







1、Hive体系架构
如图3-1所示,Hive体系架构可以分为4部分。
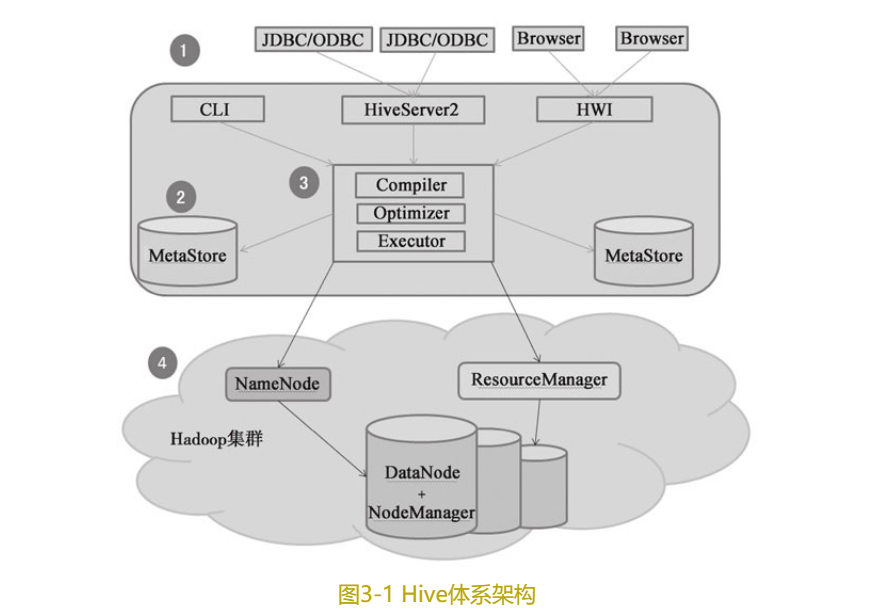
1.1❑用户接口。
用户与Hive交互主要有3种方式:CLI(Hive命令行模式)、Client(Hive的远程服务)和WUI(Hive的Web模式)。CLI方式主要用于Linux平台命令行查询。WUI方式是Hive的Web界面访问方式,通过浏览器访问Hive。Client是Hive的客户端,连接至远程服务HiveServer2。
1.1.1 JDBC连接Hive代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class Test{
public static void main(String[]args){
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn=DriverManager.getConnection("jdbc:hive2://192.168.0.130:10000/testhive","root","");
String sql="create table emp(empno int,ename string,job string)row format delimited fields terminated by','";
PreparedStatement ps =conn.prepareStatement(sql);
ps.execute);
}
}
1.2❑元数据存储。
Hive将元数据存储在数据库中,如MySQL、Derby等,其中元数据存储依赖于Metastore DB服务。Hive中的元数据包括表名、表的列和分区及其属性、表的属性(是否为外部表)、表的数据所在目录等。
1.3❑解析器、编译器、优化器。
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成,随后由MapReduce调用执行。
1.4❑数据存储。
Hive中表的数据存储在HDFS中,包含表(Table)、外部表(External Table)、分区(Partition)、桶(Bucket)等数据模型,其中数据库、分区、表都对应HDFS上的某个目录,Hive表里的数据存储在表目录下面。
- ***外部表和表主要区别是对数据的管理。***External Table数据存储在建表时由Location指定的目录中,且当删除External Table时,只删除表的结构,而不删除数据。
2、Hive支持的数据类型
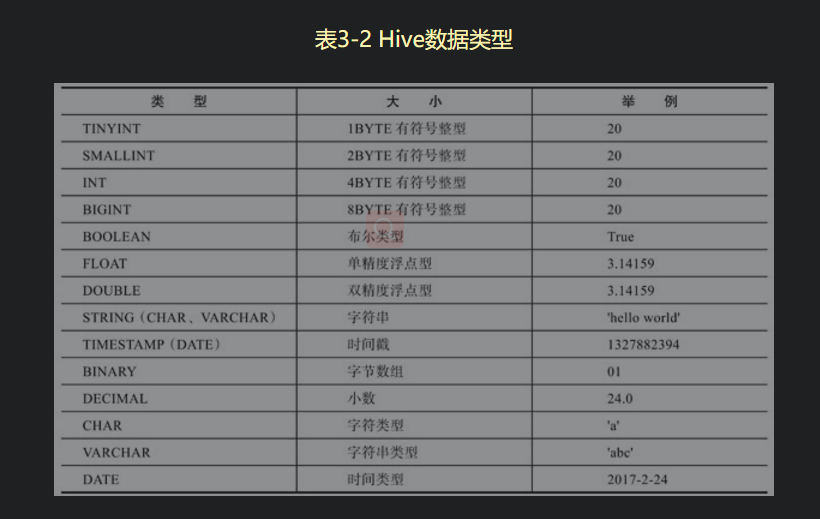
2.1 基础数据类型
2.2 复杂数据类型
(1)ARRAY
ARRAY类型是由一系列相同数据类型元素组成的,这些元素可以通过下标来访问,ARRAY类型的下标是从0开始的。例如user是一个ARRAY类型,由[‘firstname’, ‘lastname’]组成,那么可以通过user[1]来获取该用户的lastname。
(2)MAP
MAP包含key→cfvalue键值对,可以通过key来访问元素。例如user是一个map类型,其中name是key, age是value,那么可以通过user[‘name’]来获取对应的age。
(3)STRUCT
STRUCT可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来获取。例如user是一个STRUCT类型,那么可以通过user.age得到该用户的年龄。
3、HiveSQL语句
- hive不支持事务及更新操作,延迟比较大
3.1 Hive创建表语句
CREATE [ EXTERNAL] TABLE [ IF NOT EXISTS][ db_name.] table_name
[(col_name data type [ COMMENT col_comment],..)]
[ PARTITIONED BY (col_name data_type,...)]
[ CLUSTERED BY (col_name, col name,...)[ SORTED BY (col_name [ ASCI DESC],...)]
INTO num_buckets BUCKETS]
[ ROW FORMAT row_format][ STORED AS file_format]
[ LOCATION hdfs_path]
其中,参数说明如下:
(1)CREATE TABLE:
创建一个指定名字的表。如果相同名称的表已经存在,则抛出异常;用户可以使用IF NOT EXISTS这个选项来忽略这个异常。
(2)EXTERNAL:
该关键字可以让用户创建一个外部表,在建表的同时使用LOCATION关键字指向数据存储路径。外部表在删除时,只删除其对应的元数据,而不删除数据。
(3)COMMENT:
用作字段的注释。
(4)PARTITIONED BY:
指定分区表的分区字段,可以为多个字段。
(5)CLUSTERED BY:
Hive中Table可以拆分成PARTITION, Table和PARTITION可以通过PARTITIONED BY进一步分为Bucket, Bucket中的数据可以通过CLUSTERED BY对数据排序。
(6)STORED AS:
指定Hive文件存储格式,Hive存储格式有以下4种:
●TEXTFILE格式
默认格式,数据不压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,Hive不会对数据进行切分,从而无法对数据进行并行操作。
●SequenceFile格式
是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。SequenceFile支持3种压缩选择:NONE、RECORD、BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
●RCFILE格式
是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个块。其次,块数据列式存储,有利于数据压缩和快速的列存取。
(7)LOCATION:
创建外表时,指定数据在HDFS上的存储目录。
3.2 Hive中定义表有5种方式
3.2.1 创建内表
CREATE TABLE customer(customerID INT, firstName STRING, lastName STRING, birthday TIMESTAMP)
ROW FORMAT DELIMITED FIELDS TERMINATED BY','; --表示指定使用“, ”分隔每列数据
3.2.2 创建外表
CREATE EXTERNAL TABLE salaries(gender string, age int, salary double, zip int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY',
'LOCATION '/user/trai n/salaries/'; --指定数据存储位置(默认存储在hive-site.xml中hive.metastore.warehouse.dir对应目录下面)
3.2.3 创建静态分区表
--1、创建employees表
CREATE TABLE employees(id int,name string,salary double,depts string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
--2、导入数据到employees表
LOAD DATA LOCAL INPATH'/data/employees part.txt'OVERWRITE INTO TABLE employees;
--3、创建静态分区表employees_part
CREATE TABLE employees part(id int,name string,salary double,depts string)
PARTITIONED BY(dept string)ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
--4、导入数据到静态分区表employees_part
INSERT OVERWRITE TABLE employees part PARTITION(dept='SALES')SELECT * FROM employees WHERE depts='SALES';
3.2.4 创建动态分区表
--1、创建student表
CREATE TABLE student(
id int,name string,score double,classes string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
--2、导入数据到student表
load data local inpath'/data/students.txt' overwrite into table student;
--3、创建动态分区表student_dynamic
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nostrict;
CREATE TABLE student_dynamic(
id int,name string,score double,classes string)
PARTITIONED BY(class string)ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
--4、导入数据到动态分区表
INSERT OVERWRITE TABLE student_dynamic PARTITION(class)SELECT *,classes FROM student;
3.2.5 创建带有数据的表
--创建stu表,并导入数据
CREATE TABLE stu(id int, name string, score double, classes string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA INPATH '/data/students. txt' OVERWRITE TABLE stu;
3.3 数据导入
LOAD DATA [ LOCAL] INPATH ' filepath'[ OVERWRITE] INTO TABLE tablename
[ PARTITION(partcol1=val1, partcol2=val2...)]
导入语句带有LOCAL关键字,那么LOAD命令会查找本地文件系统中的filepath。如果没有LOCAL关键字,那么就会查找HDFS上面的路径。这里建议使用绝对路径。
3.4 数据导出
INSERT OVERWRITE [LOCAL] DIRECTORY '路径' ROW FORMAT DELIMITED FIELDS TERMINATED BY','
SELECT字段1,字段2,字段3FROM表名;
















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











