






摘要
构建开放领域聊天机器人是机器学习研究的具有挑战性的部分。虽然先前工作表明,对参数的数量和训练数据的大小进行调整,有助于神经模型的训练,但我们展示了其他部分对高性能的聊天机器人也很重要。良好的对话需要具备像专业健谈人士以无缝方式衔接各轮对话的技能:提供有效的谈话主题并倾听他们的对话伙伴,并适当地展示知识,同理心和个性,同时保持协调的角色。我们表明,在给予适当的训练数据和生成策略的选择时,大规模训练模型可以学习这些技能。我们使用90M,2.7B和9.4B参数型号分别构建这些模型的变体,并使我们的模型和代码公开可用。人类评估显示我们最好的模型在多轮对话上优于现有方法。然后,我们通过分析模型的故障情况来讨论这项工作的局限性。
1.介绍

在这项工作中,我们提供了在人类评估中表现出良好性能的开放领域聊天机器人的构建方法。在大型语料上进行预训练很重要,这已在各种NLP领域和会话agent中展示出来了。除了简单的缩放模型,我们研究的两个主要部分是:
- Blending Skills。在具有所需对话技能的数据上finetune,可以带来大幅度的改进。 我们选择能使模型专注于个性和参与性,知识和同理性的任务,并通过使用最近引入的混合技能谈话(BST)配置来实现大幅提升,该配置通过提供训练数据和初始会话环境(个性和主题)来实现。 使用BST的小型模型可以匹配或优于较大的不使用BST的模型。 虽然BST能够突出期望的技能特征,但我们还显示出这种调整可以最大限度地减少从大型语料获得的不良特征,例如毒性。
- Generation Strategies。解码算法的选择是很重要的,两个具有相同困惑度但不同解码算法的模型可以产生性能差异巨大的结果。尤其是,我们表明机器人的语句长度对于人类的质量判断至关重要:长度太短,则响应会被认为很沉闷且表现出缺乏兴趣,长度太长,则响应会被认为是胡扯且不会倾听。我们的实验结果展示,与以前的工作相反,集束搜索不如采样,并且仔细选择搜索超参能提供很好的结果。
人类评估结果高度依赖于所选择的精确设置。模型性能可能受到评估人员的具体指示的强烈影响,例如是否给定主题,整体对话长度以及人类对话者的选择,这些因素可能很难联合考虑。 我们报告了在短的多轮对话中不使用提示且雇佣众包人群的性能。但是,除此之外,我们认为开源模型是最可靠的方式,可以帮助人们全面了解其功能。因此,我们公开了我们的大规模,最优的开放领域对话agent,包括微调代码,模型权重,以及评估代码,以使我们的实验可重现。在人工评估中,我们最好的模型优于Meena,在成对比较中75%至25%,在人类方面65%至35%(这统计学上都很显着,双尾测试,
p
<
0.01
p<0.01
p<0.01)。
虽然我们的机器人的表现很好,但我们不认为我们已经几乎解决开放领域对话的问题。因此,我们讨论了我们模型的局限性,并初步尝试解决它们。特别是,我们的模型仍然表现出:如果更详细的询问,会缺乏深入的知识;坚持使用简单语言的倾向;重复使用短语的倾向。我们展示了非似然训练以及检索后细化机制是如何解决这些问题。但是,我们对这些方法的初步实验是不完善的。因此,我们讨论了缓减这些问题的未来可能性以及明确地探索和评估的方法。
2.模型架构
我们在这项工作中引入了三种类型的架构:retrieval,generative和retrieve-and-refine模型。这三种模型都使用Transformers作为基础。
2.1 Retriever
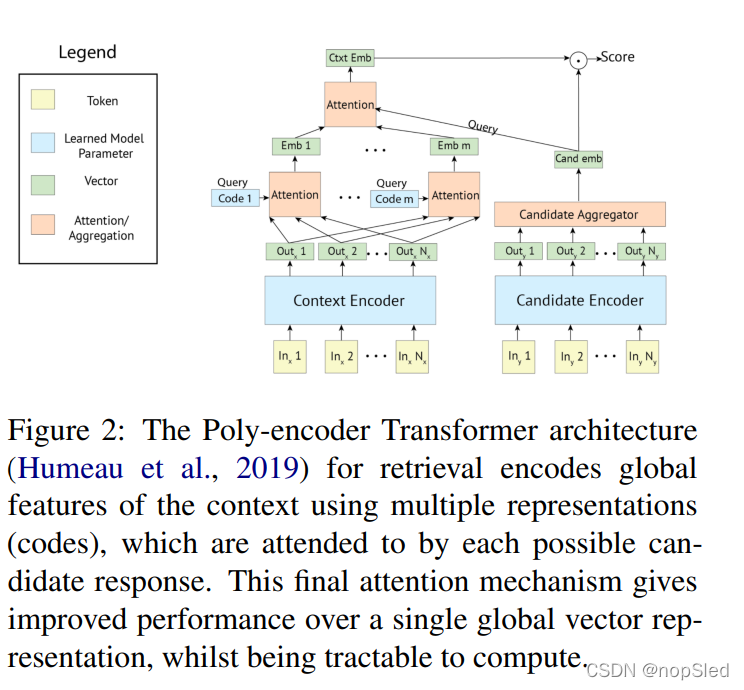
给定一个对话历史(上下文)作为输入,通过与大量候选响应进行评分并输出最高评分,检索系统选择下一个对话语句。通常,所有可能的训练集响应都用作候选集。
我们采用了(Humeau et al., 2019) 中的多编码器架构(poly-encoder)。多编码器使用多个表示(
n
n
n个code,其中N是高参数)对上下文的全局特征进行编码,然后再与每个可能的候选embed进行计算评分,参见图2。使用注意力机制对多个表示进行计算与仅使用单个embed(称为bi-encoders)相比能提升较大性能,同时与直接拼接上下文和候选来作为Transformer的输入(称为cross-encoders)相比,计算更为简单。与其他检索模型相比,多编码器在许多对话任务中具有最新的性能,并且在人类评估方面与ConvAI2比赛任务中获胜的生成模型相比也具有可比的性能。我们考虑两种多编码器尺寸:256M和622M的模型参数,且都使用
n
=
64
n=64
n=64个code。
2.2 Generator
我们使用标准Seq2Seq Transformer架构来生成响应,而不是仅仅从固定集合中检索它们。我们是基于ParlAI版本实现的。我们使用在预训练数据上使用Byte-Level BPE tokenization进行训练,如HuggingFace’s Tokenizers所实现的。
我们考虑三种尺寸的模型: 90M, 2.7B和9.4B的参数。我们的9.4B参数模型具有4层编码器,32层解码器,4096维的embedding,32个注意力头。我们的2.7B参数模型大致与 Adiwardana et al. (2020) 的架构相同,2个编码器层,24个解码器层,2560维的embedding,32个注意力头。
2.3 Retrieve and Refine
已知目前的生成模型具有生成呆板和重复响应问题,这可以通过简单地缩放来改善,但不能彻底解决。此外,已知生成模型的知识是内部固定的,通常无法读取和访问除嵌入其模型参数中的外部知识,这可能是不理想的。尝试缓解这些问题的一种方法是在生成之前结合检索步骤,称为检索再细化模型。我们考虑了两个检索步骤的变体:对话检索和知识检索。
Dialogue Retrieval。我们可以简单地在检索步骤中使用基于检索的对话模型,如2.1节中所述。给定对话历史,首先使用检索模型来生成响应。生成不是向对话伙伴显示检索到的响应,而是被拼接到生成器的输入序列,并用特殊的分隔字符隔离。然后,生成器给出该输入序列修改后的正常输出响应。检索模型生成人工编写的语句,这些语句往往包括比标准生成模型更高质量的语言。因此,如果生成模型能学习何时复制该语句中的元素,它可以提供改进的响应。要构建此类模型,我们将前两部分中考虑的架构作为模型的两个组件。
Knowledge Retrieval。我们还可以使用相同的机制来从大型知识库中检索,而不是检索对话语句。然后,我们以检索到的知识为条件来进行生成,如Wizard of Wikipedia task (Dinan et al., 2019c) 中所提出的模型。因此,我们将此称为 Wizard Generative 模型,因为如何在对话中使用知识的有监督训练信号来自Wizard of Wikipedia任务。我们使用与上述引用中相同的检索系统,在上述工作中,它使用了Wikipedia转储的基于TF-IDF的倒排索引查找,以产生一组初始的知识候选集合。然后,使用Transformer检索模型(与2.1节相同)对候选集合进行排名并选择用于条件生成的单个候选。我们另外训练了基于Transformer的分类器,以选择何时执行检索,因为某些上下文不需要外部知识。我们在微调任务中训练了一个二分类的分类器,这将在下节进行描述。注意到这项工作中的所有其他模型都不会以检索到的知识作为条件。
3.训练目标
3.1 Ranking for Retrieval
为了训练检索模型,我们使用交叉熵损失去最小化logits,其中logits是 y c a n d 1 , . . . , y c a n d n y_{cand_1},...,y_{cand_n} ycand1,...,ycandn,且 y c a n d 1 y_{cand_1} ycand1是正确响应的分数,而其他则是采样的负例。与 Humeau et al. (2019) 类似,在训练期间,我们一个batch中的其他相应进行负例。这允许更快的训练,因为我们可以重用为每个候选相应计算的嵌入,并且还能使用较大的batch大小。在我们的训练中,我们能够使用512条数据的batch。
3.2 Likelihood Training for Generation
要训练生成模型,我们使用标准的最大似然估计(MLE)方法。给定一个数据集
D
=
{
(
x
(
i
)
,
y
(
i
)
)
}
\mathcal D=\{(\textbf x^{(i)},\textbf y^{(i)})\}
D={(x(i),y(i))},我们最小化:
L
M
L
E
(
i
)
(
p
θ
,
x
(
i
)
,
y
(
i
)
)
=
−
∑
t
=
1
∣
y
(
i
)
∣
l
o
g
p
θ
(
y
t
(
i
)
∣
x
(
i
)
,
y
<
t
(
i
)
)
,
\mathcal L_{MLE}^{(i)}(p_{\theta},\textbf x^{(i)},\textbf y^{(i)})=-\sum^{|y^{(i)}|}_{t=1}log~p_{\theta}(y^{(i)}_t|\textbf x^{(i)},y^{(i)}_{\lt t}),
LMLE(i)(pθ,x(i),y(i))=−t=1∑∣y(i)∣log pθ(yt(i)∣x(i),y<t(i)),
其中
x
(
i
)
\textbf x^{(i)}
x(i)是真实的输入上下文,
y
(
i
)
\textbf y^{(i)}
y(i)是真实的预测语句,而
y
t
(
i
)
y^{(i)}_t
yt(i)是
y
(
i
)
y^{(i)}
y(i)的第
t
t
t个字符。
3.3 α-blending for Retrieve and Refine
为了引入retrieve and refine,可以简单地将对话检索响应添加到生成模型的上下文然后训练MLE,不幸的是这种方法并不能产生令人满意的结果。由于真实预测的响应与检索到的响应之间的对应关系不一定清晰,训练的模型通常选择简单地忽略检索到的响应,如Weston et al. (2018) 中所展示的。为了确保生成模型能够使用检索到的响应,可以在 α % α% α%的时间用真实响应替换检索到的响应,这里可以将 α α α视为要调整的超参数。这在检索和生成的系统之间提供了平滑的过渡。对于知识检索,我们发现这个问题较少出现,因为所使用的微调数据集在标准知识和响应之间有明确的对应关系,在这种情况下,我们只需在训练期间使用标准知识。
3.4 Unlikelihood training for generation
修复模型生成失败的一种替代方法是改变损失函数。已经显示非似然损失有助于修复各维度上人类生成和模型生成分布之间的不匹配问题,包括减少重复和减轻过度表示词汇字符的问题。
非似然损失会在每个时刻去惩罚一组字符
C
t
\mathcal C_t
Ct:
L
U
L
(
i
)
(
p
θ
,
C
1
:
T
,
x
,
y
)
=
−
∑
t
=
1
∣
y
∣
∑
y
c
∈
C
t
l
o
g
(
1
−
p
θ
(
y
c
∣
x
,
y
<
t
)
)
,
\mathcal L^{(i)}_{UL}(p_θ,\mathcal C_{1:T},\textbf x,\textbf y)=-\sum^{|y|}_{t=1}\sum_{y_c\in \mathcal C_t}log(1-p_{\theta}(y_c|\textbf x,y_{\lt t})),
LUL(i)(pθ,C1:T,x,y)=−t=1∑∣y∣yc∈Ct∑log(1−pθ(yc∣x,y<t)),
其中
C
t
⊆
V
\mathcal C_t⊆\mathcal V
Ct⊆V是词汇表的子集。然后,非似然训练的整体目标包括混合似然和非似然的损失,
L
U
L
E
(
i
)
=
L
M
L
E
(
i
)
+
α
L
U
L
(
i
)
,
(1)
\mathcal L^{(i)}_{ULE}=\mathcal L^{(i)}_{MLE}+\alpha\mathcal L^{(i)}_{UL},\tag{1}
LULE(i)=LMLE(i)+αLUL(i),(1)
其中
α
∈
R
α∈\mathbb R
α∈R是混合超参数。
似然方法试图建模整体序列概率分布,而无似然方法则校正已知偏差。它通过在每个时刻
t
t
t处计算负候选集合
C
t
\mathcal C_t
Ct来实现这一点;通常,人们预先指定用于生成这种候选的方法,例如已经重复的字符或过度表示的字符。似然方法提高了标准
y
t
(
i
)
y^{(i)}_t
yt(i)的概率,而非似然方法会降低负候选字符
y
c
∈
C
t
y_c∈\mathcal C_t
yc∈Ct的概率。在这项工作中,在训练期间,我们随时统计出现的n-gram分布的出现次数,并且当它们的计数高于标准人工分布的计数时,就将这些n-grams中的字符作为负候选。
4.Decoding
对于生成模型,在推理时间,必须选择一种解码方法来生成以对话上下文作为输入的响应。在这项工作中,我们比较了一些众所周知的方法。
4.1 Beam Search
两个被广泛使用的确定性解码方法是贪心搜索和集束搜索。前者可以被视为后者的特殊情况。贪心搜索在每个步骤中选择最高概率的字符:
y
t
=
a
r
g
m
a
x
p
θ
(
y
t
∣
x
,
y
<
t
)
y_t=argmax~p_{θ}(y_t|x,y_{<t})
yt=argmax pθ(yt∣x,y<t)。集束搜索维护一组具有固定大小的解码序列,称为hypotheses。在每个步骤中,集束搜索通过将来自词汇表中的top-k个字符附加到每个现有hypotheses来形成新的hypotheses,然后评分得到的序列,以选择具有最高的评分序列。
我们在实验中比较了集束搜索的不同beam大小。
4.2 Sampling
一种替代方案是从每个步骤的模型相关分布中进行采样,
y
t
〜
q
(
y
t
∣
x
,
y
<
t
,
p
θ
)
y_t〜q(y_t|x,y_{<t},p_θ)
yt〜q(yt∣x,y<t,pθ)。为了防止采样低概率字符,典型的方法是每个步骤将采样限制到词汇表的子集,并根据那些(重新归一化后的)概率进行采样。
对于采样方法,我们将比较Top-K采样以及样本后排名方法。后者执行采样
S
S
S次,并选择具有最高生成概率的样本。
4.3 Response Length
使用集束搜索进行生成倾向于产生不满足人类语句的短的生成结果。然而,在高质量响应中,更长的语句要好于更短的语句。虽然遵循人类分布可能不会为机器提供最佳性能 ,例如,它可能希望在简洁的方面进行生成以改善人类评估,因为这不太可能暴露其失败 。因此使其响应更长可以具有更多信息,同时减少沉闷。
我们考虑了两个简单的方法来控制模型的响应的长度。
Minimum length。我们考虑的第一种方法是对最小生成长度进行硬约束:终止字符被强制不被生成,直到满足最小序列长度。
Predictive length。第二种方法是基于人类真实对话数据来预测长度。要执行此操作,我们通过分组对话响应的长度(例如
<
10
,
<
20
,
<
30
,
>
30
<10,<20,<30,>30
<10,<20,<30,>30)来训练了一个4类别分类器。 我们使用与此检索模型相同的架构。然后,在测试期间,首先使用分类器来预测下一个响应的长度,并将最小生成长度约束设置为其对应的预测。与先前的方法不同,这导致更自然的可变长度对话响应。 然而,一个缺点是,此过程使我们的系统更加复杂。
4.4 Subsequence Blocking
已知序列生成模型会生成重复子序列,特别是在诸如集束搜索的随机方法中,还会出现在采样方法中。我们实现了n-grams的标准集束阻塞,并使用 n = 3 n=3 n=3。我们考虑在所生成的语句中阻塞重复的n-gram序列,并重复输入序列(来自任何说话人的先前语句)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









