






摘要
BERT和Roberta在语义文本相似度(STS)中的句子对回归任务中达到了新的最先好性能。但是,它要求同时将两个句子带入到网络中,这导致大的计算开销,例如,在10,000个句子的集合中查找最相似的句子对需要大约5000万次推理计算(〜65小时)。BERT的构造使其不适合基于语义相似性的搜索以及聚类等无监督任务。
在本论文中,我们提出了 Sentence-BERT(SBERT),用triplet网络结构修改了预训练BERT网络,以获得可以使用余弦相似度比较的语义有意义的句子嵌入。这即减少了BERT和Roberta的计算开销(使用SBERT仅大约5秒),又能同时保持和BERT相当的精度。
我们在普通的STS任务和迁移学习任务上评估了SBERT和SRoBERTa,我们的模型超过了其他最优的获取句子嵌入方法。
1.介绍
在本论文中,我们提出了 Sentence-BERT(SBERT),用triplet网络结构修改了预训练BERT网络,以获得可以使用余弦相似度比较的语义有意义的句子嵌入。这使得BERT能够用于某些之前BERT不适用的新任务。这些任务包括大规模语义相似度比较,聚类和通过语义相似度的信息检索。
BERT在各种句子分类和句子回归任务上达到了最先进的性能。BERT使用多句子编码器:将两个句子传递给transformer网络,以预测目标值。但是,由于存在多种可能的组合,此设置不适合各种句子对回归任务。当在
n
=
10000
n=10000
n=10000句子集合中检索具有最高相似度的句子对时,需要
n
⋅
(
n
−
1
)
/
2
=
49995000
n·(n-1)/ 2=49995000
n⋅(n−1)/2=49995000次推理计算。在V100 GPU上,这需要大约65小时。同样,当检索Quora中超过4000万个现有问题中的哪一个是最相似的问题,需要超过50小时。
解决聚类和语义检索的常见方法是将每个句子映射到向量空间,使得语义相似的句子是彼此靠近的。研究人员已经开始将单个句子输入BERT并得到固定的句子嵌入。最常用的方法是对BERT的输出层平均(称为BERT Embeddings)或通过使用第一字符的输出(
[
C
L
S
]
[CLS]
[CLS]字符)。 正如我们将展示的那样,这种常见的做法产生了相当糟糕的句子嵌入,通常比平均GloVe嵌入更糟糕。
为了减轻这个问题,我们开发了SBERT。Siamese网络架构可以计算出输入句子的固定大小向量。使用余弦相似度,或 Manhatten / Euclidean距离的相似度测量,可以找到语义上类似的句子。这些相似度措施在硬件上非常有效,这允许SBERT用于语义相似性搜索以及聚类。在10,000 个句子集合中找到最相似句子的复杂性从使用BERT的65小时减少到10,000个句子嵌入的计算(〜5秒)和余弦相似度的计算(〜0.01秒)。通过使用优化的索引结构,查找最相似的Quora问题可以从50小时减少到几毫秒。
我们在NLI数据上微调SBERT,最终得到的句子嵌入,要显着优于其他最先进的句子嵌入方法,如InferSent和Universal Sentence Encoder。在七个语义文本相似度(STS)任务中,与InferSent相比,SBERT提高了11.7分。在SentEval上,我们分别提高了2.1和2.6个点。
SBERT还可以适应特定的任务。它在具有挑战性的增强相似性数据集和triplet数据集上达到了新的最先进的性能。
本文以下列方式构建:第3节提出SBERT,第4节在普通的STS任务和Argument Facet Similarity(AFS)语料库上评估了SBERT。第5节在Senteval上评估了SBERT。在第6节中,我们进行消融实验以测试SBERT的不同设计方面。在第7节中,我们与其他最先进的句子嵌入方法相比,比较SBERT句子嵌入的计算效率。
2.相关工作
我们首先介绍BERT,然后,我们再讨论目前最好的句子嵌入方法。
BERT是一个预训练的transformer网络,它在各种NLP任务上达到了新的最先好的结果,包括问答,句子分类和句子对回归。 BERT用于句子对回归的输入包括两个句子,由一个特殊的
[
S
E
P
]
[SEP]
[SEP]字符分开。在12(base-model)或24层(large-model)上使用多头注意力,模型输出传递给简单的回归函数以得到最终标签。使用此配置,BERT在语义文本相似度(STS)基准上达到了新的最优性能。Roberta显示,BERT的性能可以通过对预训练过程的小调整来进一步提高。我们还测试了XLNET,但效果比BERT更差。
BERT网络结构的巨大缺点是没有计算独立的句子嵌入,这使得难以从BERT获得句子嵌入。为了绕过这个限制,研究人员通过将单个句子带入BERT,然后通过平均输出(类似于平均字嵌入)或使用特殊
[
C
L
S
]
[CLS]
[CLS]字符的输出来获得固定大小的矢量。这两个选项也由流行的bert-as-a-service-repository提供。据我们所知,迄今为止还没有工作来评估这些方法是否能获得有用的句子嵌入。
句子嵌入是一个良好的研究区域,目前为止已经具有数十种提出的方法。Skip-Thought训练一个编码器解码器架构,以预测周围的句子。InferSent使用标注的Stanford自然语言推理数据集和MultiGenreNLI数据集的数据,来训练一个siamese BiLSTM网络,以最大池化模型输出。Conneau et al. 表明,Infersent始终优于无监督的方法,如Skip-Thought。 Universal Sentence Encoder 训练了一个transformer网络,并在SNLI训练中增强无监督的学习。Hill et al. (2016) 表明,句子嵌入训练的任务显着影响其质量。先前的工作发现,SNLI数据集适用于训练句子嵌入。Yang et al. (2018) 提出了使用siamese DAN和 siamese transformer网络来训练Reddit中的对话数据,这在STS基准数据集中产生了好的结果。
Humeau et al. (2019) 解决了从BERT处理跨编码器的运行时间开销,并提出一种方法(poly-encoders)来计算
m
m
m个上下文向量之间的分数并使用注意力预先计算候选embeddings。这个想法适用于在更大的集合中找到最高评分句子。然而,PolyEncoders具有缺点,即得分函数不是对称的,并且计算开销太大,因为聚类等使用情况,这需要
O
(
n
2
)
O(n^2)
O(n2)次得分计算。
先前的神经句子嵌入方法从随机初始化开始训练。在本论文中,我们使用预训练的BERT和Roberta网络,只需微调它以产生有用的句子嵌入。这显着降低了所需的训练时间:SBERT可以在不到20分钟内微调结束,同时产生比其他方法更好的句子嵌入。
3.模型
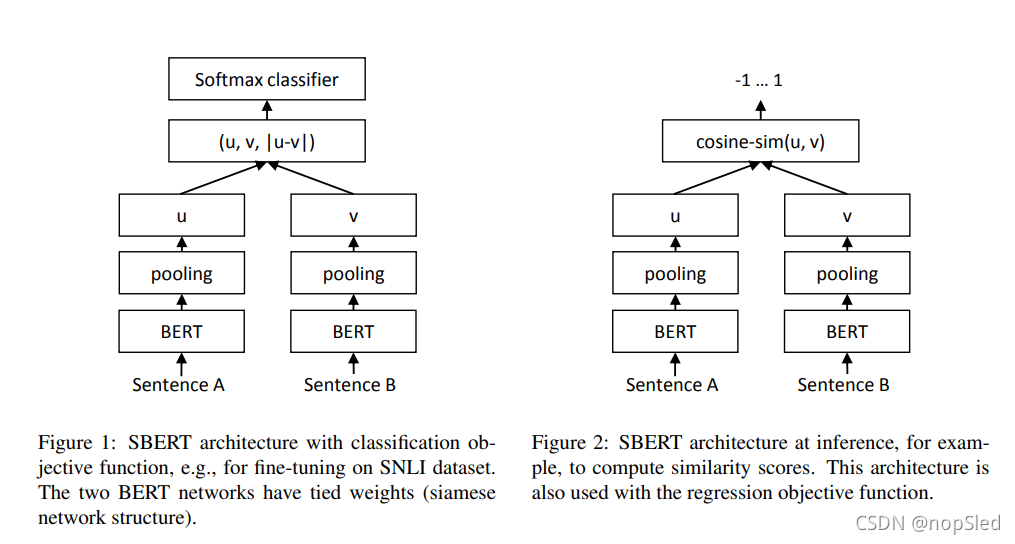
SBERT为BERT / RoBERTa 的输出增加了池化操作,以计算固定的句子嵌入。我们尝试三种池化策略:使用
[
C
L
S
]
[CLS]
[CLS]字符作为输出,计算所有输出矢量的平均值(MEAN策略),计算输出向量的沿句子长度的最大值(MAX策略)。其中默认配置是MEAN。
为了微调Bert / Roberta,我们创建siamese和triplet网络以更新权重,使得产生的句子嵌入是语义有意义的,可以永余弦相似度进行比较。
网络结构取决于可用的训练数据。我们试验了以下结构和目标函数。
Classification Objective Function。我们将句子嵌入
u
u
u和
v
v
v以及逐元素差值
∣
u
−
v
∣
|u-v|
∣u−v∣进行拼接,然后乘以一个可训练的权重
W
t
∈
R
3
n
×
k
W_t∈\mathbb R^{3n×k}
Wt∈R3n×k:
o
=
s
o
f
t
m
a
x
(
W
t
(
u
,
v
,
∣
u
−
v
∣
)
)
o=softmax(W_t(u,v,|u-v|))
o=softmax(Wt(u,v,∣u−v∣))
其中
n
n
n是句子嵌入的维度,
k
k
k是标签数。我们优化交叉熵损失。该结构如图1所示。
Regression Objective Function。计算两个句子嵌入
u
u
u和
v
v
v之间的余弦相似度(图2)。我们使用均方误差损失作为目标函数。
Triplet Objective Function。给定锚点句
a
a
a,正例句子
p
p
p和负例句子
n
n
n,triplet损失调整网络,使得
a
a
a和
p
p
p之间的距离小于
a
a
a和
n
n
n之间的距离。在数学上,我们最小化以下损失函数:
m
a
x
(
∣
∣
s
a
−
s
p
∣
∣
−
∣
∣
s
a
−
s
n
∣
∣
+
ϵ
,
0
)
max(||s_a-s_p||-||s_a-s_n||+\epsilon,0)
max(∣∣sa−sp∣∣−∣∣sa−sn∣∣+ϵ,0)
其中
s
x
s_x
sx表示句子
a
/
n
/
p
a/n/p
a/n/p的句子嵌入,
∣
∣
⋅
∣
∣
||·||
∣∣⋅∣∣距离度量,
ϵ
\epsilon
ϵ表示边界值。边界值
ϵ
\epsilon
ϵ确保
s
p
s_p
sp至少比
s
n
s_n
sn靠近
s
a
s_a
sa的值为
ϵ
\epsilon
ϵ。作为指标,我们使用欧式距离,我们在我们的实验中设置
ϵ
=
1
\epsilon =1
ϵ=1。
3.1 训练细节
我们在SNLI和Multi-Genre NLI数据集的组合中训练SBERT。SNLI是一个570,000句对的集合,并用标签矛contradiction, eintailment和neutral来标注。MultiNLI包含430,000个句子对,涵盖一系列口语和书面文本。我们使用一个3分类softmax-classifier目标函数微调SBERT。我们使用的batch-size大小为16,Adam优化器的学习率为2e-5,以及训练数据的10%步长作为线性学习率warm-up。 我们的默认汇集策略是MEAN。

















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









