







一、优化
1.1 如何定位慢sql
(1)开源工具
- 调试工具:Arthas
- 运维工具:Promethes、
Skywalking
(2)Mysql自带慢日志查询机制
可以在测试环境(正式环境会影响mysql性能),my.cnf中开启慢查询开关。
1.2 sql执行很慢,如何分析
可以采用Mysql自带的分析工具EXPLAIN
- 通过key和key_len检查是否命中了索引
- 通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或者全盘扫描
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
1.3 索引底层
采用B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子节点存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表。
1.4 聚簇索引和非聚簇索引
1、聚簇索引:数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个
聚簇索引选取规则:
(1)如果存在主键,主键就是聚簇索引
(2)如果没有主键,将使用一个唯一索引作为聚簇索引
(3)如果二者都没有,则会在InnoDB中自动生成一个rowid作为隐藏的聚簇索引
2、非聚簇索引:数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个
3、回表查询
例如:select * from user where name=‘Rose’
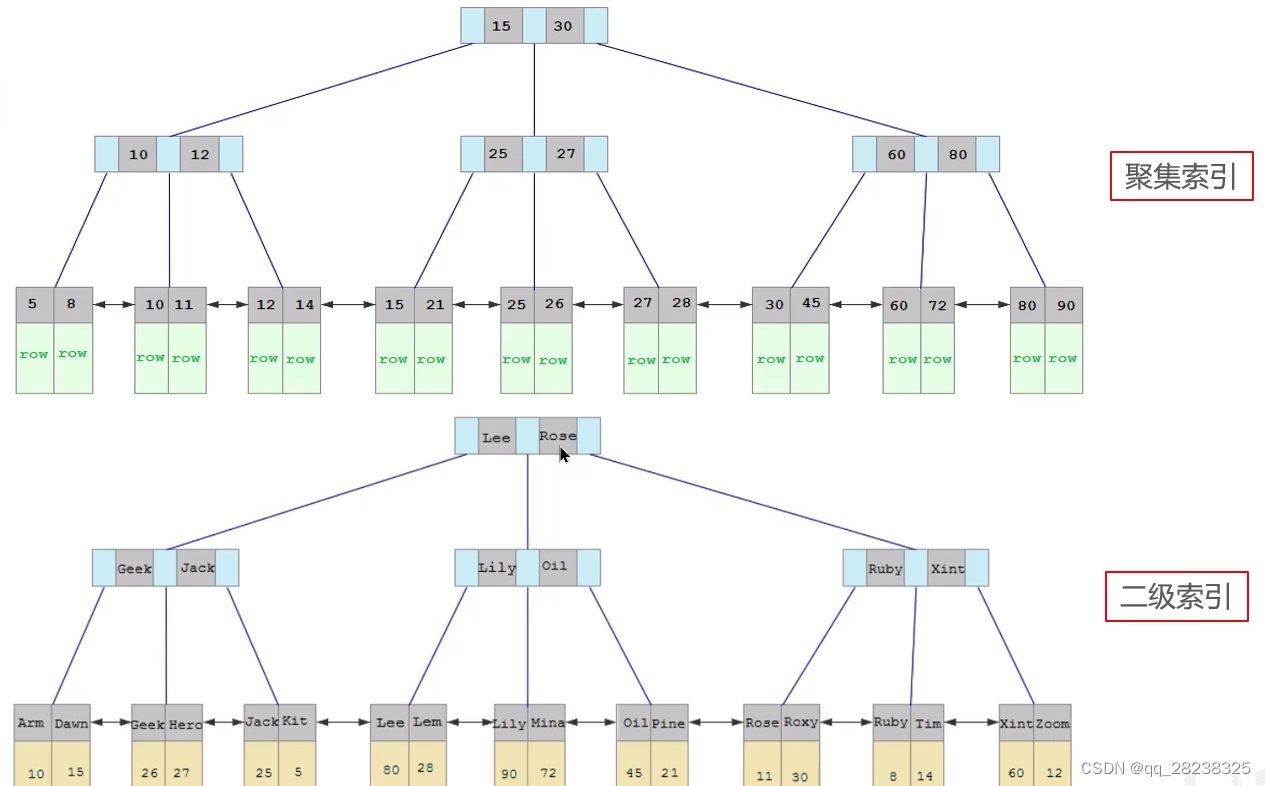
name作为索引首先会查找二级索引对应的主键,然后在根据聚簇索引查找对应数据,这个操作就叫做回表
1.5 覆盖索引、超大分页优化
覆盖索引
覆盖索引真正意义上利用了聚簇索引和非聚簇索引的属性,如下图

Mysql超大分页处理
问题:在数据量较大时,limit分页查询,需要对数据进行排序,效率低
假设取第一百万条到一百万零十条的数据。那么MySQL需要排序前一百万零十条数据,然后舍弃前一百万条。所以性能很低
优化思路:可以通过覆盖查询和子查询来提高效率。
select *
from User_table a,
(select id from User_table order by id limit 1000000,10)b
where a.id = b.id
1.6 索引创建的原则
- 主键索引
- 唯一索引
- 符合索引(根据自己业务创建)
1、针对数据量较大,且查询比较频繁的表添加索引。
单标超过10万数据
2、针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3、尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引查询效率越高。
4、如果是字符串类型的字段,字段长度较长,可以针对字段的特点,建立前缀索引。
5、尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6、要控制索引的数量
7、如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
1.7 什么情况下索引会失效
假如有如下索引(索引失效一般指的是组合索引失效)
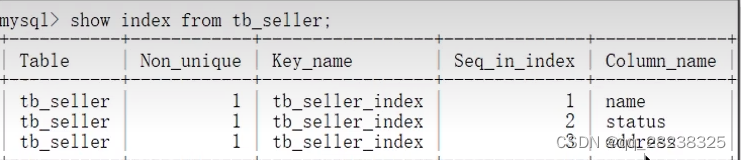
以下是正常走索引的情况:

1、违法最左前缀法则
1)索引失效一般有两种
- 直接跳过第一个索引,那么索引直接失效
- 跳过中间索引,那么只有前面的索引成功,后面全都失效,具体可以跟正常情况下索引长度(key_len)比较

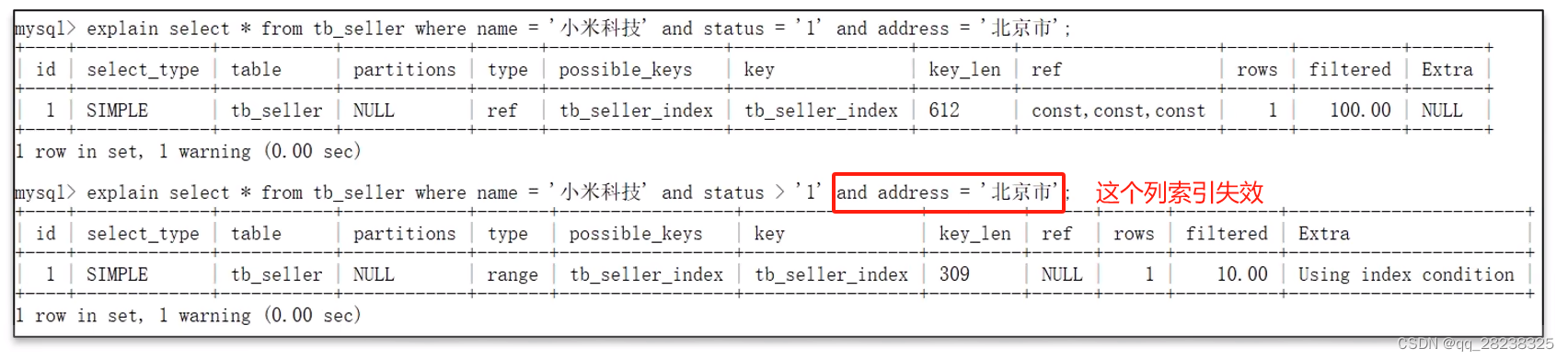
2、范围查询右边的列,索引会失效
1)如下图,中间的字段使用了范围查询,那么会导致其后的复合索引列失效
3、不要在索引列上进行运算操作,否则索引失效

4、字符串不加单引号,造成索引失效(因为要做类型转换)
1)如下,第二行操作,status列要做类型转换,所以索引失效,具体可以对比正常情况下索引长度确定

5、以%开头的Like查询,索引会失效。(%在后会走索引下推,索引不会失效)

二、事务
2.1 事务的特性
- 原子性(
Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。 - 一致性(
Consistency):事务完成时,必须使所有的数据都保持一致状态。 - 隔离性(
Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。 - 持久性(
Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
2.2 并发事务问题、隔离级别
1、并发事务问题
1)脏读:一个事务读到另一个事务还没有提交的数据
比如事务B执行过程中修改了数据X,在未提交前,事务A读取了X,而事务B却回滚了,这样事务A就形成了脏读。
2)不可重复度:一个事务先后读取同一条记录,但两次读取数据不同
事务A首先读取了一条数据,然后执行逻辑的时候,事务B将这条数据改变了,然后事务A再次读取的时候,发现数据不匹配了,就是所谓的不可重复读了。
3)幻读:一个事务在按照条件查询时,没有对应数据行,但是在插入时,又发现这行数据已经存在。
务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了
2、事务隔离级别
1)Serializable (串行化):最严格的级别,事务串行执行,资源消耗最大;
2)REPEATABLE READ(可重复读) :保证了一个事务不会修改已经由另一个事务读取但未提交(回滚)的数据。避免了“脏读取”和“不可重复读取”的情况,但不能避免“幻读”,但是带来了更多的性能损失。
3)READ COMMITTED (提交读):大多数主流数据库的默认事务等级,保证了一个事务不会读到另一个并行事务已修改但未提交的数据,避免了“脏读取”,但不能避免“幻读”和“不可重复读取”。该级别适用于大多数系统。
4)Read Uncommitted(未提交读) :事务中的修改,即使没有提交,其他事务也可以看得到,会导致“脏读”、“幻读”和“不可重复读取”。
2.3 undo log和redo log区别
未完待续















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









