







超强计算eval
对于下面的numpy的向量化运算,其优点很明显:想比于普通的python循环或者列表综合运行速度要快很多,但是对于下面的复合代数式问题的运算效率就比较低。
mask = (x>0.5) & (x<0.5)
#上式等价于于:
tmp1 = (x>0.5)
tmp2 = (y<0.5)
mask = tmp1 & tmp2
原因是,每段中间过程都需要显式的分配内存。如果x数组和y数组很大,这么运算将会占用大量的时间和内存。Numexpr程序库可以让你在不为中间过程分配全部内存的前提下,完成元素到元素的复合代数式运算。Pandas的eval()和query()工具就是基于Numexpr实现的。用pandas.eval()实现高性能运算
pd.eval()支持的运算
1、算术运算df1,df2,df3,df4,df5 = (pd.DataFrame(np.random.randint(0,1000,(100,3))),for i in range(5))
result = pd.eval('-df1 * df2 / (df3 + df4) -df5')
2、比较运算result = pd.eval('df1 < df2 <= df3 != df4')
3、位运算result = pd.eval('(df1<0.5) & (df2<0.5) | (df3<df4)')
5、对象属性和索引result = pd.eval('df2.T[0] + df3.iloc[1]')
用DataFrame.eval()实现列间运算
由于pd.eval()是pandas的顶层函数,因此DataFrame有一个eval()方法可以做类似的运算. 使用eval()方法的好处是可以借助列名称进行运算.result = pd.eval("(df.A + df.B) / (df.C -1)")
1、用DataFrame.eval()新增列df.eval('D = (A+B) / c', inplace=True)
2、DataFrame.eval()使用局部变量column_mean = df.mean(1)
result = df.eval('A + @column_mean')
超强查询query
1、引用外部变量+in查询
import pandas as pd
df = pd.DataFrame({'a':[1, 2, 3, 4, 5, 6],
'b':[1, 2, 3, 4, 5, 6],
'c':[1, 2, 3, 4, 5, 6]})query_list = [1, 2]
#对返回得df 有取了 a ,b 两列
df_2 = df.query('c not in @query_list')[['a', 'b']]
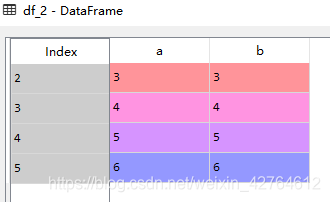
2、大小 等于查询
![]()
result = df.query('A < @Cmean and B < @Cmean')
df.query("b=='aabb'") #b 是某列3、包含模糊查询
df.query('column_a.str.contains("abc") or column_b.str.contains("xyz") and column_c>100')














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









