







文章目录
- 前言
- 一、首先分析网页
- 二、编写代码
- 总结
前言
本次呢我讲俩种方法,一种是单纯的selenium自动化登录,这种方法经测试不太行。因为单纯使用账号密码登录微博现在行不通,还需要手机验证码。另一种是使用selenium加cookie的方法登录,经测试很有效。只需要在第一次使用手机扫码登录后用selenium保存cookie,后续就可以用之前保存的cookie登录微博了。
编写代码
1.分析网页
首先是第一种方法。
还是老套路,右键点击检查,因为selenium操作的是渲染后的网页,所以直接看elements就好了。找到账号、密码和登录对应的标签。
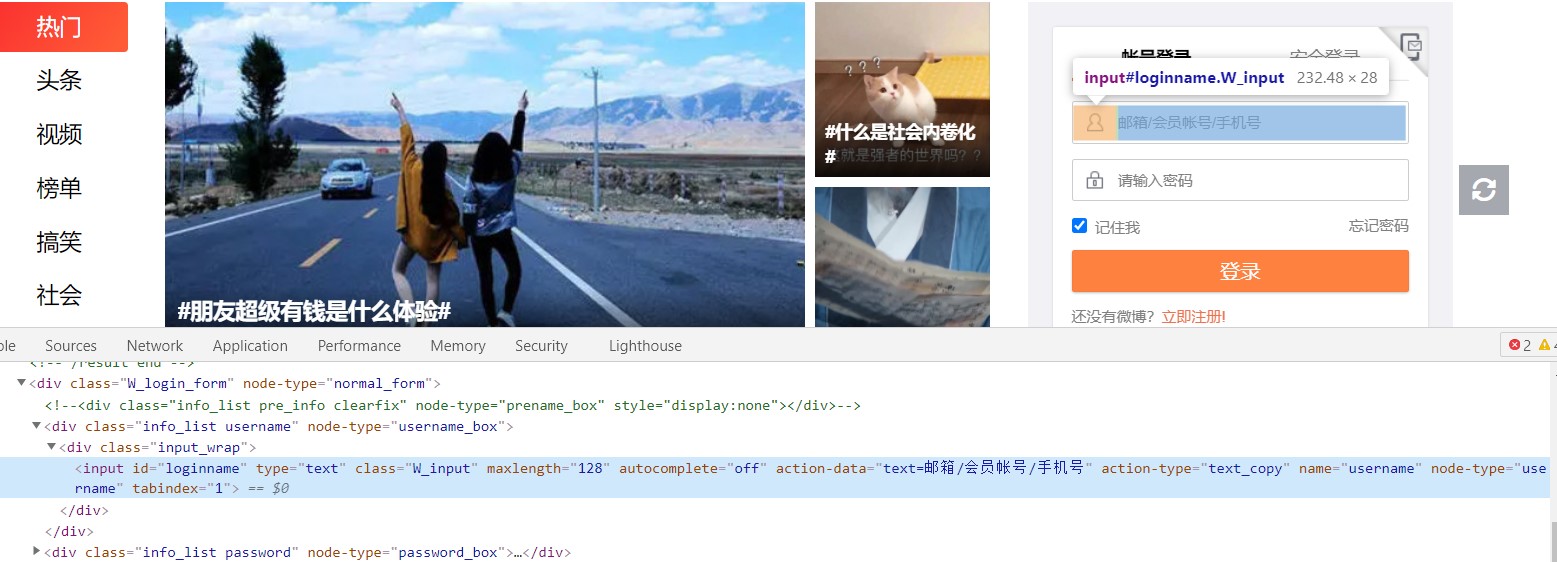
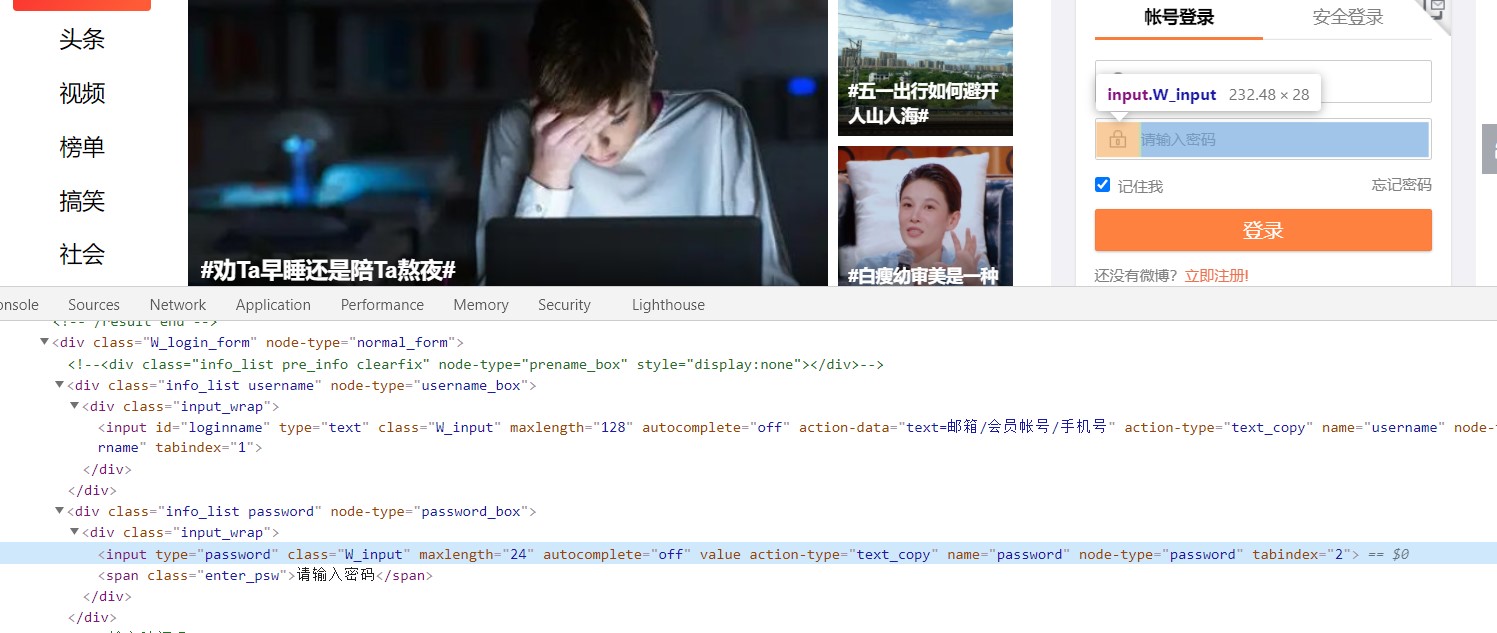
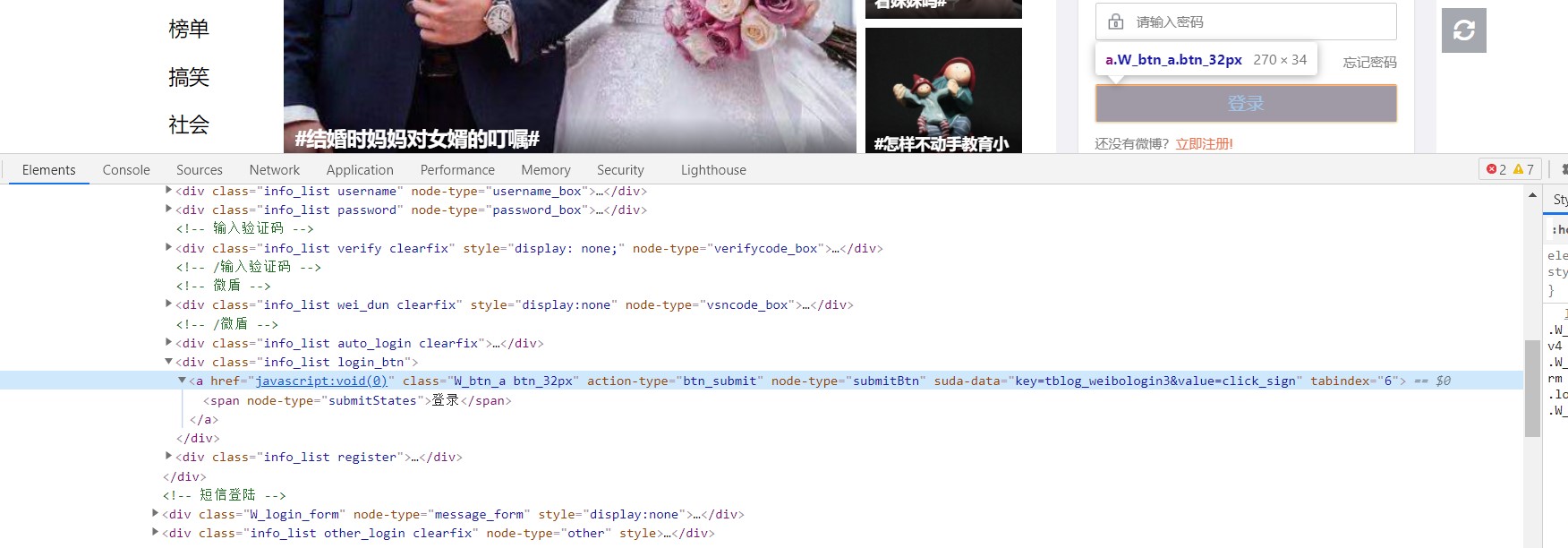
然后写好登录时发现还需要验证码。一样的找到验证码和验证码输入框对应的标签。
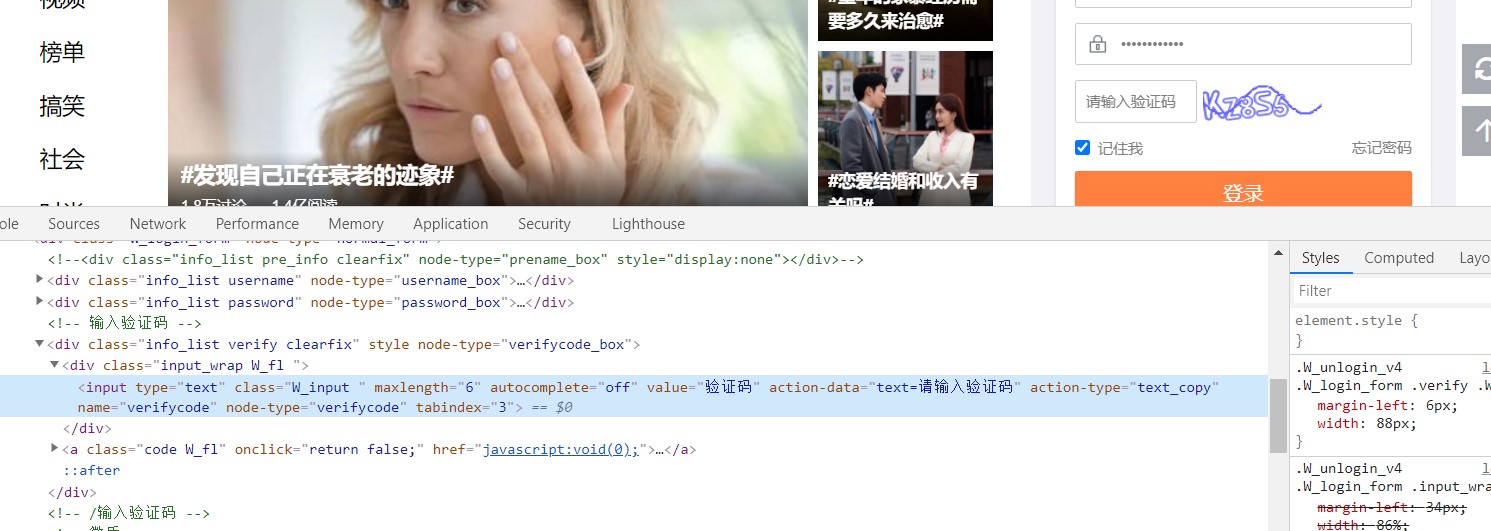
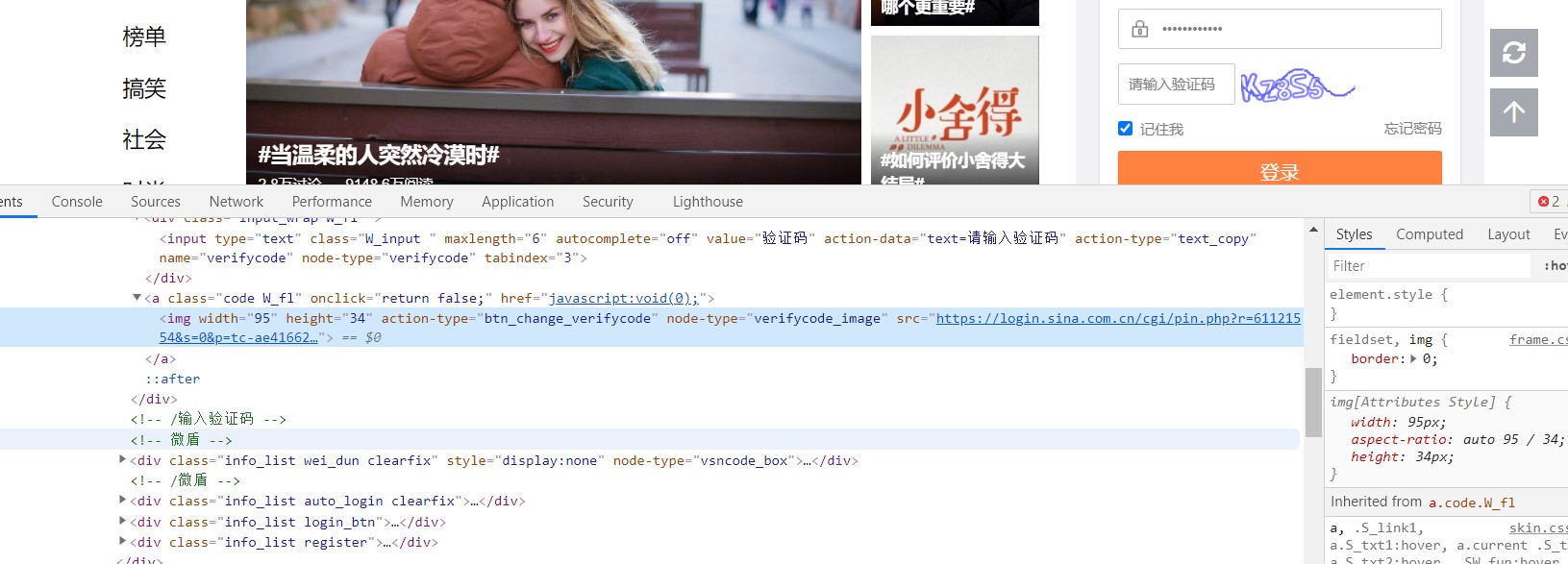
这里的验证码我们可以采用百度免费的ocr接口来识别或者打码平台的接口来识别,或者自己训练一堆验证码,然后用自己的接口来识别。不过一般我们采用别人的接口就可以了,一方面时使用的次数不多,另一方面没这个技术。这里我采用的打码平台,因为百度的接口识别的效果不太好。
第二种方法就更简单了。
就是用selenium打开微博网页后,手机扫码登录,然后selenium获取cookie保存到文件里。然后后面就读取这个文件,selenium携带cookie就可以免账号密码登录微博了。
2.编写代码
第一种
首先是selenium登录网页然后输入账号密码,点击登录后,出现了验证码,利用selenium直接将验证码截图,处理为灰色图片,上传打码平台,将返回的识别结果填入验证码输入框,点击登录的主函数。
def get_html(url,zhanghao,password):
#打开谷歌浏览器
wd = webdriver.Chrome()
#发起请求
wd.get(url)
time.sleep(5)
#输入账号
zhh = wd.find_element_by_xpath('//*[@id="loginname"]')
zhh.send_keys(Keys.CONTROL, 'a')
zhh.send_keys(zhanghao)
time.sleep(1)
#输入密码
pw = wd.find_element_by_xpath('//*[@type="password"]')
pw.send_keys(Keys.CONTROL, 'a')
pw.send_keys(password)
time.sleep(1)
# 点击登录按钮
login_button = wd.find_element_by_xpath('//*[@node-type="normal_form"]//*[@class="info_list login_btn"]')
login_button.click()
time.sleep(1)
try:
x_button = wd.find_element_by_xpath('//*[@class="main_txt"]/a')
x_button.click()
time.sleep(2)
except BaseException:
pass
element = wd.find_element_by_xpath('//*[@node-type="verifycode_image"]') # 定位验证码图片
filename = str(random.random()) + '.png' # 生成随机文件名
element.screenshot(filename)
im = Image.open(filename)
# 转换为灰度图像
im = im.convert('L')
im.save(filename)
# 使用打码平台中提供的方法识别验证码并返回验证码
data = base64_api('mark123','123456',filename,'3')
wd.find_element_by_xpath('//*[@action-data="text=请输入验证码"]').send_keys(data) # 输入验证码
# 点击登录按钮
login_button = wd.find_element_by_xpath('//*[@node-type="normal_form"]//*[@class="info_list login_btn"]')
login_button.click()
time.sleep(1)
time.sleep(1000) # 为了看清登录,等待1000秒
接下来是打码平台的接口,这个要自己去阅读打码平台的API开发文档,如果对啥是API不了解的话可以看本专栏的第一篇文章。简单的API爬虫(和风天气数据获取)
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
总的代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from PIL import Image
import base64
import json
import requests
import random
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
def get_html(url,zhanghao,password):
#打开谷歌浏览器
wd = webdriver.Chrome()
#发起请求
wd.get(url)
time.sleep(5)
#输入账号
zhh = wd.find_element_by_xpath('//*[@id="loginname"]')
zhh.send_keys(Keys.CONTROL, 'a')
zhh.send_keys(zhanghao)
time.sleep(1)
#输入密码
pw = wd.find_element_by_xpath('//*[@type="password"]')
pw.send_keys(Keys.CONTROL, 'a')
pw.send_keys(password)
time.sleep(1)
# 点击登录按钮
login_button = wd.find_element_by_xpath('//*[@node-type="normal_form"]//*[@class="info_list login_btn"]')
login_button.click()
time.sleep(1)
try:
x_button = wd.find_element_by_xpath('//*[@class="main_txt"]/a')
x_button.click()
time.sleep(2)
except BaseException:
pass
element = wd.find_element_by_xpath('//*[@node-type="verifycode_image"]') # 定位验证码图片
filename = str(random.random()) + '.png' # 生成随机文件名
element.screenshot(filename)
im = Image.open(filename)
# 转换为灰度图像
im = im.convert('L')
im.save(filename)
# 使用打码平台中提供的方法识别验证码并返回验证码
data = base64_api('mark123','123456',filename,'3')
wd.find_element_by_xpath('//*[@action-data="text=请输入验证码"]').send_keys(data) # 输入验证码
# 点击登录按钮
login_button = wd.find_element_by_xpath('//*[@node-type="normal_form"]//*[@class="info_list login_btn"]')
login_button.click()
time.sleep(1)
time.sleep(1000) # 为了看清登录,等待1000秒
return 0
if __name__ == '__main__':
url = 'https://weibo.com/'
zhanghao = '你自己的账号'
password = '你自己的密码'
get_html(url,zhanghao,password)
第二种
这个和上面差不多,我就不分析了。
首先是获取并保存cookie的代码。唯一要注意的是其中的time.sleep(15),这个15秒是selenium打开网页后你需要扫码的时长,如果15秒不够你扫码登录的操作的话,可以按自己需求延长。
from selenium import webdriver
from time import sleep
import json
if __name__ == '__main__':
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://weibo.com/login.php')
sleep(6)
# driver.switch_to.frame(driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')) # 切换浏览器标签定位的作用域
driver.find_element_by_xpath('//*[@id="pl_login_form"]/div/div[1]/div/a[2]').click()
sleep(15)
dictCookies = driver.get_cookies() # 获取list的cookies
jsonCookies = json.dumps(dictCookies) # 转换成字符串保存
with open('微博_cookies.txt', 'w') as f:
f.write(jsonCookies)
print('cookies保存成功!')
driver.close()
driver.quit()
然后就是读取保存好的cookie登录微博的代码。
from selenium import webdriver
from time import sleep
import json
def browser_initial():
browser = webdriver.Chrome()
browser.maximize_window()
browser.get(
'https://weibo.com/login.php')
return browser
def log_csdn(browser):
with open('微博_cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
cookie_dict = {
'domain': '.weibo.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
browser.add_cookie(cookie_dict)
sleep(3)
browser.refresh() # 刷新网页,cookies才成功
if __name__ == "__main__":
browser = browser_initial()
log_csdn(browser)
总结
第一种方法是不实用的,第二种方法的cookie具有时效性,失效后就要重新获取更新,也不太实用。听其他大佬说还有其他的接口可以单光使用账号密码登录,但我还未去尝试。
















 8649
8649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











