






摘要
大型语言模型 (LLM) 的性能受到所提供提示质量的显著影响。为此,研究人员开发了大量提示工程策略,旨在修改提示文本以提高任务性能。在本文中,我们介绍了一种称为位置工程的新技术,它提供了一种更有效的方法来指导大语言模型。与需要大量努力来修改提供给 LLM 的文本的提示工程不同,位置工程仅涉及更改提示中的位置信息而不修改文本本身。我们在两种广泛使用的 LLM 场景中评估了位置工程:检索增强生成 (RAG) 和上下文学习 (ICL)。我们的研究结果表明,位置工程在这两种情况下都大大提高了基线。因此,位置工程代表了一种有前途的新策略,可用于利用大型语言模型的功能。
1.介绍
大型语言模型 (LLM) 的最新进展表明,在实现通用人工智能方面取得了重大进展。这些模型展现出广泛的功能,例如上下文学习、根据文档回答问题、解决复杂的数学问题以及生成代码。
在使用 LLM 时,用户提示被输入,转换成token序列,然后通过多个注意力层进行处理。这些注意力层使用从token序列中得出的两种信息:(i) 语义信息,其中token被转换为文本嵌入;(ii) 位置信息,其中token的索引被转换为位置嵌入。然后,注意力机制将文本和位置嵌入结合起来,以预测序列中下一个token的分布。
人们已经对通过修改提示文本以改变语义信息进行了广泛的研究,旨在提高任务表现。例如,引入了few-shot提示,使 LLM 能够以上下文方式学习新任务。此外,还引入了思维链方法,通过提示 LLM 生成中间token来增强其推理能力。此外,还开发了自动提示工程来自主设计提示文本,以提高特定任务的表现。
在本研究中,我们研究了仅通过修改位置信息而不改变任何语义信息来提高性能的潜力。我们首次发现,只需调整token的位置索引,而无需修改文本本身,就可以显著提高任务性能。
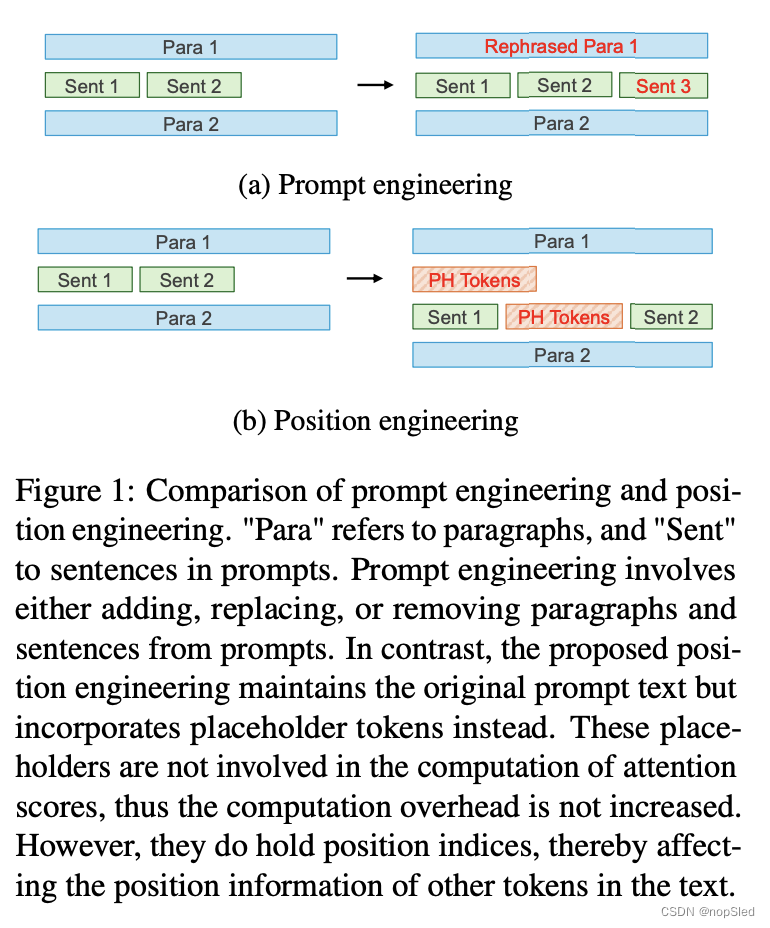
如图 1 所示,我们的方法涉及引入占位符token。这些占位符token不会对注意力分数的计算做出贡献;但是,它们会占用token索引。因此,其他token的相对位置会发生变化,这可以优化提示中不同部分之间的注意力权重。我们将这种方法称为位置工程,强调对操纵位置信息的专注。
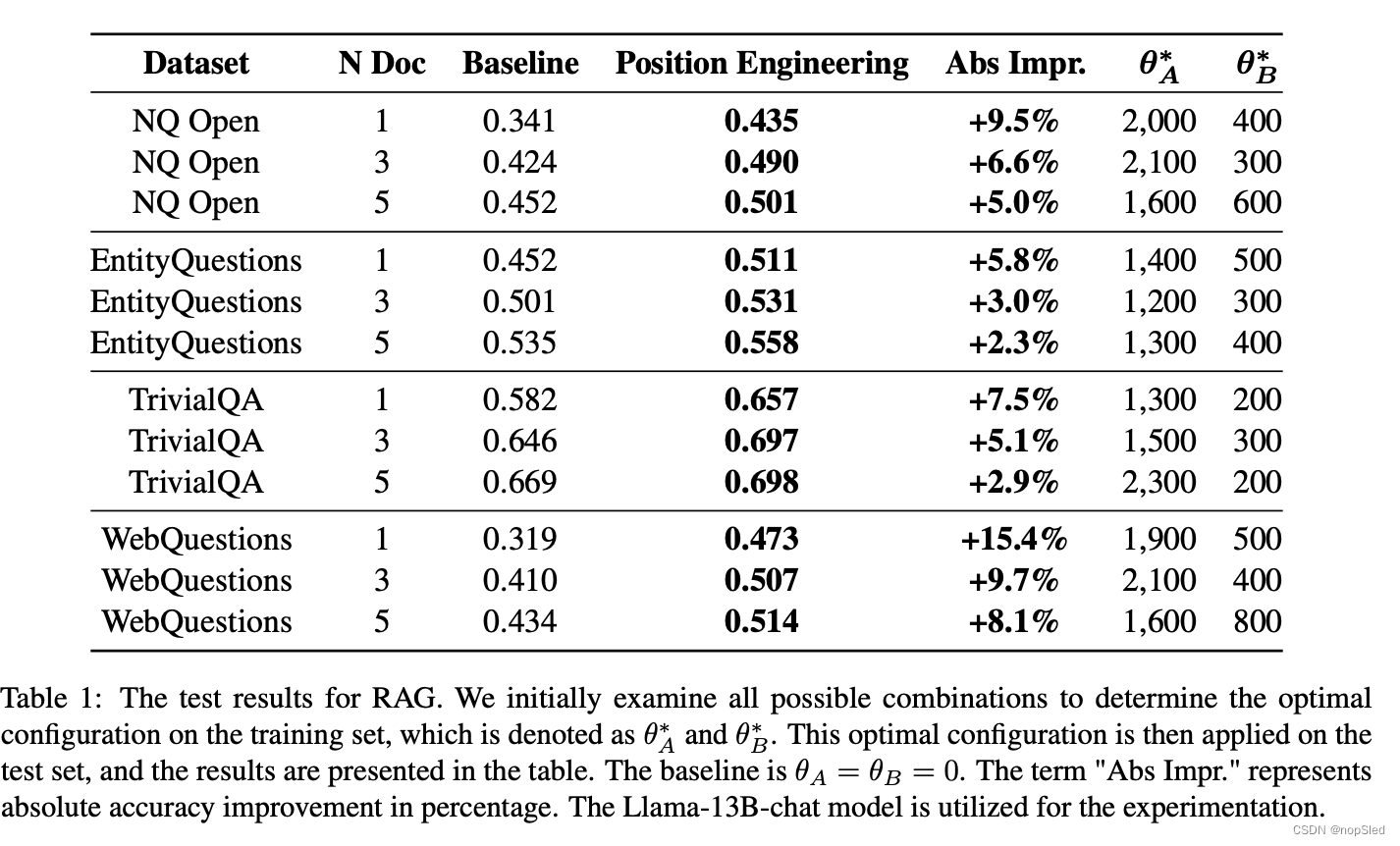
我们在 LLM 的两种常见场景中实验了位置工程:检索增强生成 (RAG) 和上下文学习 (ICL)。位置工程显著提高了这两项任务的性能,RAG 的准确率绝对提升了 15.4%,ICL 的准确率绝对提升了 3.6%。我们假设位置工程可以作为一种细致入微的方法,用于调整提示中各个部分的注意力权重。通过在两个部分之间插入占位符token,它们之间的注意力得分会降低,从而放大对其他部分的关注。例如,RAG 的提示通常由一条指令、几个检索到的文档和一个问题组成。我们的研究结果表明,通过位置工程可以减少指令的影响,同时增强对问题和文档的关注,这是有利的。
位置工程有几个优点。首先,它的搜索过程是在数字空间内进行的,可以有效地利用传统的数字优化器。相比之下,提示工程涉及在文本空间内进行搜索,这本质上更为复杂,需要专门的策略。其次,位置工程仅涉及位置索引的调整,因此不会影响计算工作量。最后,将位置工程与提示工程相结合可以带来进一步的改进。
本文的结构如下:第 2 部分详细阐述了位置工程的方法。第 3 部分介绍实验和发现。第 4 部分讨论优势和未来工作。第 5 部分回顾相关文献,最后在第 6 部分得出结论。
2.方法
2.1 Preliminary
在本节中,我们简要概述了大型语言模型 (LLM) 如何整合位置信息。令
{
t
i
}
i
=
1
N
\{t_i\}^N_{i=1}
{ti}i=1N 表示语言模型的输入token,令
{
e
i
}
i
=
1
N
\{\textbf e_i\}^N_{i=1}
{ei}i=1N 表示相应的token嵌入。最初,注意力层
q
,
k
,
v
\textbf q, \textbf k, \textbf v
q,k,v的计算为:
q
m
=
f
q
(
e
m
,
m
)
k
n
=
f
q
(
e
n
,
n
)
v
n
=
f
q
(
e
n
,
n
)
(1)
\begin{array}{cc} \textbf q_m=f_q(\textbf e_m, m) \\ \textbf k_n=f_q(\textbf e_n, n) \\ \textbf v_n=f_q(\textbf e_n, n) \\ \end{array}\tag{1}
qm=fq(em,m)kn=fq(en,n)vn=fq(en,n)(1)
其中,
m
m
m和
n
n
n是token的位置索引。自注意力然后被计算如下:
a
m
,
n
=
e
q
m
T
k
n
d
∑
j
=
1
N
e
q
m
T
k
j
d
o
m
=
∑
n
=
1
N
a
m
,
n
v
n
(2)
\begin{array}{cc} a_{m,n}=\frac{e^{\frac{\textbf q^T_m\textbf k_n}{\sqrt{d}}}}{\sum^N_{j=1}e^{\frac{\textbf q^T_m\textbf k_j}{\sqrt{d}}}}\\ \textbf o_m=\sum^N_{n=1}a_{m,n}\textbf v_n \end{array}\tag{2}
am,n=∑j=1NedqmTkjedqmTknom=∑n=1Nam,nvn(2)
其中
a
m
,
n
a_{m,n}
am,n 是一个标量,表示query中的第
m
m
m 个标记与value和key中的第
n
n
n 个标记之间的注意力得分。
d
d
d表示注意力层的维度,
o
m
o_m
om 表示第
m
m
m 个query token的输出。
绝对位置最初是通过合并位置嵌入向量
p
n
\textbf p_n
pn 来引入的,该向量与
m
m
m 和
n
n
n 相关:
f
q
(
e
m
,
m
)
=
W
q
(
e
m
+
p
m
)
f
k
(
e
n
,
n
)
=
W
k
(
e
n
+
p
n
)
f
v
(
e
n
,
n
)
=
W
v
(
e
m
n
+
p
n
)
(3)
\begin{array}{cc} f_q(\textbf e_m, m)=\textbf W_q(\textbf e_m + \textbf p_m) \\ f_k(\textbf e_n, n)=\textbf W_k(\textbf e_n + \textbf p_n) \\ f_v(\textbf e_n, n)=\textbf W_v(\textbf e_mn + \textbf p_n) \end{array}\tag{3}
fq(em,m)=Wq(em+pm)fk(en,n)=Wk(en+pn)fv(en,n)=Wv(emn+pn)(3)
位置嵌入
p
n
\textbf p_n
pn的第
2
i
2i
2i和
2
i
+
1
2i+1
2i+1维度被计算如下:
p
n
,
2
i
=
s
i
n
(
n
/
1000
0
2
i
d
)
p
n
,
2
i
+
1
=
c
o
s
(
n
/
1000
0
2
i
d
)
(4)
\begin{array}{cc} \textbf p_{n,2i} = sin(n/10000^{\frac{2i}{d}}) \\ \textbf p_{n,2i+1} = cos(n/10000^{\frac{2i}{d}}) \end{array}\tag{4}
pn,2i=sin(n/10000d2i)pn,2i+1=cos(n/10000d2i)(4)
最近,RoPE 采用相对位置信息代替绝对信息。它利用专门设计的矩阵
R
i
d
\textbf R^d_i
Rid(尺寸为
d
×
d
d × d
d×d,由
i
i
i 参数化)以以下方式修改query和key向量:
f
q
(
e
m
,
m
)
=
R
m
d
W
q
e
m
f
k
(
e
n
,
n
)
=
R
n
d
W
k
e
n
f
v
(
e
n
,
n
)
=
W
v
e
n
(5)
\begin{array}{cc} f_q(\textbf e_m, m) = \textbf R^d_m\textbf W_q\textbf e_m\\ f_k(\textbf e_n, n) = \textbf R^d_n\textbf W_k\textbf e_n\\ f_v(\textbf e_n, n) = \textbf W_v\textbf e_n\\ \end{array}\tag{5}
fq(em,m)=RmdWqemfk(en,n)=RndWkenfv(en,n)=Wven(5)
矩阵
R
i
d
\textbf R^d_i
Rid 具有一个独特属性,即
(
R
i
d
)
T
R
j
d
=
R
j
−
i
d
(\textbf R^d_i)^T\textbf R^d_j = \textbf R^d_{j−i}
(Rid)TRjd=Rj−id,这导致:
q
m
T
k
n
=
e
m
W
q
R
n
−
m
d
W
k
e
n
(6)
\textbf q^T_m\textbf k_n=\textbf e_m\textbf W_q\textbf R^d_{n-m}\textbf W_k\textbf e_n\tag{6}
qmTkn=emWqRn−mdWken(6)
因此,在方程 (2) 中,模型仅关注相对位置
n
−
m
n − m
n−m,而不是绝对位置
n
n
n 和
m
m
m。RoPE 已被最近的 LLM 采用,包括 Llama、Llama2 和 Mistral。
2.2 Altering Position Information in Prompts
LLM 的性能受到所用提示质量的显著影响。为了提高这些提示的有效性,研究人员开发了各种各样的提示工程策略。此改进过程涉及将初始输入token
{
t
i
}
i
=
1
N
\{t_i\}^N_{i=1}
{ti}i=1N 转换为修订后的输入
{
t
^
j
}
j
=
1
N
^
\{\hat t_j\}^{\hat N}_{j=1}
{t^j}j=1N^,这需要对文本进行修改。例如,zero-shot 思维链技术通过在提示中附加句子“Let’s think step by step.”来增强 LLM 的推理能力。
在本文中,我们提出了一种称为“位置工程”的新方法,以进一步利用 LLM 的功能。与提示工程不同,位置工程不需要修改输入token本身。相反,它仅修改等式 (1) 中使用的位置信息。通过实证实验,我们发现对位置信息的这种调整可以显著提高性能。正式地,我们的目标是发现一个可以提高 LLM 性能的位置编辑函数
τ
(
⋅
)
:
N
→
N
τ(·) : \mathbb N → \mathbb N
τ(⋅):N→N。此函数会更改token位置信息,该信息将合并到模型中,如下所示:
q
m
^
=
f
q
(
e
m
,
τ
(
m
)
)
k
n
^
=
f
k
(
e
n
,
τ
(
n
)
)
v
n
^
=
f
v
(
e
n
,
τ
(
n
)
)
(7)
\begin{array}{cc} \hat {\textbf q_m}=f_q(\textbf e_m, \tau(m))\\ \hat{\textbf k_n}=f_k(\textbf e_n, \tau(n))\\ \hat{\textbf v_n}=f_v(\textbf e_n, \tau(n)) \end{array}\tag{7}
qm^=fq(em,τ(m))kn^=fk(en,τ(n))vn^=fv(en,τ(n))(7)
我们对
τ
\tau
τ 施加一个条件,即
∀
i
>
j
,
τ
(
i
)
>
τ
(
j
)
∀i > j, τ(i) >τ(j)
∀i>j,τ(i)>τ(j)。此要求确保:(1) 不会有两个不同的token被分配到相同新位置索引的情况,以及 (2) 语言建模中的因果关系保持不变,这意味着只有具有较大索引的query向量才能访问具有相等或较小索引的key和value向量。
位置工程的概念也可以通过占位符token来解释。占位符token被定义为不参与注意力得分计算但被分配了位置索引的token。具体来说,当按照公式 (2) 的描述计算
a
m
,
n
a_{m,n}
am,n 时,如果第
m
m
m 个或第
n
n
n 个token被标识为占位符,则常规计算将被绕过,并将
a
m
,
n
a_{m,n}
am,n 设置为 0。虽然占位符token不会直接影响其位置的注意力得分,但它们会改变其他输入token的位置索引。如图 1b 所示,在句子 1 和句子 2 之间插入占位符token会影响它们之间的相对位置信息,进而影响两个句子token之间注意力得分的计算。位置编辑函数和占位符token之间的联系可以描述如下:使用位置编辑函数
τ
τ
τ 意味着在第
i
i
i 个token后添加
τ
(
i
+
1
)
−
τ
(
i
)
−
1
τ(i +1)−τ(i) − 1
τ(i+1)−τ(i)−1 个占位符token,具体来说,在第 0 个标记前添加
τ
(
0
)
τ (0)
τ(0) 个占位符token。
2.3 Position Engineering
考虑一个由
(
Q
,
A
)
(Q, A)
(Q,A) 定义的特定任务,根据任务分布
Γ
Γ
Γ 为其采样了一个训练集
{
(
Q
i
,
A
i
)
}
i
=
1
N
\{(Q_i, A_i)\}^N_{i=1}
{(Qi,Ai)}i=1N。我们将每个问题
Q
i
Q_i
Qi 转换为其对应的文本提示
P
i
P_i
Pi。使用一个大型语言模型
M
\mathcal M
M,该模型基于提示
P
i
P_i
Pi 运行,其输出通过评分函数
r
r
r 进行评估,表示为
r
(
M
,
P
i
)
r(\mathcal M, P_i)
r(M,Pi)。为了潜在地提高性能,可以对每个问题提示应用位置编辑函数。假设该函数由向量
θ
θ
θ 参数化,表示为
τ
P
i
;
θ
τ_{P_i;θ}
τPi;θ。应用位置编辑函数后,将生成一个新的分数,公式为
r
(
M
,
P
i
,
τ
P
i
;
θ
)
r(\mathcal M, P_i, τ_{Pi;θ})
r(M,Pi,τPi;θ)。
例如,在检索增强生成 (RAG) 任务中,提示
P
i
P_i
Pi 通常由三个部分组成:指令、文档和问题。可以定义
θ
=
[
θ
1
,
θ
2
]
θ = [θ_1, θ_2]
θ=[θ1,θ2],其中
θ
1
θ_1
θ1 表示在指令和文档段之间插入
θ
1
θ_1
θ1 个占位符token,而
θ
2
θ_2
θ2 表示在文档段和问题之间插入占位符token的数目。
正式地,提示工程被定义为一个优化问题。我们的目标是找到最大化得分的最优
θ
\textbf θ
θ:
θ
∗
=
a
r
g
m
a
x
θ
1
N
∑
i
=
1
N
r
(
M
,
P
i
,
τ
P
i
;
θ
)
(8)
\textbf θ^*=\mathop{argmax}\limits_{\textbf θ}\frac{1}{N}\sum^N_{i=1}r(\mathcal M, P_i, \tau_{P_i;\theta})\tag{8}
θ∗=θargmaxN1i=1∑Nr(M,Pi,τPi;θ)(8)
在本研究中,我们使用一种基本算法来解决优化问题,即首先为
θ
θ
θ 定义有限数量的候选,然后通过强力计算评估每个候选的得分。值得注意的是,由于
θ
θ
θ 是一个数值向量,因此可以通过采用各种优化器(例如贝叶斯优化的高斯过程)来加速搜索过程。未来的工作将考虑探索更复杂的优化方法。
3.Experiments


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









