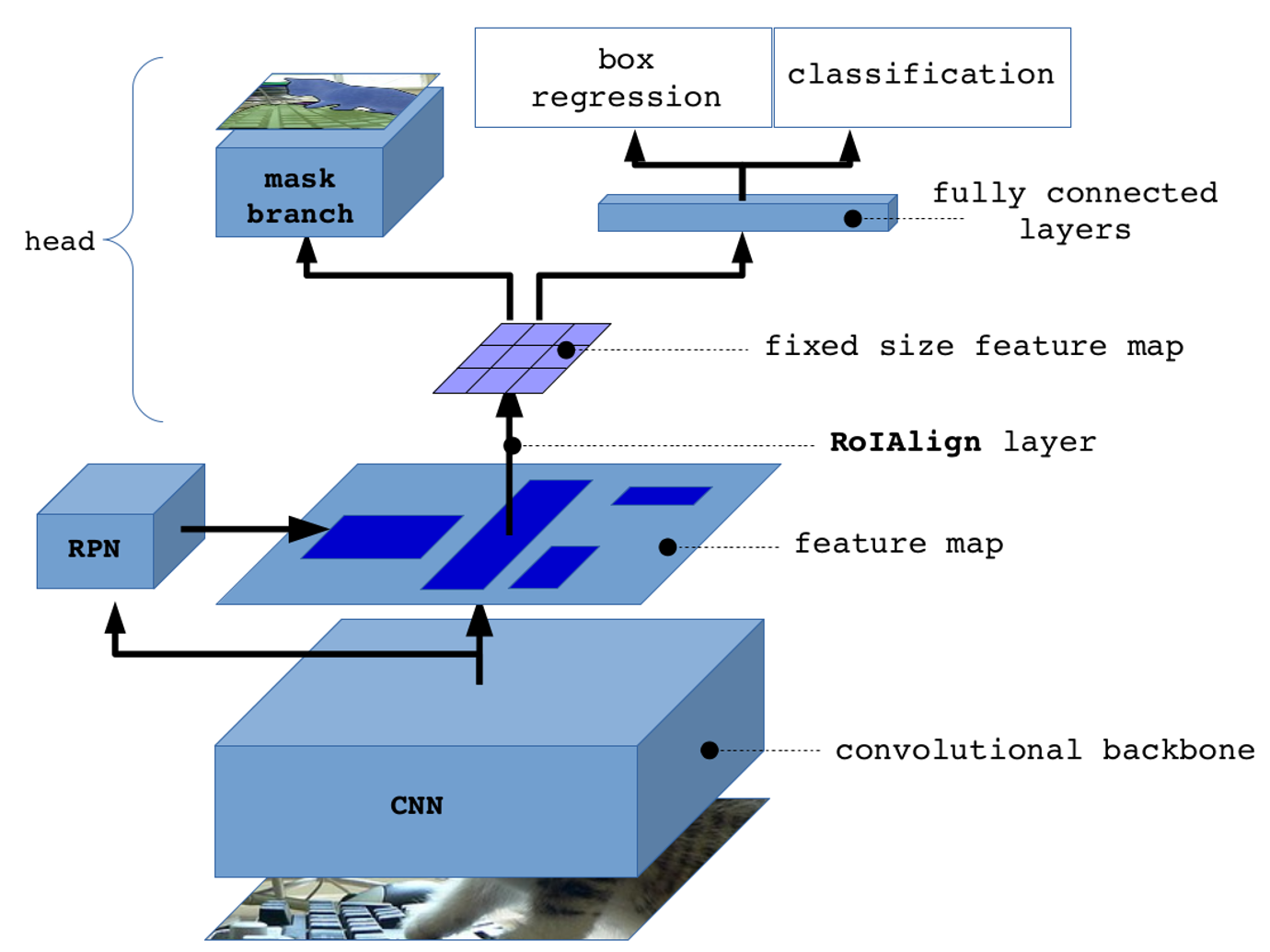
MaskRCNN通过使用RoI Align算法和Mask Head网络来实现像素级别的物体分割,并使用多任务损失函数来训练模型。该模型由以下几个组件组成:
- Backbone网络 Mask R-CNN的第一步是使用一个预训练的卷积神经网络(如ResNet)提取图像的特征。这些特征被称为“特征图”,可以用来检测图像中的物体和分割物体的像素。
- Region Proposal Network (RPN) 接下来,Mask R-CNN使用一个Region Proposal Network (RPN)来生成可能包含物体的区域。RPN是一个用于生成候选物体区域的神经网络,它在特征图上滑动一个小窗口,对每个窗口位置预测物体边界框的位置和该边界框包含物体的概率。
- RoI Align 在得到候选区域之后,Mask R-CNN使用RoI Align算法将每个候选区域映射到特征图上,并将映射后的特征图送入后续的全连接层中。RoI Align是一种可以保留特征图中精细位置信息的算法,可以提高物体检测和分割的精度。
- Mask Head 在RoI Align之后,Mask R-CNN使用一个称为“Mask Head”的神经网络来生成每个物体的精确分割掩码。Mask Head接收RoI Align层的输出,然后生成一个二进制掩码,表示每个像素是否属于该物体。
- 损失函数 最后,Mask R-CNN使用一个多任务损失函数来训练模型。该损失函数包括物体检测损失(用于预测物体的类别和边界框)、物体分割损失(用于生成物体的精确分割掩码)和RPN损失(用于生成候选物体区域)。这些损失函数同时优化,以提高模型的物体检测和分割性能。
环境配置
Docker (方法一)
提供光源拉取的训练的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:mlperf-maskrcnn-latest
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name mlperf_maskrcnn --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
Dockerfile (方法二)
docker build --no-cache -t mlperf_maskrcnn:latest .
docker run -it --name mlperf_maskrcnn --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
镜像版本依赖:
- DTK驱动:dtk22.10
- python: python3.7.12
测试目录
/root/maskrcnn
数据集
模型训练的数据集来自训练数据:COCO(Common Objects in Context),该数据集是一个广泛使用的大规模图像识别、目标检测和分割数据集,由微软公司研究员和康奈尔大学共同创建。该数据集包含超过33万张图像,其中超过20万张带有注释,涵盖了80个常见对象类别,包括人、动物、交通工具、家具、电子产品等。
每张图像都被注释了多个对象的位置和类别,注释信息包括对象的边界框、对象的类别、对象的分割掩模等。这些注释信息使得COCO数据集成为图像识别、目标检测和分割领域中最重要的数据集之一。
COCO数据集的广泛使用使得其成为计算机视觉领域中的一个标准基准测试数据集。许多目标检测、图像分割、实例分割算法都在COCO数据集上进行测试和评估,并且在该数据集上取得了许多优秀的结果。这些算法的进步也推动了计算机视觉领域的发展。
下载+预处理数据可按照下述进行:
#To download and verify the dataset use following scripts:
cd dataset_scripts
./download_dataset.sh
./verify_dataset.sh
#This should return `PASSED`.
#To extract the dataset use:
DATASET_DIR=<path/to/data/dir> ./extract_dataset.sh
#Mask R-CNN uses pre-trained ResNet50 as a backbone.
#To download and verify the RN50 weights use:
DATASET_DIR=<path/to/data/dir> ./download_weights.sh
#Make sure <path/to/data/dir> exists and is writable.
#To speed up loading of coco annotations during training, the annotations can be pickled since #unpickling is faster than loading a json.
python3 pickle_coco_annotations.py --root <path/to/detectron2/dataset/dir> --ann_file <path/to/coco/annotation/file> --pickle_output_file <path/to/pickled/output/file>
数据集的目录结构如下:
├── images
│ ├── train2017
│ ├── val2017
│ ├── test2017
├── labels
│ ├── train2017
│ ├── val2017
├── annotations
│ ├── instances_val2017.json
├── LICENSE
├── README.txt
├── test-dev2017.txt
├── train2017.txt
├── val2017.txt
训练
单机8卡
单机8卡进行性能&&精度测试
bash sbatch.sh
#注:可通过修改./maskrcnn_benchmark.bak/config/paths_catalog_dbcluster.py文件按需更改数据读取位置
result

精度
采用上述输入数据,加速卡采用Z100L * 8,可最终达到官方收敛要求,即达到目标精度0.377 Box min AP and 0.339 Mask min AP;
| 卡数 | 类型 | 进程数 | 达到精度 |
|---|---|---|---|
| 8 | 混合精度 | 8 | 0.377 Box min AP and 0.339 Mask min AP |
应用场景
算法类别
图像分割
热点应用行业
零售,广媒,医疗,交通
源码仓库及问题反馈
参考资料
- MLCommons | Better AI for Everyone
- MLCommons · GitHub
- training_results_v0.7/NVIDIA/benchmarks/maskrcnn/implementations/pytorch at master · mlcommons/training_results_v0.7 · GitHub


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











