







UTF表示的是存储格式 (ASCII码和Unicode 都是编码方式)
历史背景:
ASCII
最早出现的是ASCII码(American Standard Code for Information InterChange美国信息交换代码)
特点:7位表示一个字符,共表示128个字符(满足西方国家使用的字符)
随着计算机的传播:发现ASCII码不够用就出现了
ISO-8895-1
ISO-8895-1与ASCII码的区别用8bit来表示一个字符,即一个字节表示一个字符,所以可以表示256个字符(是在ASCII码的基础上 扩充的,所以完全向下兼容,而且将一个字节 所有的位都用上了)
我们有很多汉字,发现ISO-8895-1不够用了,就出现了GB2312(GB 的意思就是:国家标准,即国标)
GB2312
GB2312用两个字节:表示一个汉字,常见的汉字基本可以用
但是很多生僻字无法满足需求,于是有了GBK
GBK
GBK兼容GB2312
后来发现又不够用
出现了GB13080
国际组织发现每个国家都有自己的编码方式,操作系统就要支持很多编码方式,所以需要进行定制unicode
unicode
unicode 支持所有国家的字符,都已用unicode表示 出来,采用两个字节来表示一个字符(但是有的国家ASCII码就可以用了,为为什么还有两个字节,所以就用0对高位进行填充,这样方式存储空间得到膨胀,存在空间浪费)
UTF(Unicode translation format)
UTF和Unicode之间有什么联系:UTF表示的是存储格式 (ASCII码和Unicode 都是编码方式)
utf-8 是Unicode的一种实现方式,而且utf-8是变长存储,0-127 这个字符 与ASCII进行编码,对于中文utf-8由三个字节表示一个中文

基础知识补充:
什么是编码:编码就将字符 类型变为字节类型
什么是解码:解码就是将字节类型变为 字符
文件写入到磁盘都是通过字节 来写入的,文件的存储都是字节来表示的
字符是指对字节的一种表示形式(编码形式)
每一个文件存在磁盘上都会有一种编码
通过java代码来介绍各种字符集
先以utf-8为例
package com.jiahongfei.nio;
import java.io.File;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
import java.util.Map;
/**
* 编解码问题
*/
public class NioTest11 {
public static void main(String[] args) throws Exception{
String inputFile = "NioTest11_in.txt";
String outputFile = "NioTest11_out.txt";
RandomAccessFile inputRandomAccessFile = new RandomAccessFile(inputFile,"r"); //随机读取文件
RandomAccessFile outputRandomAccessFile = new RandomAccessFile(outputFile,"rw");
long length = new File(inputFile).length(); //获取输入文件的长度
FileChannel inputFileChannel = inputRandomAccessFile.getChannel();
FileChannel outputFileChannel = outputRandomAccessFile.getChannel();
MappedByteBuffer inputData = inputFileChannel.map(FileChannel.MapMode.READ_ONLY,0,length); // 用映射文件,这样修改内存,会自动同步到磁盘
Charset charset = Charset.forName("utf-8");
CharsetDecoder decoder = charset.newDecoder(); //解码:将字节变为字符或字符串
CharsetEncoder encoder = charset.newEncoder(); //编码:将字符,或字符串变为字节
CharBuffer charBuffer = decoder.decode(inputData);
ByteBuffer byteBuffer = encoder.encode(charBuffer);
outputFileChannel.write(byteBuffer);
inputRandomAccessFile.close();
outputRandomAccessFile.close();
}
}

我们用utf-8编码时,正确的
NioTest11_in.txt 文件中有中文,输出到 NioTest11_out.txt 正常
我们把编码改为iso-8859-1

运行结果 仍然正常
问题一:为什么这个程序用iso-8859-1没有乱码
因为NioTest11_in.txt文件我们用的是utf-8编码格式,中间过程接卸可能有乱码,但是中间过程中没有字符丢失,最后输出的文件NioTest11_out.txt也是utf-8就没有乱码
问题二:为什么平时使用iso-8859-1乱码了
出现乱码的几种场景
当我们文件(输入,输出文件都用的utf-8编码) 从ByteBuffer中用的是ISO-8859-1解码,然后将CharBuffer编码为ByteBuffer用的utf-8,输出到文件中就乱码了,因为编解码的方式不一样(用ISO-8859-1解码时用的字符,utf-8 不认识造成字符,就造成了乱码)

乱码场景二:输入文件和输出文件都用的gbk,中间用的是iso-8859-1
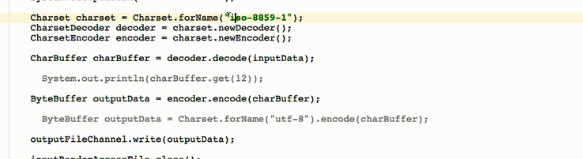
知识补充如何快速查看一个文件的编码方式
方法一:用idea
















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









