






线程基础知识
线程的历史-CPU性能压榨的血泪史

io课
大厂必问_什么是进程线程纤程(GO12课有、线程池基础)
进程:
静态单位:资源分配的基本单位,分配资源
qq.exe被执行1次,程序被加载到内存叫进程
执行以线程执行主线程
线程
通俗角度理解什么是线程
程序不同的执行路径是线程
- 只有一个线程在运行

- 一个线程出现了分支,有不同的线程做不同的事

从底层角度理解什么是线程
调度执行基本单位,多个线程共享进程这个资源
纤程/协程
程序
可执行文件

什么是线程的切换
程序:指令数据
cpu:计算(指令)、寄存器组(数据)、pc寄存器(算到哪儿)
- T1线程执行一半切换到T2就先把T1放到缓存里执行T2,线程切换时操作系统决定;

单核CPU设定多线程是否有意义
同个时间段只能跑1个线程,A线程等待数据状态时不消耗CPU,可以运行B线程,充分利用CPU资源;
- cpu密集型:cup做大量计算;
- io密集型:大量io做等待;
线程数是不是越大越好_1
不是;
线程切换要消耗资源,10000个线程cpu消耗在线程切换上;
实验
多线程分段处理大量数据集合
线程数设多少最合适_1
- 压测来决定;
- 看机器配置几核,每个核都用上效率最高,但是为了安全最多占用80%给别的程序留空间,假设合适的值在压测来决定;
不一定每个核都充分利用,因为有操作系统和java程序

线程设定公式

- W/C:
W:等待时间
C:计算时间
两个数的比值:1/1 - Ucpu:期望cpu利用率:100%
- Ncpu:核心数:1
- 11(1+1)=2只需要2个线程
怎么知道cpu的等待时间和计算时间
- 部署上去,运行之后,通过一些统计才能知道;
- 通过性能分析工具测算:profiler、jprofiler、arthes(阿里)、调用链路追踪;
阶段小结
- 压榨发展历史
- 底层理解线程
线程调度 - 什么是程序线程进行的概念基础知识
面试题:创建线程的5种方法
Thread_Runnable_Lambda
用Runnable创建比较合适;

使用ThreadPool

线程池就是一个池子,里边有好多线程
线程池和Callable

通过泛型指定带返回值的任务执行返回什么类型;
Future:异步的概念;
Future.get()是阻塞方法,什么时候返回值什么时候往下执行;
运用FutureTask
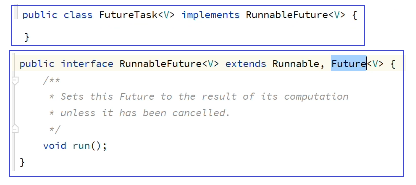
FutureTask实现了RunnableFuture接口,
RunnableFuture接口继承了Runnable的实现了run()方法可以运行,
RunnableFuture接口既是Runnable又是Future,自己可以运行结果也可以装在自己里
- 用法

- 创建FutureTask(把Callable扔进去)
- 创建Thread(把FutureTask扔进去)
- 启动线程
- 获取返回结果FutureTask.get()
阶段总结

最终都是new Thread()对象,线程池源码也是new Thread()对象
线程状态(问的不多)
6种线程状态的简介
- NEW:线程刚刚创建,还没有启动
- RUNNABLE:可运行状态,由线程调度器可以安排执行
分为2种:1、可以运行;2、正在运行; - WAITING:等待被唤醒
- TIMED WAITING:指定时间自动唤醒
- BLOCKED:被阻塞,等着拿锁,经过系统调度的,
- TERMINATED:线程结束

线程状态迁移简介

- 对象创建出来run()还没start()是
NEW - start()进入
RUNNABLE
正在运行是RUNNING
cpu线程切换yield方法
可以运行的状态但是没被运行READY,需要yield切换成RUNNABLE - 等着拿锁进入同步代码块是
BLOCKED阻塞状态 - 被这被唤醒
WAITING,非阻塞状态 - 等着指定时间到了自动唤醒
TIMED WAITING,非阻塞状态
NEW_RUNNABLE_TERMINATED

WAITING_TIMEDWAITING

BLOCKED

申请不到锁,正在等待拿锁;
线程状态在Lock和synchronized的区别

- 等待拿锁的状态不同:
synchronized:BLOCKED
Lock:WAITING 忙等待 - 只有synchronized是BLOCKED的状态是由系统调度的,其他的状态都是WAITING或者TIMEDWAITING,
park之后的线程状态

线程状态阶段总结
大图
线程“打断”inerrupt(中级:容易混淆)
线程打断3方法

- 设置标志位
- 查询标志位
- 查询标志位并重置标志位
interrupt_and_isInterrupted

interrupt_and_interrupted

interrupt_and_sleep

线程睡眠时可以打断的,不过会异常然后打断默认重置,然后看你怎么处理。
interrupt_and_wait

和上面一样,异常然后看你怎么处理
interrupt_and_synchronized
锁竞争:synchronized设标志位不能干扰争抢锁,不会抛异常,设置标志位该抢锁还是继续抢锁

interrupt_and_lock
设标志位不能干扰lock锁;
interrupt_and_lockInterruptibly
lockInterruptibly可以被打断的过程,抢锁的过程盯着标志位,有人打断我抛异常,cache住逻辑交给程序员;

interrupt_阶段总结

线程的“结束”(有可能问道)
问题:如何优雅的结束一个正在运行的线程
服务器24小时跑着,不能直接就打断,那样有客户端连着,一些数据就没了;
使用stop方法结束线程(废了)

非常粗暴,正在运行着二话不说直接停止了,容易产生数据不一致的问题;
为什么不建议使用stop方法?
太粗暴了,不管线程啥状态直接就干掉了,释放所有的锁,容易产生数据不一致的问题;
使用suspend_resume方法暂停/恢复线程(废了)

suspend:暂停
resume:恢复
- 和stop是用样的原因
为什么不建议使用suspend_resume
暂停的时候正在持有一把琐,容易产生死锁的问题;
volatile结束线程

- 不依赖循环里的中间状态
wait()阻塞, - 不能控制时间
interrupt(线程自带的标志位)结束线程

检查标志位被设定了就退出,比较优雅一些,循环一次检查一次标志位,
阶段总结

比如给服务器上传大文件,想终止就只能用3和4,需要子线程和外面的线程相结合就需要用到锁,后面会讲;
并发编程三大特性简介(必问)
可见性
有序性
原子性
并发编程之可见性
从一个程序谈起
可见性的基本概念

程序启动running读到主内存中,线程缓存了一份,t2修改的是它缓存的running所以t1读不到;
线程改了值其他线程看不到,除非主线程改了内存中的值其他线程才会看到;
用volatile保障可见性
修饰这块内存,对于任何的修改立马刷新到主内存,其他线程立马可见;
04_某些语句触发内存缓存同步刷新

system.out.pringln()触发了可见性机制,源码有synchronized同步锁可以保持可见性;
volatile修饰引用类型


三级缓存_01


缓存行的基本概念
- for循环时候读1个值,会把相邻的值也读到缓存里,这一块数据叫缓存行,

- 缓存行,一行是64个字节,读x会把y也读进来,

局部性原理
都到某一个数据,相邻的数据很快能读到,
- 空间局部性原理:用到一个值会读到周边的值,
- 时间局部性原理:指令的问题,读指令一次性读很多的指令到缓存,
通过程序认识缓存一致性_01
缓存一致性和volatile没有任何关系;
t1修改了x需要通知t2,t2修改了y需要通知t1,因为xy在同一个缓存行里,所以速度慢;

- 想要快就用其他空的变量
填充把64字节占满(真的会有人这样写程序 jdk1.7 Linked Blo...Queue 这个类);

认识Disruptor(效率最高的MQ单机版)中缓存行对齐的写法
- 框架:闪电(效率最高的MQ单机版)
装消息都有个缓存,MQ是环形的缓存有1个指针围着来回转,

认识Contended写内部类用
痛点:如果缓存行变成128字节,代码还得修改;
jdk1.8有个注解,被注解标注的数据单独占一行,

注意:默认@Contended是被限制的,JVM运行需要加参数才会起作用;
认识硬件层面的缓存一致性
MESI英特尔CPU的协议,我这个缓存行数据别的CPU也有缓存,我会主动监听缓存行数据有没有被修改;

为什么缓存一行是64字节?

工业实践得到的最高实践,折中值64字节;
阶段小结
可见性:volatile线程本地的换成互相保持缓存一致性的机制
缓存概念 123 缓存行
缓存一致性协议
并发编程之有序性
并发编程之有序性_问题的提出
程序真的是按“顺序”执行的吗?
乱序的验证/分析
为何会存在乱序
为了提高效率,指令1等待返回的时候执行指令2,充分利用cpu;
乱序的原则
指令可能换顺序执行
不影响单线程的最终一致性

通过一个小程序认识可见性和有序性_01

先执行了true,后执行了number那么输出就是0,
对象的半初始化状态_01
- 5条java汇编指令构成
申请分配内存空间
特殊调用默认构造方法
建立关联

- 对象的创建过程
new完是半初始化状态m=0,成员变量是默认值;
invok…是构造方法m=8
astore…是建立关系

this对象逸出_01
可能输出中间状态值0

解决:不在构造方法启动线程
构造方法启动完在启动线程
总结

下面是有序性解决
happens-before原则
JVM级别是java虚拟机,对java汇编语言做了约束有8条约束,一条lock锁底层都实现了;
CPU用屏障指令阻止乱序(jvm不是用的cpu的屏障指令)
每种cpu的屏障指令都不一样
内存屏障:中间加个隔层不让越过去,

JVM要求实现的四种屏障
实现jvm层级必须实现这4种机制,不想重排序加volatile就可以;

用volatile禁止指令重排
保持线程可见性
禁止指令重排序
volatile修饰的变量指向的内存空间进行内存屏障;别人读完我在写,别人写完我在写,我写别人不能读;

volatile在hotspot虚拟机中的实现
CPU底层有实现
JVM虚拟机有实现
加了volatile->class->acc_volatile->


有序性总结
并发编程之原子性(最复杂)
从一个小程序认识原子性的概念(一)

因为n++产生竞争,中途被别的线程打断了,导致数据不一致,n++需要原子操作

n++汇编为什么会被打断?
获取>压栈>加值>输出
这只是jvm的汇编就要5条,在翻译成CPU的可能会更多条,所以容易被打断;

n++上锁
synchronized保证了数据的可见性和原子性;

底层原子性和JVM原子性(一)

-
语言都要编译成CPU的汇编语言,
看汇编手册才能知道哪些是原子性; -
java有8大原子操作,java虚拟机规定了;
java判断不了就上锁
用上锁保证原子性
上锁就把代码块看作一个整体,执行的之后不能被打断;
上锁的本质(一)
- 把并发变成序列化操作,效率会变低,因为抢的是同一把锁子;
并发:三个人上同一个厕所,2秒钟全部方便完了;
序列化:一个人先上厕所,然后锁上门,其他人在外面等着;

- 不上同一把锁

一些同步的基本概念_锁的粒度
锁:某个对象当作锁;
临界区:锁定的代码块;
锁定了某个对象,持有这把锁才能执行;

小结
访问同一个数据,产生竞争条件>产生数据不一致>数据同步上锁>上锁的代码叫临界区
- 上锁:保障临界区里的原子性(2种方式:悲观、乐观)
悲观锁与乐观锁

- 悲观锁
比较悲观,总觉得会被别人打断,有没有人我都要锁上; - 乐观锁
无锁、自旋锁、cas
CAS的概念解析
先把值n=0读过来,写回去n=1的时候看一下是不是原来那个值,如果不是那就把现在的值n=5读过去,写回去n=6看下是不是n=5,如果不是那就再来一次直到成功,所以称为无锁;

CAS的ABA问题
- 在对象之间引用需要注意:
此0非彼0:A改成了B又改成了A
0读过来写1,读还是0,可能这个0被别的线程改8又被别的线程改0; - 解决:加version任何操作都+1,就知道是不是之前的值(时间戳、数字、版本);
CAS的底层原子性保障
CAS操作本身就是原子性的
通过Atomic类深入认识CAS
最终用的是cas乐观锁,调用本地native代码,底层是c++实现的,没有用同步锁;
深入Hotspot代码深入理解CAS
is_MP();是多核的就加lock,缓存锁或总线锁看情况而定,在底层还是有一把琐;

答疑与阶段小结
单核不用lock,自己不能打断自己的指令;
乐观锁与悲观锁的效率谁更高
- 实战就用synchronized同步锁;
悲观锁会有队列等待抢这把锁;等待的线程不消耗CPU资源;
乐观锁是while转圈的循环和线程切换,原地打转消耗CPU,消耗资源多于悲观锁;

临界区长,等的时间长就用悲观锁;
临界区短,等的时间短就用乐观锁;
synchronized和三大特性
- 可见性
unlock解锁时候,会对内存刷新,第二个线程才会开始执行,有内存屏障;保证不了有序性
















 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









