






摘要
最近大型语言模型(LLM)的成功意味着沿通用人工智能迈出了令人印象深刻的一步。他们在按用户指令自动完成任务,并作为大脑进行协调时表现出了有希望的前景。当我们将越来越多的任务交给机器以自动完成时,相关的风险将会产生。 一个大问题出现了:当作为个人助理帮助人类自动完成任务时,我们该如何使机器的行为更加负责呢?在本文中,我们从可行性,完整性和安全性的角度深入探讨了这个问题。具体而言,我们提出了Responsible Task Automation (ResponsibleTA)作为一个基本框架,以促进基于LLM的协调器和执行器之间相互协作来实现任务的自动化,其具有三个授权功能:1)预测执行器命令的可行性;2)验证执行器的完整性;3)增强安全性(例如保护用户隐私)。我们进一步提出并比较了实现前两个功能的两个框架。一种是通过提示工程来利用LLM本身的通用知识,而另一个是采用特定领域的可学习模型。此外,我们引入了一种局部记忆机制,以实现第三个能力。 我们在UI任务自动化上对提出的ResponsibleTA进行了评估,并希望它可以为确保LLM在各种情况下更加负责。研究项目主页位于https://task-automation-research.github.io/responsible_task_automation/。
1.介绍
最近先进的大型语言模型(LLM)在许多现实世界场景中表现出强大的语言理解,推理,生成,泛化和对齐能力。LLM通过扩大深度学习来获取有关开放领域任务的通用知识,这标志着迈向通用人工智能的重要里程碑。除了语言任务之外,LLM还通过与特定领域的模型合作,获得了多模态感知和生成能力。研究人员一直通过将LLM连接到各种特定领域模型或API上来彻底改变任务自动化的领域,其中LLM充当大脑从而作为协调器,而特定领域的模型或API则充当动作执行器。
采用LLM来构建用于自动完成各种任务的通用助手仍处于初步探索阶段。以与UI的交互为例,浏览并与各种网站和应用程序进行交互,以实现其各种意图(例如,搜索,在线购物,设置更改等)几乎是许多人日常生活中必不可少的。这些任务中的一些需要动作的分层结构,其中需要将来自人类任务级目标的高级指令逐步分解为一系列低级指令,以进行实际操作。如此复杂的多步骤任务要求每个步骤都必须按照人类意图进行合理计划和可靠的执行。实际上,在没有训练干预的情况下,这对基于LLM的协调器及其执行器之间的兼容性构成了重大挑战。他们的可靠协作要求基于LLM的协调器对执行器的功能非常熟悉,并一旦执行器的命令完整时,需要重新启动任务执行。现有工作仅仅通过重提示工程来使用模型/API的描述,从而告诉LLM现有执行器的能力。但是,这些描述通常是手动编写的,类似于摘要,这些描述不足以表现除执行器的功能,无法反映LLM的执行完整性。此外,LLM还可能对任务目标和环境的认识不足,从而向执行器发出不合理的指令。随着越来越多的任务被委派给了机器以进行自动化,风险的暴露将会增长,这需要加紧解决可靠性问题。
在这项工作中,我们提出了ResponsibleTA作为基本的多模态框架,以在三个方面使LLM具备可靠的任务自动化能力:1)Feasibility:ResponsibleTA预测由基于LLM的协调器生成的低级命令的可行性,并在执行动作之前将结果返回给LLM。该能力旨在最大程度地减少使执行器执行不可能实现的指令的风险和时间消耗,从而使任务自动化更加可控制和高效。2)Completeness:ResponsibleTA逐步检查低级命令的执行结果,并及时为基于LLM的协调器提供反馈,以使其更合理地重新安排下一步。此功能可以提高任务自动完成的成功率。3)Security:ResponsibleTA使用边缘部署记忆增强了LLM,该记忆允许用户敏感信息在与云部署的LLM的交互过程中隐藏,并且仅在用户的设备上存储和本地使用。 此功能可降低或避免用户在云部署的LLM和占用部署的执行器之间传输用户敏感信息,从而降低用户隐私的泄漏风险。通过这些功能授权给LLM,ResponsibleTA在每个执行步骤之前和之后都实现了自动验证,这不仅提高了成功率,而且还在保证用户安全的情况下提高了的完成效率。
除了ResponsibleTA的框架设计外,我们还研究了在实际应用场景(即UI任务自动化)中,ResponsibleTA的三个核心功能的实现,以作为经验研究。它的目标是根据用户的任务指令自动点击和分类操作自动和目标UI元素进行交互,这在学术界和行业中都有需求。为了可行性和完整性,我们提出并比较了它们实现两个技术框架。 一种是通过提示工程来利用LLM自己的通用知识。另一个是训练特定于领域的模型,专门负责这两个功能,以作为协调器和执行器的外部助手。我们观察到利用LLM本身不如采用领域特定的模型,这表明特定于领域的知识对于提高LLM在任务自动化中的可靠性至关重要。为了安全性,我们引入了局部记忆,并提出了一种机制设计,将其用于赋予ResponsibleTA保证安全的能力。
这项工作的贡献可以总结如下:
- 我们提出了一个基本的多模态框架,称为ResponsibleTA,该框架赋予了LLM进行合理性预测,完整性验证以及安全性保护的能力,以自动且负责的方式完成任务。
- 我们提出并比较了两个技术框架,以实现ResponsibleTA在UI任务自动化场景中可行性预测和完整性验证的功能。一种是利用LLM本身的内部知识,而另一个是将特定于领域的模型作为外部助手进行训练。
- 我们介绍了一种局部记忆机制,以赋予对用户隐私保护的安全保护能力,并在某些有代表性的实际情况下展示其有效性。
2.相关工作
2.1 Development of Large Language Models
从语言模型BERT开始,预训练-微调方案是许多自然语言处理(NLP)和计算机视觉(CV)问题的常见解决方法。通过将数据和模型提高到更大的规模,GPT-3证明了LLM可以获得上下文学习的能力,其中LLM可以在仅给定一些示例作为提示时,就可以快速适应一个新的任务。此外,InstructGPT使用人类演示数据集微调GPT-3可以使LLM遵循用户的意图。最近,ChatGPT和GPT-4在基于用户问题生成完整答案方面表现出了出色的能力。考虑到这些LLM仅处理语言token,Kosmos-1将其训练设置扩展到图像文本数据,并显示了视觉问答和多模态对话的能力。同时,还有同时代的其他LLM,例如PaLM和PaLM-E,以及诸如LLaMA和OPT的开源工作。尽管表现出色,但LLM产生的答案并不总是可靠的。我们的工作旨在使LLM在任务自动化领域中可靠。
2.2 Large Language Models for Task Automation
LLM能够作为数字或物理AI任务自动化的动作器或协调器/计划器。当作为动作器时,LLM的输出是可执行的动作,仅限于自然语言处理任务。在物理,模拟物理和数字环境中,LLM通常充当类似大脑的协调器,将人类高级指令处理为逐步可执行的机器命令,并将其移交给特定领域的模型或API,以进行实际操作。沿着这条路线,LLM一直在为任务自动化开辟无限的可能性,这同时对自动化系统提出了更高的可靠性要求。LLM的知识缺陷或LLM和执行器之间的差距都可能导致任务完成失败甚至对用户造成伤害的潜在风险。先前的工作试图通过训练一个外部模型来评估LLM的输出以解决可执行性问题。它在一个简单的机器人环境中取得了成功,但很难将其应用于具有更多目标和各种动作的复杂环境。此外, [35, 37]跟踪LLM后续计划的执行结果。据我们所知,我们是第一个从可行性,完整性和安全观点系统地研究基于LLM的任务自动化的可靠性的工作。
3.Method
3.1 ResponsibleTA Framework
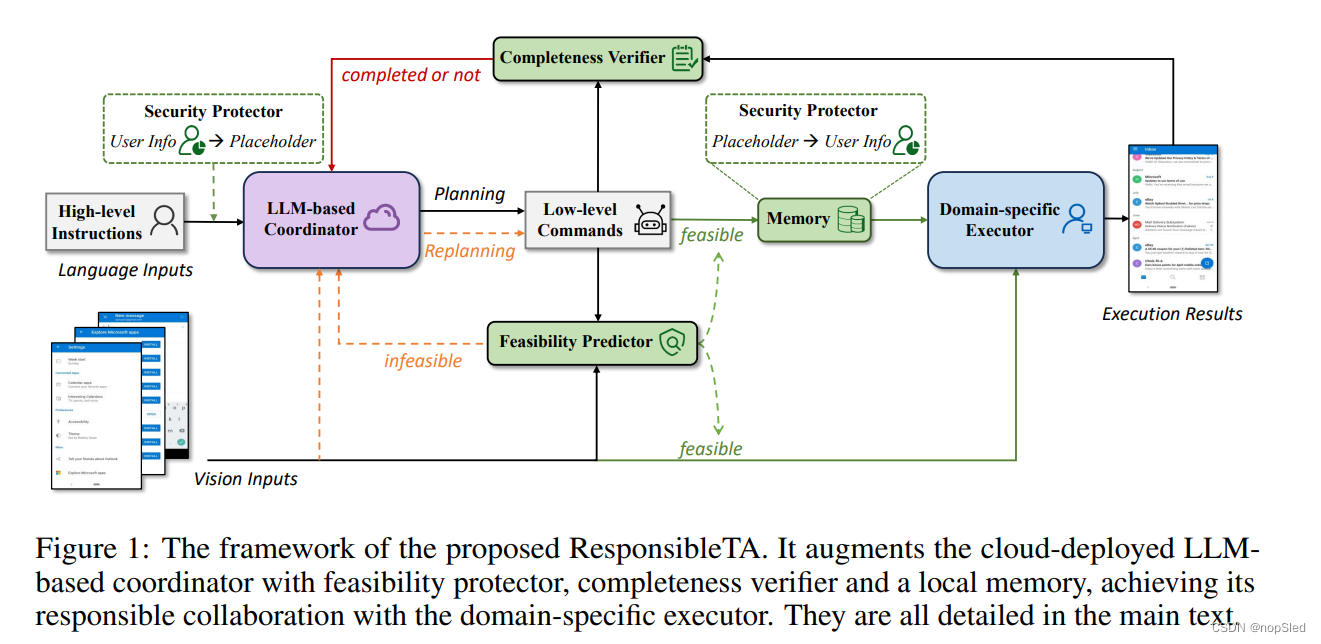
ResponsibleTA是一个基本的多模态框架,用于使LLM作为负责任的任务自动完成器。目的是全面增强使用LLM作为协调器的可靠性,同时采用特定于领域的模型/API作为执行器,以根据人类指令自动完成任务。它通过三个能力来实现可靠性增强:可行性预测,完整性验证和安全保护。
如图1所示,ResponsibleTA从人类的获取高级指令(即任务目标)作为输入,并使用预训练的LLM进行行动计划,以将其解析为低级(即逐步)的命令。为了确保在每个步骤中生成的低级命是合理的并是被正确执行的,我们在ResponsibleTA中引入了可行性预测器和完整性验证程序。在每次执行之前,可行性预测器基于当前屏幕截图和命令本身,来评估生成的低级命令在是否可以执行。当命令被判断为不可行时,它将要求基于LLM的协调器通过提示工程进行重新计划,否则在可执行的情况下将命令送给执行器。在达到预设的最大重新计划尝试时,LLM将终止当前任务并为用户提供反馈。每次执行后,完整性验证器将检查执行结果是否与给定低级命令的目标对齐。一旦检测到无效或未对齐的执行,LLM将启动计划。请注意,我们只有在需要重新计划时才通过训练好的屏幕解析模型将UI元素信息以语言形式输入LLM,以尽可能保护用户屏幕上的个人信息(有关更多详细信息,请参见附录)。此外,我们将安全保护器集成到ResponsibleTA中,以允许本地存储用户敏感的信息。使用此模块,允许使用预定义的占位符的替换用户所有敏感信息,并在将命令发送到边缘部署的执行器时恢复这些信息。因此,ResponsibleTA增强了协调器和执行器之间的内部对齐方式,并为用户提供安全保证,作为负责任的任务自动化框架。
我们采用UI任务自动化作为实际应用场景,以进行深度调查和实验,以便1)凭直觉展示ResponsibleTA的有效性和2)清晰陈述了ResponsibleTA中三个核心模块的实现。它的目标是自动化人与UI之间的交互任务(例如,在网站上搜索,播放媒体,在线购物,更改设置等)。以一个给定的低级指令和对应的屏幕截图作为输入,我们训练一个特定领域的执行器,通过预测其单击或输入的空间坐标来自动与目标UI元素交互。由于这不是这项工作的重点,因此我们将执行器的详细模型设计和训练放在实验部分和附录中。
3.2 Feasibility Predictor

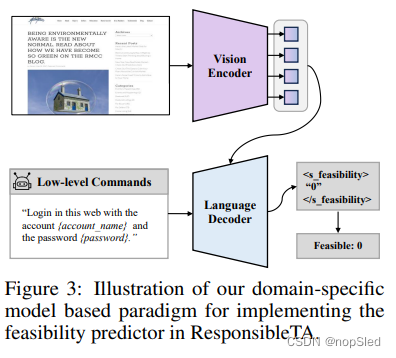
3.3 Completeness Verifier



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









