







系列文章目录
【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事
【SQL开发实战技巧】系列(二):简单单表查询
【SQL开发实战技巧】系列(三):SQL排序的那些事
【SQL开发实战技巧】系列(四):从执行计划讨论UNION ALL与空字符串&UNION与OR的使用注意事项
【SQL开发实战技巧】系列(五):从执行计划看IN、EXISTS 和 INNER JOIN效率,我们要分场景不要死记网上结论
【SQL开发实战技巧】系列(六):从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放
【SQL开发实战技巧】系列(七):从有重复数据前提下如何比较出两个表中的差异数据及对应条数聊起
【SQL开发实战技巧】系列(八):聊聊如何插入数据时比约束更灵活的限制数据插入以及怎么一个insert语句同时插入多张表
【SQL开发实战技巧】系列(九):一个update误把其他列数据更新成空了?Merge改写update!给你五种删除重复数据的写法!
【SQL开发实战技巧】系列(十):从拆分字符串、替换字符串以及统计字符串出现次数说起
【SQL开发实战技巧】系列(十一):拿几个案例讲讲translate|regexp_replace|listagg|wmsys.wm_concat|substr|regexp_substr常用函数
【SQL开发实战技巧】系列(十二):三问(如何对字符串字母去重后按字母顺序排列字符串?如何识别哪些字符串中包含数字?如何将分隔数据转换为多值IN列表?)
【SQL开发实战技巧】系列(十三):讨论一下常用聚集函数&通过执行计划看sum()over()对员工工资进行累加
【SQL开发实战技巧】系列(十四):计算消费后的余额&计算银行流水累计和&计算各部门工资排名前三位的员工
【SQL开发实战技巧】系列(十五):查找最值所在行数据信息及快速计算总和百之max/min() keep() over()、fisrt_value、last_value、ratio_to_report
【SQL开发实战技巧】系列(十六):数据仓库中时间类型操作(初级)日、月、年、时、分、秒之差及时间间隔计算
【SQL开发实战技巧】系列(十七):数据仓库中时间类型操作(初级)确定两个日期之间的工作天数、计算—年中周内各日期出现次数、确定当前记录和下一条记录之间相差的天数
【SQL开发实战技巧】系列(十八):数据仓库中时间类型操作(进阶)INTERVAL、EXTRACT以及如何确定一年是否为闰年及周的计算
【SQL开发实战技巧】系列(十九):数据仓库中时间类型操作(进阶)如何一个SQL打印当月或一年的日历?如何确定某月内第一个和最后—个周内某天的日期?
【SQL开发实战技巧】系列(二十):数据仓库中时间类型操作(进阶)获取季度开始结束时间以及如何统计非连续性时间的数据
【SQL开发实战技巧】系列(二十一):数据仓库中时间类型操作(进阶)识别重叠的日期范围,按指定10分钟时间间隔汇总数据
【SQL开发实战技巧】系列(二十二):数仓报表场景☞ 从分析函数效率一定快吗聊一聊结果集分页和隔行抽样实现方式
【SQL开发实战技巧】系列(二十三):数仓报表场景☞ 如何对数据排列组合去重以及通过如何找到包含最大值和最小值的记录这个问题再次用执行计划给你证明分析函数性能不一定高
【SQL开发实战技巧】系列(二十四):数仓报表场景☞通过案例执行计划详解”行转列”,”列转行”是如何实现的
【SQL开发实战技巧】系列(二十五):数仓报表场景☞结果集中的重复数据只显示一次以及计算部门薪资差异高效的写法以及如何对数据进行快速分组
【SQL开发实战技巧】系列(二十六):数仓报表场景☞聊聊ROLLUP、UNION ALL是如何分别做分组合计的以及如何识别哪些行是做汇总的结果行
【SQL开发实战技巧】系列(二十七):数仓报表场景☞通过对移动范围进行聚集来详解分析函数开窗原理以及如何一个SQL打印九九乘法表
【SQL开发实战技巧】系列(二十八):数仓报表场景☞人员分布问题以及不同组(分区)同时聚集如何实现
【SQL开发实战技巧】系列(二十九):数仓报表场景☞简单的树形(分层)查询以及如何确定根节点、分支节点和叶子节点
【SQL开发实战技巧】系列(三十):数仓报表场景☞树形(分层)查询如何排序?以及如何在树形查询中正确的使用where条件
【SQL开发实战技巧】系列(三十一):数仓报表场景☞分层查询如何只查询树形结构某一个分支?如何剪掉一个分支?
【SQL开发实战技巧】系列(三十二):数仓报表场景☞对表中某个字段内的值去重
【SQL开发实战技巧】系列(三十三):数仓报表场景☞从不固定位置提取字符串的元素以及搜索满足字母在前数字在后等条件的数据
【SQL开发实战技巧】系列(三十四):数仓报表场景☞如何对数据分级并行转为列
【SQL开发实战技巧】系列(三十五):数仓报表场景☞根据条件返回不同列的数据以及Left /Full Join注意事项
【SQL开发实战技巧】系列(三十六):数仓报表场景☞整理垃圾数据:查找数据的连续性时间和重叠时间的关系,初始化开始结束时间
【SQL开发实战技巧】系列(三十七):数仓报表场景☞从表内始终只有近两年的数据,要求用两列分别显示其中一年的数据聊行转列隐含信息的重要性
【SQL开发实战技巧】系列(三十八):数仓报表场景☞拆分字符串进行连接
【SQL开发实战技巧】系列(三十九):Oracle12C常用新特性☞新增分页查询
【SQL开发实战技巧】系列(四十):Oracle12C常用新特性☞可以在同样的列(列组合)上创建多个索引以及可以对DDL操作进行日志记录
【SQL开发实战技巧】系列(四十一):Oracle12C常用新特性☞APPROX_COUNT_DISTINCT以及TEMP UNDO(临时undo记录可以存储在一个临时表中)
【SQL开发实战技巧】系列(四十二):Oracle12C常用新特性☞With FUNCTION新特性
前言
本篇文章主要给讲解的Oracle12C+的两个新特性是:12c对With进行加强(plsql_declarations),新增with function,直接在SQL中嵌入PL/SQL对象并运行,优化了SQL engine 和 PL/SQL engine 2种的代码引擎之间的交互。如果包含PL/SQL声明部分的查询不是顶级查询,那么,顶级查询必须包含WITH_PLSQL hint。用案例分析普通function和with function的性能。
【SQL开发实战技巧】这一系列博主当作复习旧知识来进行写作,毕竟SQL开发在数据分析场景非常重要且基础,面试也会经常问SQL开发和调优经验,相信当我写完这一系列文章,也能再有所收获,未来面对SQL面试也能游刃有余~。
With FUNCTION新特性
12c对With进行加强(plsql_declarations),直接在SQL中嵌入PL/SQL对象并运行,优化了SQL engine 和 PL/SQL engine 2种的代码引擎之间的交互,以获得比之前传统的SQL调用函数更少的上下文切换。
这种语法在查询DG备库查询中可以派上用场,在一个STANDBY备库中,我们不能在只读数据库中创建函数,但通过with子句,我们把函数定义在select语句中,就完美规避了这一问题。
案例
创建测试用表:
create table ta(v_name varchar2(30));
insert into ta values('test');
查询表数据:
select * from aa;
V_NAME
-------
test
接下来做如下查询:
- 将dba_objects表owner,object_name字段通过“.”拼接输出
- 通过一个自治事务先delete ta表的数据,再插入一条数据并显示
with
function with_function(v_owner in varchar2,v_name in varchar2)
return varchar2
is
pragma autonomous_transaction;
begin
delete from ta;
insert into ta values ('tt');
commit;
return v_owner || '.' || v_name;
end;
select with_function(owner, object_name)
from dba_objects
where rownum < 5
union
select *
from ta
/
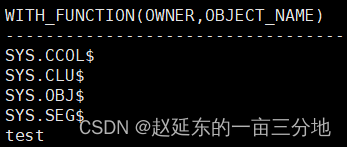
当WITH子句中包含PL/SQL声明时,分号";"不再能用作SQL语句的终止符。如果我们使用它,SQL*Plus会等待更多命令文本输入。在官方文档中,也是使用了分号“;”和反斜杠“/”的组合。从名字解析角度看,WITH子句PL/SQL声明部分定义的函数比当前模式中其他同名对象优先级要高。
在With语句中如果打算从声明部分的函数中调用一个过程,可以在声明部分定义一个过程:
create table TEST_NUL
(
id NUMBER generated by default on null as identity,
v_name VARCHAR2(100)
);
insert into test_nul (ID, V_NAME)
values (1, 'a');
insert into test_nul (ID, V_NAME)
values (2, 'b');
insert into test_nul (ID, V_NAME)
values (1, 'c');
insert into test_nul (ID, V_NAME)
values (3, 'c');
WITH
PROCEDURE with_procedure(p_name IN varchar2 ) IS
BEGIN
DBMS_OUTPUT.put_line('V_name=' || lower(p_name));
END;
FUNCTION with_function(p_name IN varchar2) RETURN varchar2 IS
BEGIN
with_procedure(p_name);
RETURN p_name;
END;
SELECT with_function(v_name) as name
FROM test_nul
/
Name
-------
a
b
c
c
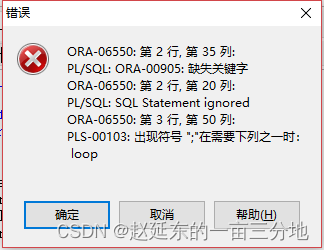
PL/SQL并不支持该特点。如果视图在PL/SQL中使用将会报编译错误,如下所示:
BEGIN
FOR test_cur IN (WITH PROCEDURE with_procedure(p_name IN varchar2) IS BEGIN DBMS_OUTPUT.put_line(
'V_name=' || lower(p_name)); END; FUNCTION with_function(p_name IN varchar2) RETURN varchar2 IS BEGIN with_procedure(p_name); RETURN p_name; END; SELECT with_function(v_name) as
name FROM test_nul
) LOOP
NULL;
END LOOP;
END;
但是在动态sql中却可以绕过这个限定:
DECLARE
l_sql VARCHAR2(2000);
l_cursor SYS_REFCURSOR;
l_value varchar2(50);
BEGIN
l_sql := 'WITH
PROCEDURE with_procedure(p_name IN varchar2 ) IS
BEGIN
DBMS_OUTPUT.put_line(''V_name='' || lower(p_name));
END;
FUNCTION with_function(p_name IN varchar2) RETURN varchar2 IS
BEGIN
with_procedure(p_name);
RETURN p_name;
END;
SELECT with_function(v_name) as name
FROM test_nul
';
OPEN l_cursor FOR l_sql;
FETCH l_cursor INTO l_value;
DBMS_OUTPUT.put_line('l_value=' || l_value);
CLOSE l_cursor;
END;
定义行内PL/SQL代码的原因是为了改善性能。下面创建常规函数来进行比较下性能:
先创建测试用表:
create table test_big(id number,v_name varchar2(30))
begin
for i in 1..1000000
loop
insert into test_big values(i,dbms_random.string('u',10));
end loop;
end ;
接下来创建常规函数:
CREATE OR REPLACE FUNCTION test_fun(p_name IN varchar2) RETURN varchar2 IS
BEGIN
RETURN lower(p_name);
END;
接下来进行比对常规函数和行内函数的效率:
DECLARE
l_time PLS_INTEGER;
l_cpu PLS_INTEGER;
l_sql VARCHAR2(2000);
l_cursor SYS_REFCURSOR;
TYPE t_tab IS TABLE OF varchar2(50);
l_tab t_tab;
BEGIN
l_time := DBMS_UTILITY.get_time;
l_cpu := DBMS_UTILITY.get_cpu_time;
l_sql := 'WITH
FUNCTION with_function(p_name IN varchar2) RETURN varchar2 IS
BEGIN
RETURN p_name;
END;
SELECT with_function(v_name)
FROM test_big';
OPEN l_cursor FOR l_sql;
FETCH l_cursor BULK COLLECT
INTO l_tab;
CLOSE l_cursor;
DBMS_OUTPUT.put_line('WITH_FUNCTION : ' || 'Time=' ||
TO_CHAR(DBMS_UTILITY.get_time -
l_time) || ' hsecs ' ||
'CPU Time=' ||
(DBMS_UTILITY.get_cpu_time - l_cpu) ||
' hsecs ');
l_time := DBMS_UTILITY.get_time;
l_cpu := DBMS_UTILITY.get_cpu_time;
l_sql := 'SELECT test_fun(v_name)
FROM test_big';
OPEN l_cursor FOR l_sql;
FETCH l_cursor BULK COLLECT
INTO l_tab;
CLOSE l_cursor;
DBMS_OUTPUT.put_line('TEST_FUN: ' || 'Time=' ||
TO_CHAR(DBMS_UTILITY.get_time - l_time) ||
' hsecs ' || 'CPU Time=' ||
(DBMS_UTILITY.get_cpu_time - l_cpu) || ' hsecs ');
END;
输出结果如下:
WITH_FUNCTION : Time=52 hsecs CPU Time=52 hsecs
TEST_FUN: Time=178 hsecs CPU Time=175 hsecs
从测试可以看到,行内函数值消耗了普通函数三分之一的时间和CPU。
如果包含PL/SQL声明部分的查询不是顶级查询,那么,顶级查询必须包含WITH_PLSQL hint。没有该hint,语句在编译时会失败,如下所示:
创建测试用表:
create table test_up as select * from test_big where rownum<=1000;
UPDATE Test_Up a
SET a.v_name = (WITH
FUNCTION with_function(p_name IN varchar2) RETURN varchar2 IS
BEGIN
RETURN lower(p_name);
END;
SELECT with_function(a.v_name)
FROM dual);
/
ERROR at line 2:
ORA-32034: unsupported use of WITH clause
加上WITH_PLSQL hint后,语句编译通过运行(但是在plsql软件中还是不行):
UPDATE /*+ WITH_PLSQL */ Test_Up a
SET a.v_name = (WITH
FUNCTION with_function(p_name IN varchar2) RETURN varchar2 IS
BEGIN
RETURN lower(p_name);
END;
SELECT with_function(a.v_name)
FROM dual);
/
1000 rows updated.
Elapsed: 00:00:00.02
10:30:44 用户名: TEST >select * from Test_Up;
ID V_NAME
---------- ------------------------------
1 kpfdhvnago
2 mhzveteksj
3 fgvtzgxflr
对于使用此HINT的场景,官方文档给出下面提示:
If the top-level statement is a SELECT statement, then it must have
either a WITH plsql_declarations clause or the WITH_PLSQL hint.
If the top-level statement is a DELETE, MERGE, INSERT, or UPDATE
statement, then it must have the WITH_PLSQL hint.The WITH_PLSQL hint
only enables you to specify the WITH plsql_declarations clause within
the statement. It is not an optimizer hint
WITH子句中使用函数不会阻止发生DETERMINISTIC优化。
create table test_det(id number,v_name varchar2(20));
insert into test_det values(1,'a');
insert into test_det values(1,'a');
insert into test_det values(1,'a');
insert into test_det values(2,'aa');
insert into test_det values(3,'aaa');
commit;
create sequence TEST_DET_SQ
minvalue 1
maxvalue 9999999999999999999999999999
start with 1
increment by 1
cache 20;
create or replace function testdet(p_name varchar2,p_id number) return varchar2 is
begin
null;
return(upper(p_name)||TEST_DET_SQ.NEXTVAL);
end ;
首先执行下函数:
SQL> select a.*,testdet(a.v_name,a.id) from test_det a;
ID V_NAME TESTDET(A.V_NAME,A.ID)
---------- -------------------- -----------------------------
1 a A1
1 a A2
1 a A3
2 aa AA4
3 aaa AAA5
接下来用DETERMINISTIC优化这个函数后再执行:
SQL> select a.*,testdet(a.v_name,a.id) from test_det a;
ID V_NAME TESTDET(A.V_NAME,A.ID)
---------- -------------------- ---------------------------
1 a A6
1 a A6
1 a A6
2 aa AA7
3 aaa AAA8
之所以出现上面情况是因为这个参数会让function认为当对于相同的输入进来时总是返回相同的输出。所以在相同得输入这种情况时,Oracle不会再执行这个函数而从缓存中获取值。oracle中的内置函数如abs,不管多少次调用,abs(-1)总是返回1。假设在sql中调用这种function,如果存在相同的输入数据,每次调用都要重新执行function的话就会产生性能浪费。当然我们这里虽然输入的值有三条数据是相同的输入,但是里面我们使用了序列递增,所以这类优化对这个场景是错误的。
但是入abs这类函数此参数是有明显优化效果的,如果在with里定义的函数:
with
function with_function(p_name varchar2,p_id number)
return varchar2 DETERMINISTIC
is
begin
DBMS_LOCK.sleep(2);
return(upper(p_name)||TEST_DET_SQ.NEXTVAL);
end ;
select a.*,with_function(a.v_name,a.id)
from test_det a
/
ID V_NAME WITH_FUNCTION(A.V_NAME,A.ID)
---------- -------------------- ------------------------------
1 a A43
1 a A43
1 a A43
2 aa AA44
3 aaa AAA45
Elapsed: 00:00:06.02
从上面查询时间来看,函数被执行了3次,并且调用函数得那一栏也能证明的确执行了3次.说明此参数优化在with中依然可行。(但是在之前12.1测试,只在标量子查询有优化效果)
总结
本篇文章主要给讲解的Oracle12C+的两个新特性是:12c对With进行加强(plsql_declarations),新增with function,直接在SQL中嵌入PL/SQL对象并运行,优化了SQL engine 和 PL/SQL engine 2种的代码引擎之间的交互。如果包含PL/SQL声明部分的查询不是顶级查询,那么,顶级查询必须包含WITH_PLSQL hint。用案例分析普通function和with function的性能。
















 1963
1963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











