







案例:商品评论情感分析
学习目标
- 应用朴素贝叶斯API实现商品评论情感分析
1.api介绍
朴素贝叶斯分类
sklearn.naive_bayes.
MultinomialNB(
alpha = 1.0) #
拉普拉斯平滑系数
2.商品评论情感分析
2.1 步骤分析
1)获取数据
2)数据基本处理
2.1) 取出内容列,对数据进行分析
2.2) 判定评判标准
2.3) 选择停用词
2.4) 把内容处理,转化成标准格式
2.5) 统计词的个数
2.6)准备训练集和测试集
3)模型训练
4)模型评估
2.2 代码实现
import pandas as pd
import numpy as np
import jieba
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB1)获取数据
# 加载数据
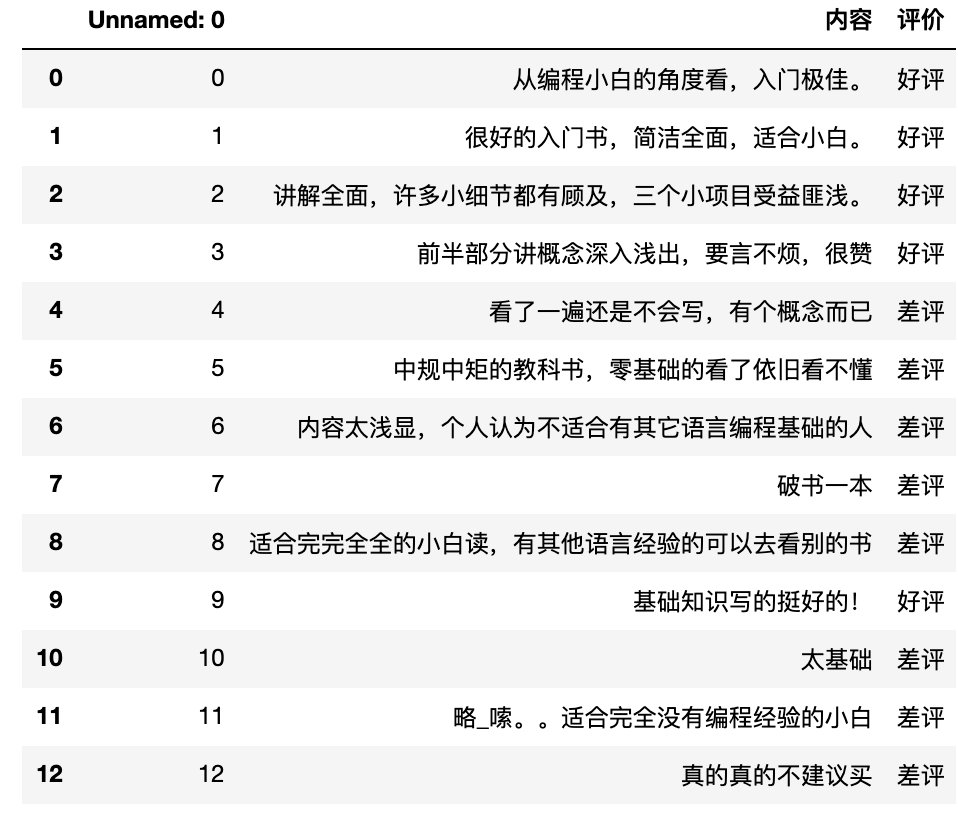
data = pd.read_csv(r"书籍评价.csv", encoding='gbk')
data2)数据基本处理
# 2.1) 取出内容列,对数据进行分析
content = data["内容"]
content.head()
# 2.2) 判定评判标准 -- 1好评;0差评
# data.loc[data.loc[:, '评价'] == "好评", "评论标号"] = 1 # 把好评修改为1
# data.loc[data.loc[:, '评价'] == '差评', '评论标号'] = 0 # 把好评修改为0
df["评论标号"] = np.where(df['评价']=='好评',1,0)
# data.head()
good_or_bad = data['评价'].values # 获取数据
print(good_or_bad)
# ['好评' '好评' '好评' '好评' '差评' '差评' '差评' '差评' '差评' '好评' '差评' '差评' '差评']
# 2.3) 选择停用词
# 加载停用词
stopwords=[]
with open('./data/stopwords.txt','r',encoding='utf-8') as f:
lines=f.readlines()
print(lines)
for tmp in lines:
line=tmp.strip()
# print(line)
stopwords.append(line)
# stopwords # 查看新产生列表
#对停用词表进行去重
stopwords=list(set(stopwords))#去重 列表形式
print(stopwords)
# 2.4) 把“内容”处理,转化成标准格式
comment_list = []
for tmp in content:
print(tmp)
# 对文本数据进行切割
# cut_all 参数默认为 False,所有使用 cut 方法时默认为精确模式
seg_list = jieba.cut(tmp, cut_all=False)
print(seg_list) # <generator object Tokenizer.cut at 0x0000000007CF7DB0>
seg_str = ','.join(seg_list) # 拼接字符串
print(seg_str)
comment_list.append(seg_str) # 目的是转化成列表形式
# print(comment_list) # 查看comment_list列表。
# 2.5) 统计词的个数
# 进行统计词个数
# 实例化对象
# CountVectorizer 类会将文本中的词语转换为词频矩阵
con = CountVectorizer(stop_words=stopwords)
# 进行词数统计
X = con.fit_transform(comment_list) # 它通过 fit_transform 函数计算各个词语出现的次数
name = con.get_feature_names() # 通过 get_feature_names()可获取词袋中所有文本的关键字
print(X.toarray()) # 通过 toarray()可看到词频矩阵的结果
print(name)
# 2.6)准备训练集和测试集
# 准备训练集 这里将文本前10行当做训练集 后3行当做测试集
x_train = X.toarray()[:10, :]
y_train = good_or_bad[:10]
# 准备测试集
x_text = X.toarray()[10:, :]
y_text = good_or_bad[10:]3)模型训练
# 构建贝叶斯算法分类器
mb = MultinomialNB(alpha=1) # alpha 为可选项,默认 1.0,添加拉普拉修/Lidstone 平滑参数
# 训练数据
mb.fit(x_train, y_train)
# 预测数据
y_predict = mb.predict(x_text)
#预测值与真实值展示
print('预测值:',y_predict)
print('真实值:',y_text)4)模型评估
mb.score(x_text, y_text)应用说明:百度AI情感倾向分析


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









