






摘要
虽然从头开始训练大型语言模型 (LLM) 可以生成具有独特功能和优势的模型,但它的成本很高,并且可能会导致能力冗余。另外一种经济有效且引人注目的方法是将现有的预训练LLM合并到更高效的模型中。然而,由于这些LLM的架构不同,直接混合它们的权重是不切实际的。在本文中,我们介绍了LLM知识融合的概念,旨在结合现有LLM的能力并将其转移到单个LLM中。通过利用源LLM的生成分布,我们将他们的集体知识和独特优势具体化,从而有可能将目标模型的能力提升到超越任何单一源LLM的能力。我们使用具有不同架构的三种流行的 LLM(Llama-2、MPT 和 OpenLLaMA)在各种基准和任务中验证我们的方法。我们的研究结果证实,LLM的融合可以提高目标模型在推理、常识和代码生成等一系列功能方面的性能。我们的代码、模型权重和数据在 https://github.com/fanqiwan/FuseLLM 上公开。
1.介绍
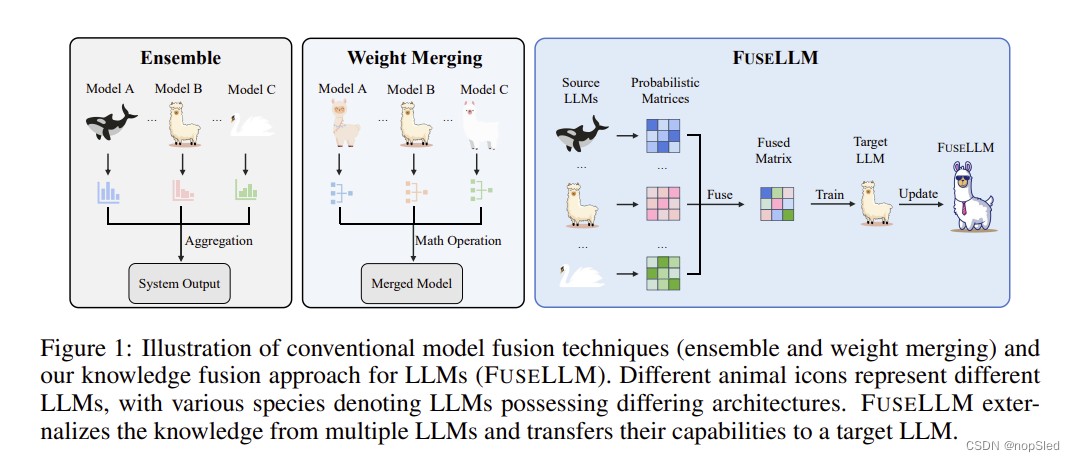
随着 GPT 和 LLaMA 系列等大型语言模型 (LLM) 在广泛的自然语言处理 (NLP) 任务中不断取得成功,创建自己的 LLM 已成为企业的战略当务之急。然而,与LLM开发相关的成本是天文数字。除了需要大量的训练数据、先进的技术、大量的计算资源和熟练的专家外,开发过程还对能源消耗和环境造成巨大的压力。虽然这些LLM在结构和功能上存在差异,但它们在一系列 NLP 任务中具有相似的能力。因此,除了从头开始训练LLM的传统方法之外,另一种选择是将现有LLM合并为一个新的、更强大的LLM,在本文中称为LLM知识融合。如果成功,这种融合不仅可以降低初始训练的成本,还可以使集成模型受益于所有LLM的优势。这种新模型还可以针对各种下游任务进行微调和调整。此外,融合也可以发生在专门从事特定任务的经过微调的LLM之间。
整合多种模型的能力是我们长期以来的追求。例如,集成方法直接聚合不同模型的输出以增强预测性能和鲁棒性。然而,这种方法需要维护多个经过训练的模型并在推理过程中执行每个模型,这对于LLM来说是不切实际的,因为它们需要大量的内存和推理时间。同样,这种方法也不利于微调,而微调对于许多LLM来说是必不可少的。另一种方法是通过参数式算术运算直接将多个神经网络合并为一个网络。这种方法通常假设具有统一的网络架构,并尝试在不同神经网络的权重之间建立映射,这在LLM的背景下通常是无法实现的。此外,当参数空间中存在显着差异时,权重合并可能会导致次优结果。
在本文中,我们从概率分布的角度探讨了LLM的融合。对于输入文本,我们认为不同来源的LLM生成的概率分布可以反映他们在理解该文本时的固有知识。因此,所提出的 FUSELLM 利用源 LLM 的生成分布来外化他们的集体知识和个人优势,并通过轻量级持续训练将它们转移到目标 LLM。为了实现这一目标,我们开发了一种新的策略来对齐来自不同LLM的tokenizations,并探索两种方法来融合这些不同的LLM生成的概率分布。 在持续训练期间,FUSELLM 非常重视最小化目标 LLM 的概率分布与源 LLM 的概率分布之间的差异。
为了凭经验证明 FUSELLM 的有效性,我们研究了 LLM 融合的一个具有挑战性但普遍的场景,其中源模型具有很少的共同点。具体来说,我们关注三种具有独特架构和功能的流行开源LLM:Llama-2、OpenLLaMA 和 MPT。对三个基准(总共 42 个任务组成,涵盖推理、常识和代码生成)的评估证实,通过我们的方法训练的目标模型在大多数任务中优于每个源 LLM 和基线。此外,我们通过在几个特定领域的语料库上持续训练单一base模型,模拟具有相同架构但功能不同的现有LLM。当基于困惑度进行评估时,与传统的集成和权重合并方法相比,我们的方法在结合这些结构相同的 LLM 的功能方面表现出了卓越的潜力。
综上所述,本文探讨了一种称为LLM融合的新挑战,其目标是创建一个统一的模型,有效利用不同LLM的集体能力和独特优势。如图 1 所示,我们提出的方法与传统的集成和权重合并技术不同,它优先考虑通过知识外化和迁移来融合多个LLM。这项研究得出的一些发现可能会激发未来的研究。首先,虽然我们通过在紧凑的高质量语料库上进行轻量级持续训练来证明我们的方法的有效性,但训练语料库的深思熟虑的选择可能是一个关键的考虑因素,特别是在其与下游任务的相关性方面。其次,在源LLM的能力差异很大的情况下,融合功能对于有效结合各自的优势似乎至关重要。最后,与传统的模型集成和权重合并技术相比,LLM融合领域似乎是一个更有前景的探索途径,特别是考虑到LLM的不同结构和巨大的模型规模。
2.相关工作
Model Fusion。整合不同模型的能力一直是一个长期目标,现有方法主要分为两类。首先,传统的模型集成技术结合了多个模型的输出来提高系统的整体性能。请注意,这一技术并不涉及将多个模型显式合并到一个新模型中。模型集成的常用方法通常采用加权平均或多数投票来整合各种模型的预测。最近,Jiang et al. (2023) 引入了一个集成框架,旨在利用多个开源LLM的不同优势。该框架首先采用成对比较方法来检测候选输出之间的细微差别。然后,它将排名靠前的候选结合起来,以产生增强的输出,从而利用他们的优势,同时减轻他们的弱点。
其次,权重合并提供了另一种促进参数级模型融合的方法。Gupta et al. (2020) 和 Wortsman et al. (2022) 合并了通过不同策略或配置获得的具有相同结构的模型的权重,以提高整体性能。同样,Cha et al. (2021), Rame et al. (2022) 和 Arpit et al. (2022) 探索了从不同配置派生的模型的加权平均,以增强分布外泛化。此外,Jin et al. (2022) 合并了为特定领域或任务设计的模型,以创建能够解决所有领域或任务的模型。Wang et al. (2022b), Huang et al. (2023) 和 Zhang et al. (2023) 将线性数学运算应用于适配器参数以实现卓越的泛化性能。
简而言之,虽然模型集成需要多个模型的并行部署,但权重合并通常仅限于具有相同架构的模型。相比之下,本文提出的方法通过将多个LLM的知识和能力明确地转移到目标LLM,支持具有不同架构的多个LLM的融合。
Knowledge Distillation。知识蒸馏最初是为模型压缩而提出的,涉及在一个或多个teacher模型的指导下训练student模型。在NLP社区中,知识蒸馏被广泛应用于文本分类任务。这些应用包括训练student模型以复制teacher的输出分布,以及从教师模型的中间层得到的特征和关系。在文本生成领域,传统方法侧重于最小化student和teacher生成分布之间的 KL 差异。这是通过使用teacher在每个时刻的概率分布作为有监督或直接对teacher生成的文本进行训练来实现的。
虽然我们的方法共享一个类似于多teacher知识蒸馏的框架,但有两个显着的区别。首先,在传统知识蒸馏中,student模型的规模通常被限制为小于teacher模型的规模。然而,在我们的场景中,目标模型的大小没有限制。其次,传统的知识蒸馏往往会导致student模型在蒸馏后的表现落后于teacher。相比之下,我们预计融合后,目标模型的性能将超过任何源模型。
3.KNOWLEDGE FUSION OF LLMS
LLM融合的主要目标是将多个源LLM中嵌入的集体知识具体化,并将其能力集成到目标LLM中。给定具有不同架构的 K K K 个源 LLM { M j s } j = 1 K \{\mathcal M^s_j\}^K_{j=1} {Mjs}j=1K,每个 LLM 都在不同的数据集上进行了单独的预训练或微调,我们方法背后的关键思想是首先通过挑战 LLM 预测下一个token来刺激 LLM 表现出其固有知识。这些预测的概率分布经过彻底评估,并利用最准确的预测,使用因果语言建模目标在语料库 C \mathcal C C 上持续训练目标 LLM M t \mathcal M^t Mt。在以下部分中,我们首先简要介绍预备知识,然后详细解释我们的LLM融合框架。最后,我们深入研究实现细节。
3.1 PRELIMINARIES
令
t
t
t 表示从语料库
C
\mathcal C
C 中采样的长度为
N
N
N 的文本序列,
t
<
i
=
(
t
1
,
t
2
,
.
.
.
,
t
i
−
1
)
t_{<i}=(t_1, t_2, ..., t_{i−1})
t<i=(t1,t2,...,ti−1) 表示第
i
i
i 个token之前的序列。用于训练由
θ
θ
θ 参数化的语言模型的因果语言建模 (CLM) 目标被定义为最小化负对数似然:
L
C
L
M
=
−
E
t
∼
C
[
∑
i
l
o
g
p
θ
(
t
i
∣
t
<
i
)
]
,
(1)
\mathcal L_{CLM}=-\mathbb E_{t\sim \mathcal C}\bigg [\sum_i log~p_{\theta}(t_i|t_{\lt i})\bigg ],\tag{1}
LCLM=−Et∼C[i∑log pθ(ti∣t<i)],(1)
其中
p
θ
(
t
i
∣
t
<
i
)
p_{\theta}(t_i|t_{\lt i})
pθ(ti∣t<i)是模型在给定先前token的情况下对token
i
i
i的预测概率。
上述目标将序列似然分解为token级的交叉熵损失,将每个token的预测分布与其one-host表示进行比较。为了提供更普遍的视角,我们将这种token级视图重新构建为序列分布格式。具体来说,对于文本序列
t
t
t,我们聚合 token 级的预测并创建一个概率分布矩阵
P
t
θ
∈
R
N
×
V
\textbf P^θ_t ∈ \mathbb R^{N×V}
Ptθ∈RN×V,其中第
i
i
i 行表示模型预测的第
i
i
i 个 token 在词表
V
V
V中的分布。然后,CLM 目标可以解释为减少
P
t
θ
\textbf P^θ_t
Ptθ 与one-hot标签矩阵
O
t
∈
{
0
,
1
}
N
×
V
\textbf O_t ∈\{0, 1\}^{N×V}
Ot∈{0,1}N×V 之间的差异,其中每一行都是相应gold token的one-hot表示。形式上,CLM 目标转换为以下表示形式:
L
C
L
M
=
−
E
t
∼
C
[
D
(
P
t
θ
,
O
t
)
]
,
(2)
\mathcal L_{CLM}=-\mathbb E_{t\sim \mathcal C}[\mathbb D(\textbf P^{\theta}_t,\textbf O_t)],\tag{2}
LCLM=−Et∼C[D(Ptθ,Ot)],(2)
其中
D
(
⋅
,
⋅
)
D(·,·)
D(⋅,⋅)表示两个矩阵之间的差异函数,当实现为KL散度时,其等价于方程1。
3.2 LLMS FUSION
从语言模型的角度来看,我们认为概率分布矩阵可以反映其在理解文本时的某些固有知识。因此,来自不同LLM的同一文本的不同概率分布矩阵可用于表示这些模型中嵌入的不同知识。认识到这一点,提出的 FUSELLM 方法通过概率建模来解决 LLM 融合问题,旨在通过合并源 LLM 的概率分布来创建统一的 LLM。为了实现这一目标,当从一组要融合的 LLM 开始时,FUSELLM 在反映预训练数据集的原始文本语料库上对目标 LLM 进行轻量级持续训练。FUSELLM 不是仅仅依赖于 CLM 目标,而是非常重视最小化目标 LLM 的概率分布与源 LLM 的概率分布之间的差异。
对于语料库
C
\mathcal C
C 中的每个文本,我们应用提供的
K
K
K 个源 LLM 并获得一组概率分布矩阵,表示为
{
P
t
θ
j
}
j
=
1
K
\{\textbf P^{θ_j}_t\}^K_{j=1}
{Ptθj}j=1K,其中
θ
j
θ_j
θj 表示第
j
j
j 个 LLM 的参数。利用这些矩阵,我们将各个模型的知识外化到统一的空间中,本质上是在文本上创建统一的概率表示。我们承认源 LLM 之间的词表差异可能会导致矩阵错位。为了解决这个问题,我们采用了token对齐策略(第 3.3 节中对此进行了解释),以促进跨模型的更连贯的概率解释。
对齐概率矩阵后,我们继续将它们融合成一个紧凑的表示。为此目的可以应用各种融合策略,如第 3.3 节所述。我们使用
P
t
\textbf P_t
Pt来表示融合矩阵,如下所示:
P
t
=
F
u
s
i
o
n
(
P
t
θ
1
,
P
t
θ
2
,
.
.
.
,
P
t
θ
K
)
,
(3)
\textbf P_t=\mathbb Fusion(\textbf P^{\theta_1}_t,\textbf P^{\theta_2}_t,...,\textbf P^{\theta_K}_t),\tag{3}
Pt=Fusion(Ptθ1,Ptθ2,...,PtθK),(3)
其中
F
u
s
i
o
n
(
⋅
)
\mathbb Fusion(·)
Fusion(⋅) 表示组合多个矩阵的函数,所得矩阵
P
t
\textbf P_t
Pt 被视为源 LLM 的集体知识和独特优势的表示。
为了将源 LLM 的能力转移到目标 LLM,我们强制目标 LLM 的预测和融合表示矩阵
P
t
\textbf P_t
Pt 之间对齐。我们使用
Q
t
\textbf Q_t
Qt 来表示文本
t
t
t 在目标 LLM 的输出分布矩阵,然后定义我们的融合目标如下:
L
F
u
s
i
o
n
=
−
E
t
∼
C
[
D
(
Q
t
,
P
t
)
]
.
(4)
\mathcal L_{Fusion}=-\mathbb E_{t\sim \mathcal C}[\mathbb D(\textbf Q_t,\textbf P_t)].\tag{4}
LFusion=−Et∼C[D(Qt,Pt)].(4)
我们持续训练的总体目标由因果语言建模目标
L
C
L
M
L_{CLM}
LCLM 和融合目标
L
F
u
s
i
o
n
L_{Fusion}
LFusion 的加权组合组成,如下所示:
L
=
λ
L
C
L
M
+
(
1
−
λ
)
L
F
u
s
i
o
n
.
(5)
\mathcal L=\lambda \mathcal L_{CLM}+(1-\lambda)\mathcal L_{Fusion}.\tag{5}
L=λLCLM+(1−λ)LFusion.(5)
3.3 IMPLEMENTATION OF FUSELLM
在本节中,我们将介绍token对齐的实现细节以及在 FUSELLM 方法中融合不同 LLM 的融合函数。
Token Alignment。确保跨多个LLM的token对齐对于有效的知识融合至关重要,因为它保证了概率分布矩阵的正确映射。Fu et al. (2023) 采用动态编程来递归地最小化编辑一个token序列以匹配另一个token序列的总成本。如果两个token之间存在一对一映射,则相应的分布是完美映射的。否则,映射的分布会退化为one-hot向量。由于不同tokenizer为同一序列生成的token通常表现出有限的差异,因此我们建议通过最小编辑距离(MinED)策略替换 Fu et al. (2023) 中的精确匹配(EM)约束来提高token对齐的成功率,该策略根据 MinED 映射来自不同tokenizer的token。这种token对齐的放松有助于在分布矩阵中保留大量信息,同时引入较小的错误。有关token对齐的更多详细信息,请参阅附录 A。
Fusion Strategies。为了结合源LLM的集体知识,同时保留其独特优势,必须评估不同LLM的质量并为其各自的分布矩阵分配不同的重要性级别。为此,在处理文本
t
t
t 时,我们利用分布矩阵和golden标签之间的交叉熵损失作为 LLM 预测质量的指标。源LLM的交叉熵分数越低,意味着对文本的理解越准确,其预测应该具有更大的意义。基于这个标准,我们引入两个融合函数:(1)MinCE:该函数输出具有最小交叉熵得分的分布矩阵; (2) AvgCE:该函数根据交叉熵分数生成分布矩阵的加权平均值。
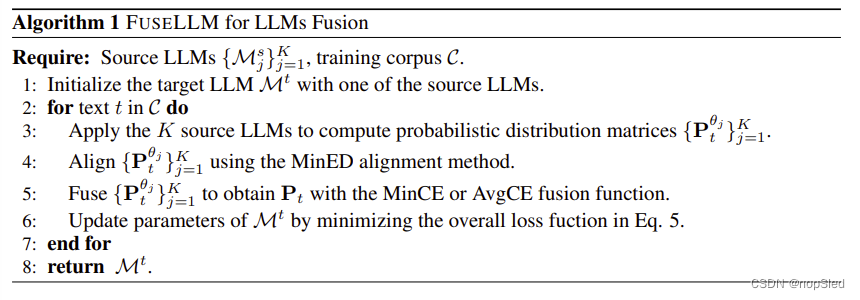
FUSELLM方法的完整流程如算法1所示。
4.EXPERIMENTS
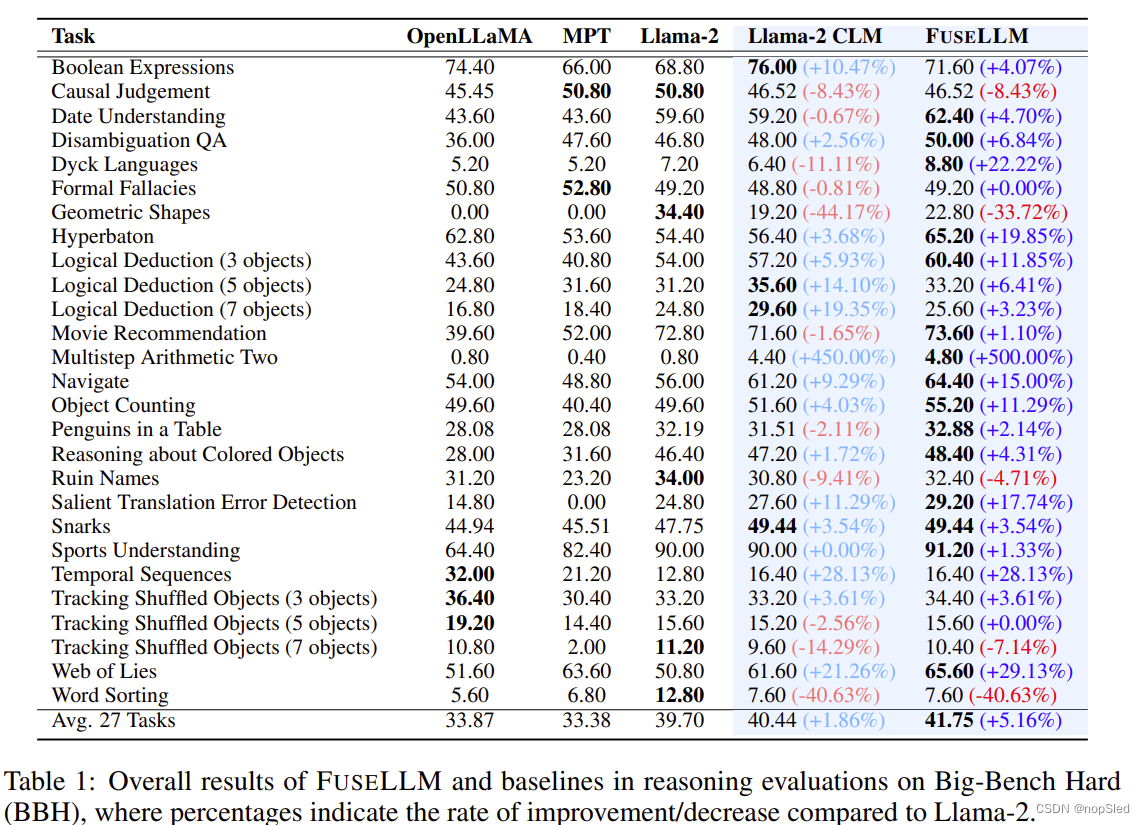
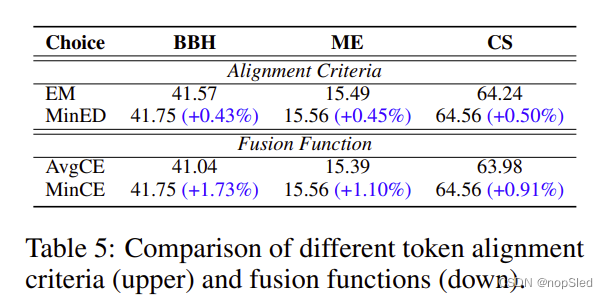


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









