







asr_onnx
论文
无
模型结构
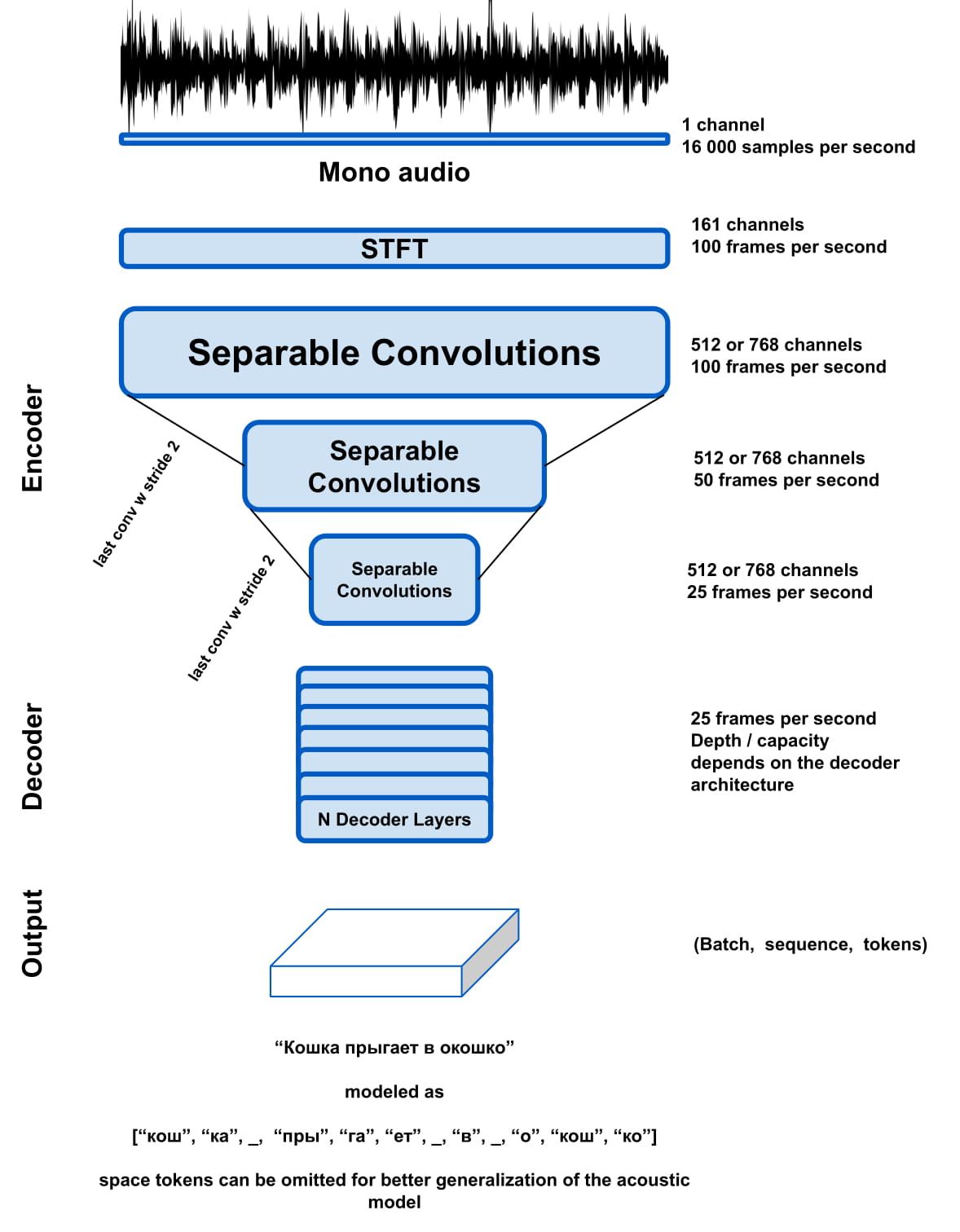
算法原理

数据集
无
环境配置
在光源可拉取推理的docker镜像,在光合开发者社区可下载onnxruntime安装包。asr_onnx推荐的镜像如下:
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
cd asr_onnxruntime #进入当前项目目录
docker run -d -t --privileged --device=/dev/kfd --device=/dev/dri/ --network=host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v `pwd`:/mnt --name=asr-test image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker exec -it asr-test /bin/bash
cd /mnt
pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pysoundfile -i https://pypi.tuna.tsinghua.edu.cn/simple
下载模型 (https://models.silero.ai/models/en/en_v5.onnx) 到当前目录,建立wavs文件夹添加测试wav文件。
预训练权重快速下载中心:SCNet AIModels ,项目中的预训练权重可从快速下载通道下载:en_v5 。
推理
python3 main.py --model_dir="./en_v5.onnx" --wav_dir="./wavs/" --warmup=1
# --wav_dir:需要推理的语音路劲,如"./speech_orig.wav";speech_orig.wav是文件夹中已经存在的语音
result
![]()
精度
暂无
应用场景
算法类别
语音识别
热点应用行业
交通,金融,医疗,教育,家居
源码仓库及问题反馈
ModelZoo / asr_onnxruntime · GitLab




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











