






摘要
在本文中,我们通过在相邻层的记忆块之间引入残差连接,提出了一种改进的前馈序列记忆网络(FSMN)体系结构,即Deep-FSMN(DFSMN)。这些残差连接使信息能够跨不同层流动,从而减轻了在构建非常深的结构时的梯度消失问题。结果是,DFSMN显着受益于这些残差连接和深层结构。我们已经比较了在有和没有较低帧率(LFR)的情况下DFSMN与BLSTM在几种大型语音识别任务(包括英语和普通话)上的性能。实验结果表明,DFSMN可以始终以惊人的增益胜过BLSTM,尤其是在使用CD-Phone作为建模单元的LFR训练下。在2000小时的Fisher(FSH)任务中,提出的DFSMN仅通过使用交叉熵损失并使用3-gram语言模型进行解码就可以实现9.4%的字错误率,与BLSTM相比,绝对改善了1.5%。在20000小时的普通话识别任务中,与LFR训练的BLSTM相比,LFR训练的DFSMN可以实现20%以上的相对改进。此外,我们可以轻松地设计DFSMN中记忆块的超前过滤器顺序,以控制实时应用程序的延迟。
1.介绍
最近,深层神经网络已成为大词汇量连续语音识别(LVCSR)系统中的主要声学模型。根据网络的连接方式,存在各种类型的深度神经网络,例如前馈全连接神经网络(FNN),卷积神经网络(CNNs)和循环神经网络( RNN)。与只能学习将固定大小的输入映射为固定大小的输出的FNN相比,RNN可以学习在较长的时间段内对序列数据进行建模并将其存储在网络权重中,然后在序列数据上执行相当复杂的转换。因此,研究人员越来越关注RNN,尤其是长短期记忆网络(LSTM)。广泛观察到,LSTM及其变体[9,10]在各种声学建模任务上可以明显优于FNN。
尽管RNN在理论上很强大,但由于内部循环周期的原因,RNN的学习通常依赖于所谓的基于时间的反向传播(BPTT)。BPTT大大增加了学习的计算复杂度,甚至更糟的是,它可能会在学习中引起许多问题,例如梯度消失和爆炸。作为替代方案,已经提出了一些前馈体系结构来对长期依赖性进行建模。一个简单的尝试就是所谓的unfolded RNN,其中RNN在一定时刻下在时间上展开。展开的RNN仅需要与标准FNN相当的训练时间,同时可以获得比FNN更好的性能。时延神经网络(TDNN)是另一种流行的前馈体系结构,可以有效地建模长时间的时间上下文。
最近,在[17,18]中,我们提出了一种简单的非循环结构,即前馈序列记忆网络(FSMN),它可以有效地对序列数据中的长期依赖性建模,而无需使用任何循环反馈。声学建模和语言建模任务的实验结果表明,FSMN可以明显优于循环神经网络,并且可以更可靠,更快地学习这些模型。此外,在[19,20]中提出了一种变型FSMN体系结构,即紧凑型FSMN(cFSMN),以简化FSMN体系结构并进一步加快学习速度。
在这项工作中,基于先前的FSMN工作和最近关于具有非常深架构的神经网络的工作,我们通过在相邻存层记忆块之间引入残差连接,提出了一种改进的FSMN结构,即Deep-FSMN(DFSMN)。这些残差连接使信息能够跨不同层流动,从而减轻了在构建非常深的结构时的梯度消失问题。此外,考虑到实际应用的需求,我们建议将DFSMN与低帧率(LFR)技术结合起来以加快解码速度,并优化DFSMN拓扑以满足延迟要求。在[19,20]中,先前的FSMN工作是在受欢迎的300小时Switchboard(SWB)任务上进行评估的。在这项工作中,我们尝试评估DFSMN在几个更大的语音识别任务上的性能,包括英语和普通话。首先,在2000小时的英语Fisher(FSH)任务中,与流行的BLSTM相比,具有小得多的模型尺寸的DFSMN可以实现1.5%的词错误率改进。此外,与延迟控制的BLSTM(LCBLSM)相比,在20000小时的普通话任务中,受LFR训练的DFSMN获得了20%以上的相对改进。更重要的是,我们可以轻松地设计DFSMN中记忆块的超前过滤器顺序,以匹配实时应用程序的延迟需求。在我们的实验中,具有5帧延迟的LFR训练DFSMN仍然可以超过具有40帧延迟的LFR训练的LCBLSTM。
2.从FSMN到CFSMN
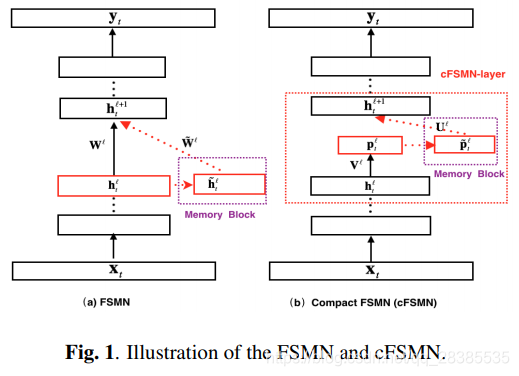
FSMN是在[17,18]中提出的,其灵感来自数字信号处理中的滤波器设计知识,即可以使用高阶有限冲激响应(FIR)滤波器很好地近似任何无限冲激响应(IIR)滤波器。由于RNN中的循环层可以在概念上视为一阶IIR滤波器,因此可以由高阶FIR滤波器精确地对其进行近似。因此,FSMN通过将一些记忆块扩展到隐藏层来扩展标准前馈全连接神经网络,这些记忆块采用FIR滤波器中的抽头延迟线结构。例如,图1(a)显示了一个FSMN,其中一个记忆块被添加到了第
l
l
l个隐藏层中。FSMN中可学习的类似于FIR的记忆块可用于将长上下文信息编码为固定大小的表示形式,这有助于模型捕获长期依赖性。此外,我们可以将多个记忆块添加到深度神经网络的多个隐藏层中,以捕获各种抽象级别的更多上下文信息。在[18]中,根据要使用的编码方法,我们提出了两种版本的FSMN,即标量FSMN(sFSMN)和向量FSMN(vFSMN)。对于vFSMN,记忆块的格式采用以下形式:
h
~
t
l
=
∑
i
=
0
N
1
a
i
l
⊙
h
t
−
i
l
+
∑
j
=
1
N
2
c
j
l
⊙
h
t
+
j
l
(1)
\pmb{\tilde h}^l_t=\sum^{N_1}_{i=0}\pmb{a}^l_i\odot \pmb{h}^l_{t-i}+\sum^{N_2}_{j=1}\pmb{c}^l_j\odot \pmb{h}^l_{t+j}\tag{1}
h~h~h~tl=i=0∑N1aaail⊙hhht−il+j=1∑N2cccjl⊙hhht+jl(1)
其中
⊙
\odot
⊙表示两个相等大小的向量的逐元素乘法。
N
1
N_1
N1称为回溯顺序,表示回溯到过去的历史项的数量,
N
2
N_2
N2称为超前顺序,表示未来的超前窗口的大小。来自记忆块
h
~
t
l
\pmb{\tilde h}^l_t
h~h~h~tl的输出可以被视为在时刻
t
t
t处的长距离上下文的固定大小的表示。如图1(a)所示,可以与
h
t
l
h^l_t
htl相同的方式将
h
~
t
l
\pmb{\tilde h}^l_t
h~h~h~tl馈入下一个隐藏层。结果是,我们可以如下计算下一个隐藏层中单元的激活:
$
h
t
l
+
1
=
f
(
W
l
h
t
l
+
W
~
l
h
~
t
l
+
b
l
)
(2)
\pmb{h}^{l+1}_t=f(\pmb{W}^l\pmb{h}^l_t+\pmb{\tilde W}^l\pmb{\tilde h}^l_t+\pmb{b}^l)\tag{2}
hhhtl+1=f(WWWlhhhtl+W~W~W~lh~h~h~tl+bbbl)(2)
考虑到记忆块引入了额外参数,在[19]中提出了一种变型FSMN体系结构,即紧凑型FSMN(cFSMN),以简化FSMN体系结构并加快学习速度。如图1(b)所示,它是第
l
l
l层中具有单个cFSMN层的cFSMN。与标准FSMN相比,cFSMN可以看作是在非线性隐藏层之后插入一个较小的线性映射层,并将记忆块添加到线性银蛇层而不是隐藏层。cFSMN中记忆块的编码形式采用以下形式:
p
~
t
l
=
p
t
l
+
∑
i
=
0
N
1
a
i
l
⊙
p
t
−
i
l
+
∑
j
=
1
N
2
c
j
l
⊙
p
t
+
j
l
.
(3)
\pmb{\tilde p}^l_t=\pmb{p}^l_t+\sum^{N_1}_{i=0}\pmb{a}^l_i\odot \pmb{p}^l_{t-i}+\sum^{N_2}_{j=1}\pmb{c}^l_j\odot \pmb{p}^l_{t+j}.\tag{3}
p~p~p~tl=ppptl+i=0∑N1aaail⊙pppt−il+j=1∑N2cccjl⊙pppt+jl.(3)
此外,我们可以如下计算下一个隐藏层中单元的激活:
$
h
t
l
+
1
=
f
(
U
l
p
~
t
l
+
b
l
+
1
)
(4)
\pmb{h}^{l+1}_t=f(\pmb{U}^l\pmb{\tilde p}^l_t+\pmb{b}^{l+1})\tag{4}
hhhtl+1=f(UUUlp~p~p~tl+bbbl+1)(4)
如图1所示,FSMN和cFSMN都保留为纯前馈结构,可以使用基于mini-batch的随机梯度下降(SGD)的标准反向传播(BP)来有效地学习。
3.DEEP-FSMN
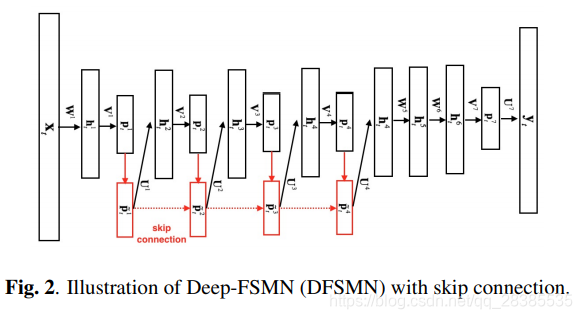
在先前的cFSMN中,如第2节所述,通过使用权重矩阵低秩分解将标准隐藏层分解为两层。因此,对于具有4个cFSMN层和2个DNN层的cFSMN,层的总数为12。如果我们想通过直接添加更多cFSMN层来训练更深的cFSMN,它将遭受梯度消失的困扰。受最近通过残差连接训练非常深的神经体系结构(例如ResNET或highway网络)的启发,我们提出了一种改进的FSMN体系结构,即Deep-FSMN(DFSMN)。
DFSMN的体系结构如图2所示。我们在标准cFSMN的记忆块之间添加了一些残差连接,其中较低层记忆块的输出可以直接流向较高层记忆块。在反向传播期间,高层的梯度也可以直接分配给较低的层,这有助于克服梯度消失的问题。DFSMN中记忆块的格式采用以下形式:
p
~
t
l
=
H
(
p
t
l
−
1
)
+
p
t
l
+
∑
i
=
0
N
1
l
a
i
l
⊙
p
t
−
s
1
∗
i
l
+
∑
j
=
1
N
2
l
c
j
l
⊙
p
t
+
s
2
∗
j
l
.
(5)
\pmb{\tilde p}^l_t=\mathcal H(\pmb{p}^{l-1}_t)+\pmb{p}^l_t+\sum^{N^l_1}_{i=0}\pmb{a}^l_i\odot \pmb{p}^l_{t-s_1*i}+\sum^{N^l_2}_{j=1}\pmb{c}^l_j\odot \pmb{p}^l_{t+s_2*j}.\tag{5}
p~p~p~tl=H(ppptl−1)+ppptl+i=0∑N1laaail⊙pppt−s1∗il+j=1∑N2lcccjl⊙pppt+s2∗jl.(5)
其中,
p
t
l
=
V
l
h
t
l
+
b
l
\pmb{p}^l_t=\pmb{V}^l\pmb{h}^l_t+\pmb{b}^l
ppptl=VVVlhhhtl+bbbl表示第l个映射层的线性输出。
p
~
t
l
\pmb{\tilde p}^l_t
p~p~p~tl表示第
l
l
l个记忆块的输出。
N
1
l
N^l_1
N1l和
N
2
l
N^l_2
N2l分别表示第l个记忆块的回溯顺序和超前顺序。
H
(
⋅
)
\mathcal H(·)
H(⋅)表示记忆块内的残差连接,可以是任何线性或非线性变换。例如,如果记忆块的尺寸相同,我们可以使用恒等映射,如下所示:
p
t
l
−
1
=
H
(
p
t
l
−
1
)
(6)
\pmb{p}^{l-1}_t=\mathcal H(\pmb{p}^{l-1}_t)\tag{6}
ppptl−1=H(ppptl−1)(6)
在这项工作中,我们将恒等映射用于所有实验。
4.实验
在本节中,我们评估具有低帧率(LFR)的所提出的DFSMN在几种大型词汇语音识别任务(包括英语和普通话)上的性能。
4.1 英语识别任务
对于英语识别任务,我们使用标准的Fisher(FSH)任务。训练集包含来自Switchboard(SWB)和Fisher(FSH)的大约2000个小时的数据。根据标准NIST 2000 Hub5评估集(包含1831条语音)的Switchboard部分上的单词错误率(WER)进行评估,表示为Hub5e00。使用固定时间为10ms的25ms汉明窗分析以8kHz采样的输入语音。我们计算了72维滤波器组(FBK)特征,其中包括以mel尺度分布的24个对数能量系数,以及它们的一阶和二阶时间导数。在此任务中的所有实验中,我们都使用三元语言模型(3-gram LM),该模型在SWB转录本中的300万个单词和费舍尔英语第1部分转录本中的1100万个单词上进行了训练。
对于混合DNN-HMM baseline系统,我们遵循[29]中所述的相同训练过程,使用从MLE训练后的GMM-HMMbaseline系统获得的对齐标签来训练传统的上下文相关的DNN-HMM。DNN包含6个隐藏层,每层包含2,048个线性单位(ReLU)。输入是具有
15
(
7
+
1
+
7
)
15(7+1+7)
15(7+1+7)上下文窗口大小的堆叠FBK特征。对于混合BLSTM-HMM baseline系统,我们已经按照[8]中的相同配置训练了一个深度BLSTM。BLSTM由三个BLSTM层组成(每个方向1024个记忆单元),每个BLSTM层后面是512个单元的低秩线性循环映射层。对于基于cFSMN的系统,我们已经训练了cFSMN,其架构为
3
∗
72
−
4
×
[
2048
−
512
(
20
,
20
)
]
−
3
×
2048
−
512
−
9004
3*72-4×[2048-512(20,20)]-3×2048-512-9004
3∗72−4×[2048−512(20,20)]−3×2048−512−9004。输入是上下文窗口为
3
(
1
+
1
+
1
)
3(1+1+1)
3(1+1+1)的72维FBK特征。cFSMN包括4个cFSMN层,3个ReLU DNN隐藏层和一个线性映射层。
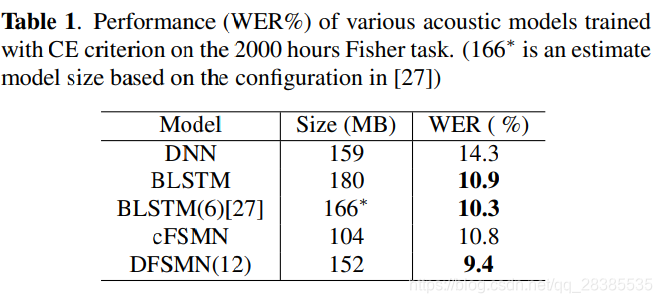
在8个GPU上使用BMUF优化方法,并以帧级交叉熵损失对所有模型进行训练。初始学习率为0.00001,动量保持为0.9。对于DNN和cFSMN,将最小批量设置为4096。使用具有16个序列的最小批量的标准全序列BPTT训练BLSTM模型。baseline模型的性能如表1所示。
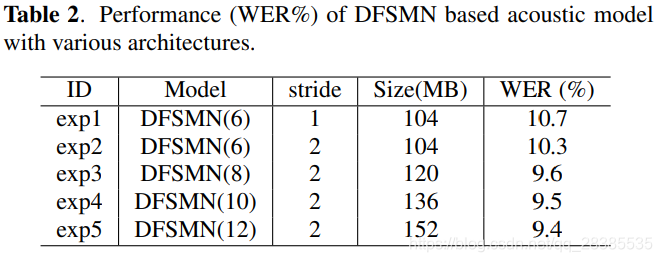
我们已经训练了具有各种架构的DFSMN,可以将其表示为
3
∗
72
−
N
f
×
[
2048
−
512
(
N
1
;
N
2
;
s
1
;
s
2
)
]
−
N
d
×
2048
−
512
−
9004
3*72-N_f×[2048-512(N_1;N_2;s_1;s_2)]-N_d×2048-512-9004
3∗72−Nf×[2048−512(N1;N2;s1;s2)]−Nd×2048−512−9004。
N
f
N_f
Nf和
N
d
N_d
Nd分别是cFSMN层和ReLU DNN层的数量。在这些实验中,
N
1
=
20
N_1=20
N1=20,
N
2
=
20
N_2=20
N2=20,
N
d
=
3
N_d=3
Nd=3保持固定。在第一个实验中,我们研究了cFSMN层数和步幅大小对最终语音识别性能的影响。我们已经用6,8,10和12个cFSMN层训练了cFSMN。表2列出了详细的体系结构和实验结果。这里,DFSMN(6)表示DFSMN的
N
f
N_f
Nf为6。exp1和exp2的结果表明对记忆块使用跨步长的优势。从exp2到exp5,我们可以使用更深的体系结构来实现更好的性能改进。
在表1中,我们总结了在2000小时任务中各种系统的实验结果。我们的BLSTM实施实现了10.9%的WER,与baseline DNN系统相比,相对改善了23.8%。为了进行比较,[27]中训练好的具有六个隐藏层(每个方向512个单元)的BLSTM通过使用4-gram语言模型进行解码,实现了10.3%的WER。对于所提出的DFSMN,仅使用交叉熵损失就可以实现9.4%的WER,而无需任何特征空间或说话人空间自适应技术,这在这项任务中是非常有竞争力的表现。与我们的基准BLSTM系统相比,提出的DFSMN可以在模型尺寸较小的情况下将WER降低1.5%。
4.2 普通话识别任务
对于普通话识别任务,我们已经评估了提出的DFSMN在两项任务(即5000小时任务和20000小时任务)上的性能,这两个任务分别由5000小时和20000小时训练数据组成。5000小时的任务是完整的20000小时的任务的子集。训练数据是从许多领域收集的,例如体育,旅游,游戏,文学等。一个包含约30小时数据的测试集用于评估所有模型的性能。根据字符错误率(CER)进行评估。音频数据的采样率为16kHz。用于所有实验的声学特征是在25ms窗口上以10ms位移计算的80维对数梅尔滤波器组(FBK)特征。
4.2.1 5000h数据
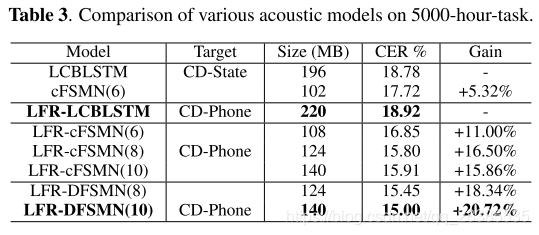
在本实验中,我们以CD-state和CD-Phone为建模单元评估DFSMN的性能。为了进行比较,我们还训练了潜在控制的BLSTM(LCBLSM)作为我们的baseline系统。对于CD-Phone模型,我们使用低帧率(LFR)技术,帧速率为30ms。
对于具有CD-state的传统混合模型,现有的经过交叉熵训练的混合CD-DNN-HMM系统用于重新对齐并生成新的10ms帧级目标标签。HMM由14359个CD-state组成。对于baseline混合CD-LCBLSTM-HMM系统,我们按照[25]中的调优配置来训练
N
c
N_c
Nc和
N
r
N_r
Nr分别为80和40的LCBLSTM。Baseline LCBLSTM包含3个BLSTM层(每个方向500个记忆单元),2个ReLU DNN层(每个层2048个隐藏单元)和softmax输出层。对于基于cFSMN的模型,我们已经训练了cFSMN,其架构为
3
∗
80
−
6
×
[
2048
−
512
(
20
,
20
)
]
−
2
×
2048
−
512
−
14359
3*80-6×[2048-512(20,20)]-2×2048-512-14359
3∗80−6×[2048−512(20,20)]−2×2048−512−14359。输入是80维FBK特征,对于LCBLSTM和cFSMN,上下文窗口分别为1和3。
对于经过LFR训练的带有CD-Phone的混合模型,我们首先将14359 CD状态映射到9841 CD-Phone,然后通过平均3个one-hot目标标签(LFR为30ms)进行下采样,从而生成软LFR目标标签。对于LFR训练的LCBLSTM系统(LFR-LCBLSTM),我们使用与baseline系统类似的模型架构,但
N
c
N_c
Nc和
N
r
N_r
Nr分别为27和13。对于LFR训练的cFSMN模型(表示为LFR-cFSMN),我们训练了具有6,8和10个cFSMN层的cFSMN,分别表示为LFR-cFSMN(6),LFR-cFSMN(8)和LFR-cFSMN(10) 。输入是80维FBK特征,对于LCBLSTM和cFSMN,上下文窗口分别为17和11。对于LFR训练的DFSMN模型(LFR-DFSMN),模型结构表示为
11
∗
80
−
N
f
×
[
2048
−
512
(
N
1
;
N
2
;
s
1
;
s
2
)
]
−
N
d
×
2048
−
512
−
9841
11*80-N_f×[2048-512(N_1; N_2; s_1; s_2)]-N_d×2048-512-9841
11∗80−Nf×[2048−512(N1;N2;s1;s2)]−Nd×2048−512−9841。在这些实验中,我们设置
N
1
=
10
N_1=10
N1=10,
N
2
=
5
N_2=5
N2=5,
s
1
=
2
s_1 = 2
s1=2,
s
2
=
2
s_2 = 2
s2=2,
N
d
=
2
N_d = 2
Nd=2,然后尝试评估
N
f
N_f
Nf为8和10的LFR-DFSMN的性能,记为LFR-DFSMN(8)和LFR-DFSMN(10)。
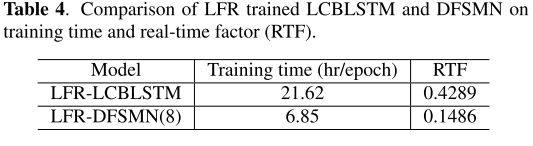
在8个GPU上使用BMUF优化,并以帧级交叉熵损失对所有模型进行训练。我们在表3中列出了所有实验结果以进行比较。与baseline CD-state训练的LCBLSTM相比,cFSMN可以实现5.32%的相对改进。与具有CD-state的cFSMN相比,具有CD-Phone的LFR-cFSMN可以实现约0.9%的绝对CER降低,这表明了建模单元的好处。cFSMN和DFSMN都可以从深层架构中受益,而DFSMN在类似的模型拓扑结构方面可以胜过cFSMN。但是,太深的cFSMN(例如10层)将遭受性能下降,而DFSMN可能会实现持续的改进。此外,提出的LFR-DFSMN可以显着优于LFR-LCBLSTM,相对CER降低约20%。我们可以训练更深的LCBLSTM以获得更好的性能,例如[31]中的Highway-LSTM。但是,如果不增加总参数,则改进是有限的,相对改进仅约2%。在表4中,我们比较了LFR训练的DFSMN和LCBLSTM的训练时间和解码实时因子。结果表明,DFSMN可以在训练和解码实时因子(RTF)方面实现约3倍的加速。
4.2.2 20000h数据
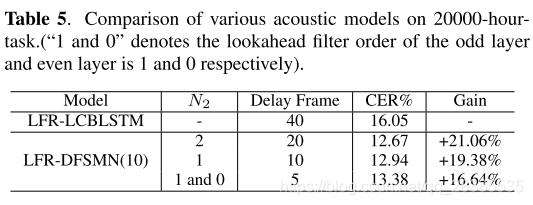
在此任务中,我们尝试比较LFR-LCBLSTM和LFR-DFSMN在包含20000小时训练数据的超大型语料库上的性能。对于LFR-LCBLSTM,我们使用与5000小时的任务相同的配置。对于LFR-DFSMN,我们训练了DFSMN,其模型拓扑为
11
∗
80
−
10
×
[
2048
−
512
(
5
;
N
2
;
2
;
1
)
]
−
2
×
2048
−
512
−
9841
11*80-10×[2048-512(5;N_2;2;1)]-2×2048-512-9841
11∗80−10×[2048−512(5;N2;2;1)]−2×2048−512−9841,表示为LFR-DFSMN(10) 。 我们固定了FSMN层(
N
f
N_f
Nf),DNN层(
N
d
N_d
Nd),回溯滤波器顺序(
N
1
N_1
N1)的数量,并尝试研究超前滤波器顺序(
N
2
N_2
N2)对性能的影响。所有模型都在16个GPU上使用BMUF优化以分布式方式进行训练,并采用帧级交叉熵损失。
对于
N
c
=
27
N_c=27
Nc=27和
N
r
=
13
N_r=13
Nr=13的baseline LFR-LCBLSTM,时间实例的延迟帧数为40。对于LFR-DFSMN,我们可以通过设置回溯滤波器顺序来控制延迟帧数。表5中的实验结果表明,将延迟帧的数量从20减少到5时,我们只会损失大约5%的性能。 结果是,等待时间约为150ms(30ms*5),适用于实时应用。最后,与具有40帧等待时间的LCBLSTM相比,具有20帧等待时间的DFSMN可以实现20%以上的相对改进。

















 4962
4962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









