






摘要
如今,基于开放领域的对话模型可以基于大规模预训练语言模型的历史上下文来生成可以接受的响应。然而,它们通常直接将对话历史与当前输入拼接,再送入模型,这种方法被称为flat pattern,其忽略了与对话语句相关的动态信息流。在这项工作中,我们提出了一种DialoFlow模型,在该模型中我们引入了一种动态流动机制来建模上下文流,并设计了三个训练目标,通过解决大规模预训练中每个语句所带来的语义影响,来捕获对话语句的动态信息。在multi-reference Reddit数据集和DailyDialog数据集上的实验表明,我们的DialoFlow显着优于DialoGPT在对话生成任务上的表现。此外,我们提出了Flow score,这是一种有效的自动度量方法,用于基于预训练的DialoFlow来评估人机互式对话的质量。代码和预训练的模型是公开可用的(https://github.com/ictnlp/DialoFlow)。
1.介绍
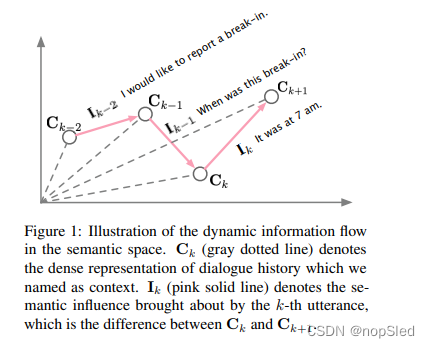
由于大规模预训练方法和大量对话数据收集的快速发展,最近的智能开放式对话机器人已经取得了很大的进步。然而,有效地建模对话历史,对预训练模型仍然具有挑战性。
对话历史建模的大多数工作主要分为两组: 一组工作通常将对话历史拼接到模型输入并预测响应,并称为flat pattern,这种方法在大规模预训练中被广泛采用。然而,Sankar et al. (2019) 表明扁平拼接可能会忽略对话历史中语句的动态信息。另一组工作使用分层建模来编码对话历史,其中每个语句是单独编码的,然后再带入utterance-level编码器,这种方法在编码每个语句时缺乏历史信息,而历史信息对于理解对话语句至关重要。因此,所有上述方法都缺乏在对话历史中建模动态信息。
在这项工作中,受人类认知过程的启发,即人类在继续谈话之前会始终考虑下一个响应所带来的结果或影响,我们提出了通过解决由每一个语句所带来的语义影响来建模对话历史中的动态信息流,并将其称为DialoFlow。如图1所示,我们将不同语句的对话历史的密集表示作为上下文(灰点线),并且将每个语句所带来的语义影响作为上下文转换。特别是,我们的DialoFlow构造了utterance-level历史上下文流的过程。相应地,可以通过两个相邻上下文之间的差异来测量每个话语的语义影响,这将进一步用于引导流式响应生成。
实际上,我们首先使用transformer来编码整个对话以获得密集的上下文表示。然后我们设计一个单向的Flow模块,以捕获话语级的上下文流,并设计三个训练目标来建模上下文流量,并测量由每个语句所带来的语义影响:1)Context Flow Modeling,旨在捕获上下文 流结构。2)Semantic Influence Modeling,旨在测量预测语义的影响。3)Response Generation Modeling,这是在预测的语义影响的指导下生成响应。此外,为了证明在对话过程中建模动态信息流的有效性,我们通过测量语义影响困惑度来提出基于DialoFlow的Flow score,这是针对交互式对话评估的自动无参考的度量指标。
我们首先在大规模的Reddit comments语料中预训练提出的DialoFlow,然后进行对话生成和交互对话质量评估的实验。对于对话生成,与基线DialoGPT相比,DialoFlow在Reddit multi-reference数据集和Daily Dialog数据集上具有显着改进。对于交互对话质量评估,我们所提出的Flow score从11个聊天机器人的2200条人机对话中获得了高chatbot-level correlation(
r
=
0.9
r=0.9
r=0.9)。
我们的贡献总结如下:
- 我们提出了一个新的框架DialoFlow,其通过解决由每个语句所带来的语义影响来构建对话历史中的动态信息流。此外,我们设计了一种基于预训练的DialoFlow进行交互式对话质量评估的自动无参考的度量指标Flow score。
- 实验结果表明,与对话生成任务中DialoGPT的相比,DialoFlow 实现了显着改进,并且 Flow score 显示出具有人类评级的高chatbot-level( r = 0.9 r=0.9 r=0.9)。
2.方法
通过依次解决每个语句所带来的语义影响,所提出的Dialoflow建模了整个对话历史中的动态信息流。
2.1 Model Overview
在详细介绍DialoFlow之前,我们首先定义一些术语。正式地,令
D
=
{
u
1
,
u
2
,
.
.
.
,
u
N
}
\mathcal D=\{u_1,u_2,...,u_N\}
D={u1,u2,...,uN}表示整个对话。并且令每个语句为
u
k
=
{
u
k
1
,
u
k
2
,
.
.
.
.
.
.
,
u
k
T
}
u_k=\{u^1_k,u^2_k,......,u^T_k\}
uk={uk1,uk2,......,ukT},其中
u
k
t
u^t_k
ukt表示第
k
k
k个语句中的第
t
t
t个词。我们进一步将
u
<
k
=
{
u
1
,
u
2
,
.
.
.
,
u
k
−
1
}
u_{<k}=\{u_1,u_2,...,u_{k-1}\}
u<k={u1,u2,...,uk−1}表示为第
k
k
k个语句的对话历史。此外,将第
k
k
k个语句对话历史
u
<
k
u_{<k}
u<k的密集表示被作为上下文
C
k
\textbf C_k
Ck。并且第
(
k
+
1
)
(k+1)
(k+1)个语句的上下文
C
k
+
1
\textbf C_{k+1}
Ck+1和
C
k
\textbf C_k
Ck间的差值可以定义为第
k
k
k个语句的语义影响
I
k
\textbf I_k
Ik,并可以形式为:
I
k
=
C
k
+
1
−
C
k
.
(1)
\textbf I_k=\textbf C_{k+1}-\textbf C_k.\tag{1}
Ik=Ck+1−Ck.(1)
在我们的方法中,DialoFlow首先编码对话历史,并根据所有先前的历史上下文
C
1
,
C
2
,
.
.
.
,
C
k
\textbf C_1,\textbf C_2,...,\textbf C_k
C1,C2,...,Ck预测未来的上下文
C
k
+
1
′
\textbf C'_{k+1}
Ck+1′。然后在响应生成阶段,该模型获取预测目标的语义影响
I
k
′
\textbf I'_k
Ik′,并基于预测的语义影响和历史子句来自回归地生成目标响应
u
k
u_k
uk。具体地,如图2所示,DialoFlow通过在transformer上设计单向流模块来建模上下文流,并且我们引入了三个多任务训练目标来监督上下文流,语义影响和响应生成,这些目标分别被称为:context flow modeling,semantic influence modeling和response generation modeling。
2.2 Model Architecture
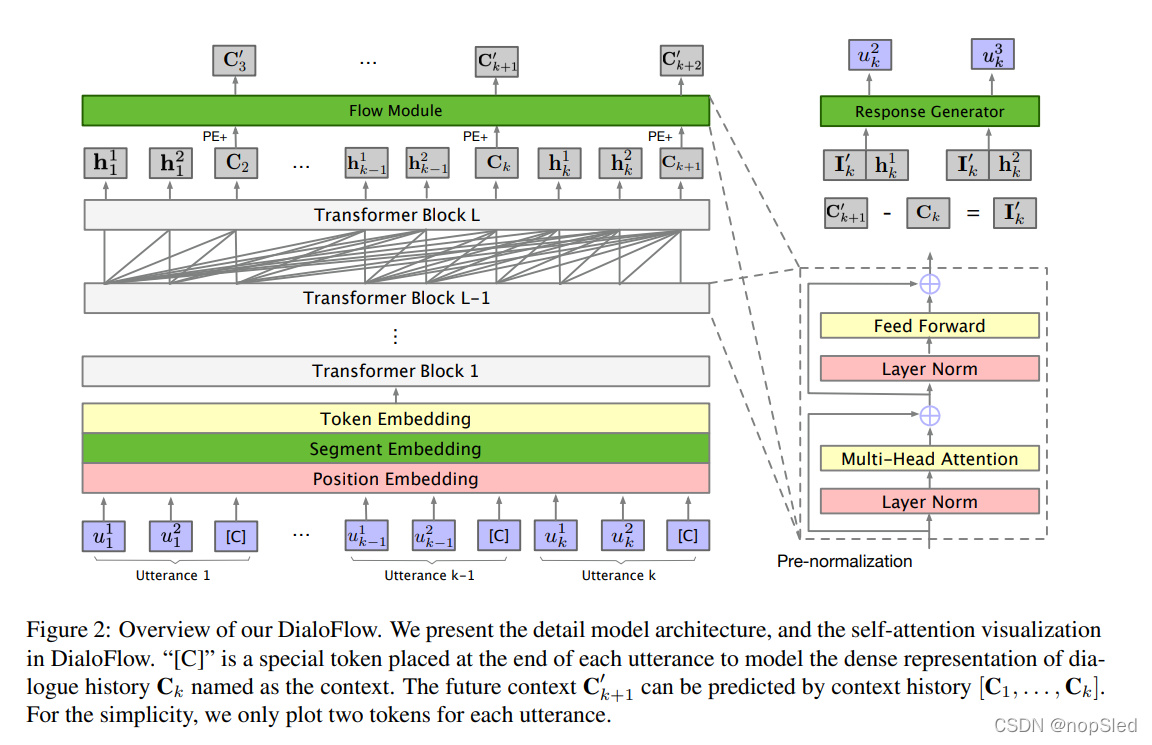
图2展示了DialoFlow的基础架构,该网络由输入嵌入,transformer块,单向流模块和响应生成器组成。
Input Embedding。DialoFlow将字符嵌入,段嵌入和位置嵌入作为模型输入。特别地,我们在每个语句结束时都插入特殊的字符“
[
C
]
[C]
[C]”,该特殊字符“
[
C
]
[C]
[C]”用于捕获对话历史的整体密集表示。为了增强不同说话人的建模,我们利用包含两种类型的段嵌入:“
[
S
p
e
a
k
e
r
1
]
[Speaker1]
[Speaker1]”和“
[
S
p
e
a
k
e
r
2
]
[Speaker2]
[Speaker2]”。
Transformer Block。一个transformer块由以下组件组成:层归一化,多头注意力和全连接层。我们采用GPT-2中使用的 pre-normalization来代替BERT中使用的post-normalization,因为 (Shoeybi et al., 2019) 中的实验表明的,当模型尺寸增加时,post-normalization会导致性能下降,而pre-normalization能稳定模型训练。另外,DialoFlow会保留单向对话编码,并启用对话级的训练而不是上下文响应配置。我们可以在transformer块编码的第
k
k
k个语句中获取历史上下文:
C
k
=
T
r
a
n
s
f
o
r
m
e
r
(
u
<
k
)
,
(2)
\textbf C_k=Transformer(u_{\lt k}),\tag{2}
Ck=Transformer(u<k),(2)
其中
C
k
\textbf C_k
Ck是特殊字符“
[
C
]
[C]
[C]”的隐藏状态,并且输入序列中每个字符
u
k
t
u^t_k
ukt处的隐藏状态被表示为
h
k
t
h^t_k
hkt。
Flow Module。为了捕获对话语句中的动态信息流,我们设计一个流模块以建模上下文更改。流模块的架构与一层transformer块相同。流模块将所有先前上下文
{
C
1
,
C
2
,
.
.
.
,
C
k
}
\{\textbf C_1,\textbf C_2,...,\textbf C_k\}
{C1,C2,...,Ck}作为输入,并预测第
(
k
+
1
)
(k+1)
(k+1)个语句的上下文
C
k
′
+
1
\textbf C'_k+1
Ck′+1:
C
k
+
1
′
=
F
l
o
w
(
C
1
,
C
2
,
.
.
.
,
C
k
)
.
(3)
\textbf C'_{k+1}=Flow(\textbf C_1,\textbf C_2,...,\textbf C_k).\tag{3}
Ck+1′=Flow(C1,C2,...,Ck).(3)
由第
k
k
k个语句所带来预测语义影响可以计算为:
I
k
′
=
C
k
+
1
′
−
C
k
.
(4)
\textbf I'_k=\textbf C'_{k+1}-\textbf C_k.\tag{4}
Ik′=Ck+1′−Ck.(4)
Response Generator。DialoFlow通过预测的语义影响
I
k
′
\textbf I'_k
Ik′来指导生成语句
u
k
u_k
uk。响应生成器包含前馈层和softmax层,以将隐藏状态转换为字符概率分布。当生成第
t
t
t个单词时,响应生成器将预测的语义影响
I
k
′
\textbf I'_k
Ik′和隐藏状态
h
k
t
−
1
h^{t-1}_k
hkt−1作为输入,并输出第
t
t
t个单词的概率分布:
p
(
u
k
t
∣
I
k
′
,
u
<
k
,
u
k
<
t
)
=
s
o
f
t
m
a
x
(
W
1
[
I
k
′
;
h
k
t
−
1
]
+
b
1
)
∈
R
∣
V
∣
,
(5)
p(u^t_k|\textbf I'_k,u_{\lt k},u^{\lt t}_k)=softmax(W_1[\textbf I'_k;\textbf h^{t-1}_k]+b1)\in \mathbb R^{|V|},\tag{5}
p(ukt∣Ik′,u<k,uk<t)=softmax(W1[Ik′;hkt−1]+b1)∈R∣V∣,(5)
其中
∣
V
∣
|V|
∣V∣指词汇大小,
W
1
W_1
W1和
b
1
b_1
b1是可学习参数。
2.3 Training Objectives
与具有上下文-响应对的传统训练方法不同,DialoFlow使用包含
N
N
N个语句的整个对话进行训练。相应地,我们设计了三个训练任务以优化模型:1)上下文流建模,2)语义影响建模和3)响应生成建模。
Context Flow Modeling。为了捕获动态上下文流,DialoFlow基于前面的上下文序列
{
C
1
,
.
.
.
,
C
k
−
1
}
\{\textbf C_1,...,\textbf C_{k-1}\}
{C1,...,Ck−1}预测第
k
k
k个语句的上下文
C
k
′
\textbf C'_k
Ck′。我们最小化预测的上下文
C
k
′
\textbf C'_k
Ck′和真实上下文
C
k
\textbf C_k
Ck之间的L2距离:
L
C
F
M
=
∑
k
=
1
N
∣
∣
C
k
−
C
k
′
∣
∣
2
2
.
(6)
\mathcal L_{CFM}=\sum^N_{k=1}||\textbf C_k-\textbf C'_k||^2_2.\tag{6}
LCFM=k=1∑N∣∣Ck−Ck′∣∣22.(6)
Semantic Influence Modeling。为了强迫通过上下文
C
n
−
1
\textbf C_{n-1}
Cn−1预测的第
n
n
n个语句的语义影响能够有效建模,我们使用预测的语义影响
I
n
′
\textbf I'_n
In′来设计词袋(bag-of-words)损失:
L
S
I
M
=
−
∑
k
=
1
N
∑
t
=
1
T
l
o
g
p
(
u
k
t
∣
I
k
′
)
=
−
∑
k
=
1
N
∑
t
=
1
T
l
o
g
f
u
k
t
,
(7)
\mathcal L_{SIM}=-\sum^N_{k=1}\sum^T_{t=1}log~p(u^t_k|\textbf I'_k)=-\sum^N_{k=1}\sum^T_{t=1}log~f_{u^t_k},\tag{7}
LSIM=−k=1∑Nt=1∑Tlog p(ukt∣Ik′)=−k=1∑Nt=1∑Tlog fukt,(7)
其中,
f
u
k
t
f_{u^t_k}
fukt表示语句
u
k
u_k
uk中第
t
t
t个单词
u
k
t
u^t_k
ukt的估计概率。
f
f
f函数用于以非自回归方式预测语句
u
k
u_k
uk中的单词:
f
=
s
o
f
t
m
a
x
(
W
2
I
k
′
+
b
2
)
∈
R
∣
V
∣
,
(8)
f=softmax(W_2\textbf I'_k+b_2)\in \mathbb R^{|V|},\tag{8}
f=softmax(W2Ik′+b2)∈R∣V∣,(8)
其中
∣
V
∣
|V|
∣V∣指词汇大小,
W
2
W_2
W2和
b
2
b_2
b2是可学习参数。
Response Generation Modeling。预测的语义影响也可以被视为对第
k
k
k个语句的语义期望。我们将预测的语义影响带入响应生成阶段以指导生成。响应生成目标如下:
L
R
G
M
=
−
∑
k
=
1
N
l
o
g
p
(
u
k
∣
I
k
′
,
u
<
k
)
.
(9)
\mathcal L_{RGM}=-\sum^N_{k=1}log~p(u_k|\textbf I'_k,u_{\lt k}).\tag{9}
LRGM=−k=1∑Nlog p(uk∣Ik′,u<k).(9)
DialoFlow的整体训练目标可以如下计算:
L
=
L
C
F
M
+
L
S
I
M
+
L
R
G
M
.
(10)
\mathcal L=\mathcal L_{CFM}+\mathcal L_{SIM}+\mathcal L_{RGM}.\tag{10}
L=LCFM+LSIM+LRGM.(10)
2.4 Flow Score
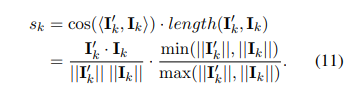
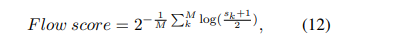


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









