






 MLP-Mixer是一个基于多层感知器的图像处理架构,不依赖卷积或自注意力机制。它通过两种类型的MLP层——通道混合和token混合,实现了与CNN和Transformer竞争的性能。在大规模数据集上预训练后,MLP-Mixer在图像分类任务上表现出色,同时保持了较低的预训练和推理成本。
MLP-Mixer是一个基于多层感知器的图像处理架构,不依赖卷积或自注意力机制。它通过两种类型的MLP层——通道混合和token混合,实现了与CNN和Transformer竞争的性能。在大规模数据集上预训练后,MLP-Mixer在图像分类任务上表现出色,同时保持了较低的预训练和推理成本。
摘要
卷积神经网络(CNN)是计算机视觉的首选模型。最近,基于注意力的网络(例如Vision Transformer)也变得很流行。在本文中,我们表明,尽管卷积和注意力都足以获得良好的性能,但它们都不是必需的。我们介绍了MLP-Mixer,这是一种完全基于多层感知器(MLP)的体系结构。MLP-Mixer包含两种类型的层:一种将MLP应用于图像单个patches(即“混合”每个位置特征),另一种将MLP应用到多个patches(即“混合”空间信息)。在大型数据集上进行训练或采用现代正则化方案进行训练时,MLP-Mixer在图像分类基准上获得竞争性得分,其预训练和推理成本可与最新模型相媲美。我们希望这些结果能引发更多的研究,超越成熟的CNN和Transformers的领域。
1.介绍
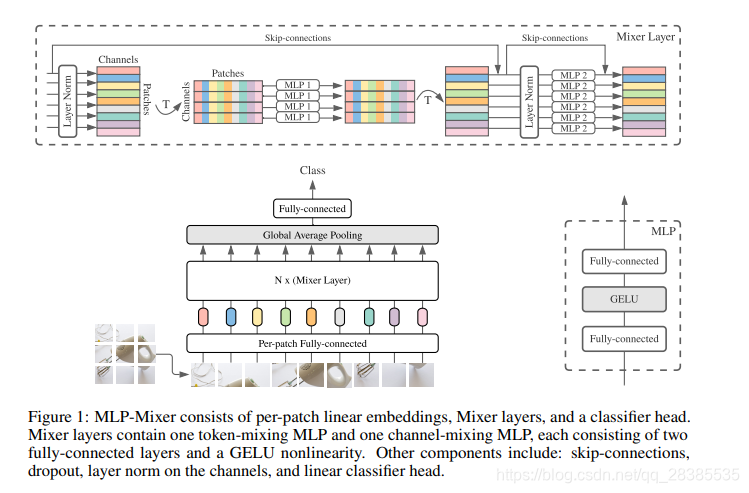
正如计算机视觉的历史所证明的那样,较大的数据集的可用性以及增加的计算能力通常会导致范式转换。虽然卷积神经网络(CNN)已成为计算机视觉的事实上的标准,但最近基于自注意力层的替代工作,Vision Transformer(ViT)却获得了最先进的性能。ViT延续了从模型中消除人工构建的视觉特征和归纳偏差的长期趋势,并进一步依赖于从原始数据中学习。
我们提出了MLP-Mixer体系结构(或简称为“ Mixer”),它是一种竞争性的,但在概念和技术上都很简单的替代方案,它不使用卷积或自注意力。相反,Mixer的体系结构完全基于多层感知器(MLP),这些感知器可重复应用于空间位置或特征通道。Mixer仅依赖于基本矩阵乘法,数据布局的更改(reshapes和transpositions)以及非线性标量。
图1描绘了Mixer的宏观结构。它接受形状为““patches×channels”的一系列线性投影图像表patches(也称为tokens)作为输入,并保持该尺寸。Mixer利用两种类型的MLP层:通道混合MLP和tokens混合MLP。通道混合MLP允许在不同通道之间进行通信。它们独立地对每个token进行操作,并将表的各个行作为输入。tokens混合MLP允许不同空间位置(token)之间的通信;它们在每个通道上独立运行,并以表格的各个列作为输入。这两种类型的层是交错的,以实现两个输入维度的交互。
在极端情况下,我们的体系结构可以看作是一个非常特殊的CNN,它使用1×1卷积进行通道混合,以及使用全视野的单通道深度卷积(token mixing的参数共享)。但是,相反情况并不正确,因为典型的CNN并不是Mixer的特殊情况。此外,卷积比MLP中的普通矩阵乘法更为复杂,因为卷积需要对矩阵乘法进行特殊实现来降低额外的成本。
尽管它很简单,但Mixer还是取得了竞争性的成绩。当在大型数据集(即约1亿张图像)上进行预训练时,就准确性/成本之间的权衡而言,它达到了CNN和Transformers先前宣称的最先进的性能。这包括在ILSVRC2012“ ImageNet”上的top-1验证准确性为87.94%。当使用更适度规模的数据(即,约1-10M图像)进行预训练时,再加上现代的正则化技术,Mixer还将达到更强大的性能。但是,类似于ViT,它与专用的CNN架构略有不同。
2. Mixer Architecture
现代深度视觉架构由将特征(i)在给定的空间位置,(ii)在不同的空间位置之间或同时在两者之间混合的层组成。在CNN中,(ii)由N×N卷积(N>1)和池化层实现。较深层的神经元具有较大的感受野。同时,1×1卷积也执行(i),较大的核同时执行(i)和(ii)。在Vision Transformers和其他基于注意力的体系结构中,自注意力层执行(i)和(ii),MLP层则执行(i)。Mixer体系结构背后的思想是清楚地将按位置(通道混合)操作(i)和跨位置(token混合)操作(ii)分开,且两种操作都通过MLP来实现。
图1总结了该体系结构。混合器将一系列S个不重叠的图像块作为输入,每个块投影到所需的隐藏维度C。这将产生二维实值输入表。如果原始输入图像的分辨率为(H,W),而每个patch的分辨率为
,则patch数为
。所有patches均使用相同的投影矩阵线性投影。混合器由相同大小的多个层组成,每层由两个MLP块组成。第一个是token-mixing MLP block:它作用于
的列(即,它应用于输入表的转置
),映射为
,并在所有列之间共享。第二个是channel-mixing MLP block:它作用于
的行,映射为
,并且在所有行之间共享。每个MLP块都包含两个完全连接的层,以及一个独立地非线性激活应用于其输入数据张量的每一行。混合器层可以编写如下(省略层索引):
此处σ是非线性激活(GELU)。和
分别是token混合MLP和channel混合MLP中的可调隐藏宽度。请注意,
的选择与输入patches的数量无关。因此,与ViT的复杂度是平方的不同,网络的计算复杂度在输入patches的数量上是线性的。由于
与patch大小无关,因此对于典型的CNN,总体复杂度在图像像素数量上是线性的。
如上所述,将相同的channel混合MLP(token混合MLP)应用于的每一行(列)。将通道混合MLP的参数(在每一层内)绑定是自然的选择-它提供了位置不变性 ,是卷积的显着特征。但是,跨通道绑定参数的情况要少得多。例如,在某些CNN中使用的可分离卷积将卷积应用于每个通道,而与其他通道无关。但是,在可分离的卷积中,将不同的卷积核应用于每个通道,这与Mixer中的token混合MLP不同,后者对于所有通道共享同一核(具有完整的感受野)。当增加隐藏维CC或序列长度SS时,参数绑定可防止体系结构增长过快,并节省大量内存。令人惊讶的是,此选择不影响经验性能,请参阅附录A.1。
Mixer中的每个层(初始patch投影层除外)都采用相同大小的输入。这种“各向同性”的设计与其他使用固定宽度的Transformer或其他领域的深层RNN最相似。这与大多数具有金字塔结构的CNN不同:更深的层具有较低的分辨率输入,但具有更多的通道。请注意,尽管这些是典型的设计,但也存在其他组合,例如各向同性ResNet和金字塔形ViT。
除了MLP层,Mixer还使用其他标准体系结构组件:Skip-connections和LayNorm。此外,与ViT不同,Mixer不使用位置嵌入,因为token混合MLP对输入token的顺序很敏感,因此可以学会表示位置。最后,Mixer使用带有全局平均池化层的标准分类头,然后是线性分类器。总的来说,该体系结构可以用JAX / Flax紧凑地编写,其代码在附录E中给出。
E.MLP-Mixer code



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









