






摘要
移动设备操作任务正日益成为一种流行的多模态AI应用场景。目前的多模态大语言模型(MLLM)受限于训练数据,无法有效发挥操作助手的作用,而基于MLLM的Agent通过工具调用来增强能力,正逐渐应用于该场景。然而,移动设备操作任务中的两大导航挑战——任务进度导航和焦点内容导航——在现有工作的单Agent架构下难以有效解决。这是由于token序列过长以及文本图像数据格式交替限制了性能。为了有效解决这些导航挑战,我们提出了Mobile-Agent-v2,一种用于移动设备操作辅助的多Agent架构。该架构由三个Agent组成:规划Agent、决策Agent和反思Agent。规划Agent将冗长、交替的图像文本历史操作和筛选摘要压缩为纯文本任务进度,然后传递给决策Agent。上下文长度的减少使决策Agent更容易导航任务进度。为了保留焦点内容,我们设计了一个记忆单元,该单元由决策Agent根据任务进度进行更新。此外,为了纠正错误操作,反思Agent会观察每个操作的结果并相应地处理任何错误。实验结果表明,与 Mobile-Agent 的单Agent架构相比,Mobile-Agent-v2 在任务完成方面实现了 30% 以上的提升。代码已开源,网址为 https://github.com/X-PLUG/MobileAgent。
1.Introduction
以 GPT-4v 为代表的多模态大型语言模型(MLLM)在各个领域都表现出了出色的能力。随着基于大型语言模型(LLM)的Agent的快速发展,基于 MLLM 的Agent可以利用各种视觉感知工具克服 MLLM 在特定应用场景中的局限性,已成为研究关注的焦点。
移动设备上的自动化操作作为一种实用的多模态应用场景,正在成为AI智能手机发展的一大技术革命。然而,由于屏幕识别、操作和定位能力有限,现有的MLLM在此场景中面临挑战。针对这一问题,现有工作利用基于MLLM的Agent架构,赋予MLLM感知和操作移动设备UI的各种能力。AppAgent通过从设备XML文件中提取可点击位置来解决MLLM在定位方面的局限性。然而,对UI文件的依赖限制了该方法在其他平台和设备上的适用性。为了消除对底层UI文件的依赖,Mobile-Agent提出了一种通过视觉感知工具进行定位的解决方案。它通过MLLM感知屏幕并生成操作,并通过视觉感知工具定位其位置。
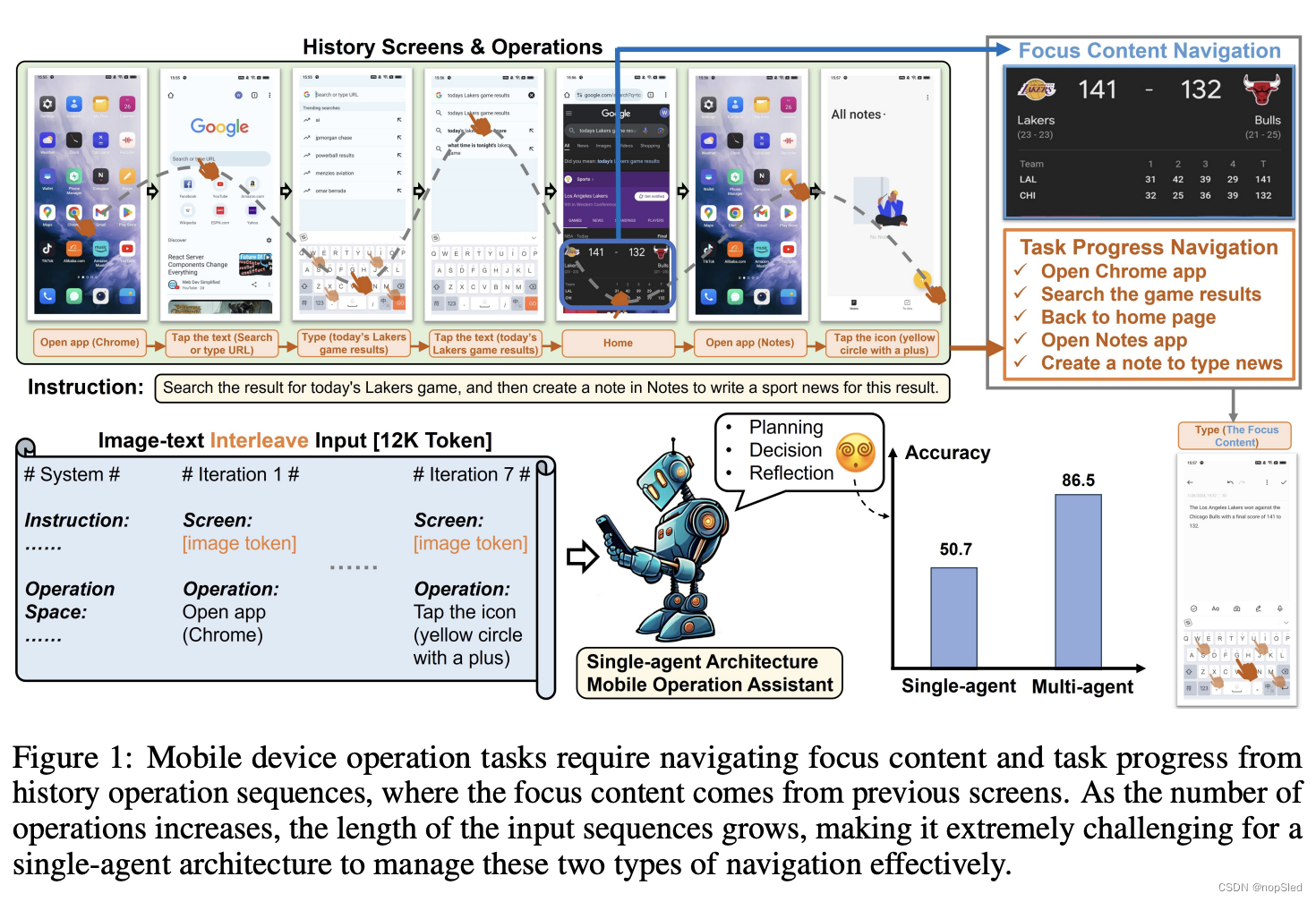
移动设备操作任务涉及多步骤序列处理,操作员需要从初始屏幕开始对设备进行一系列连续操作,直到指令完全执行。这个过程中主要有两个挑战,首先,为了规划操作意图,操作员需要从历史操作中导航出当前任务进度。其次,某些操作可能需要历史屏幕中与任务相关的信息,例如图 1 中撰写体育新闻需要使用先前查询到的比赛结果,我们将这些重要信息称为焦点内容。焦点内容也需要从历史屏幕中导航出来。然而,随着任务的进展,交替的图像和文本历史操作和屏幕作为输入的冗长历史记录会显著降低单Agent架构中导航的有效性,如图 1 所示。
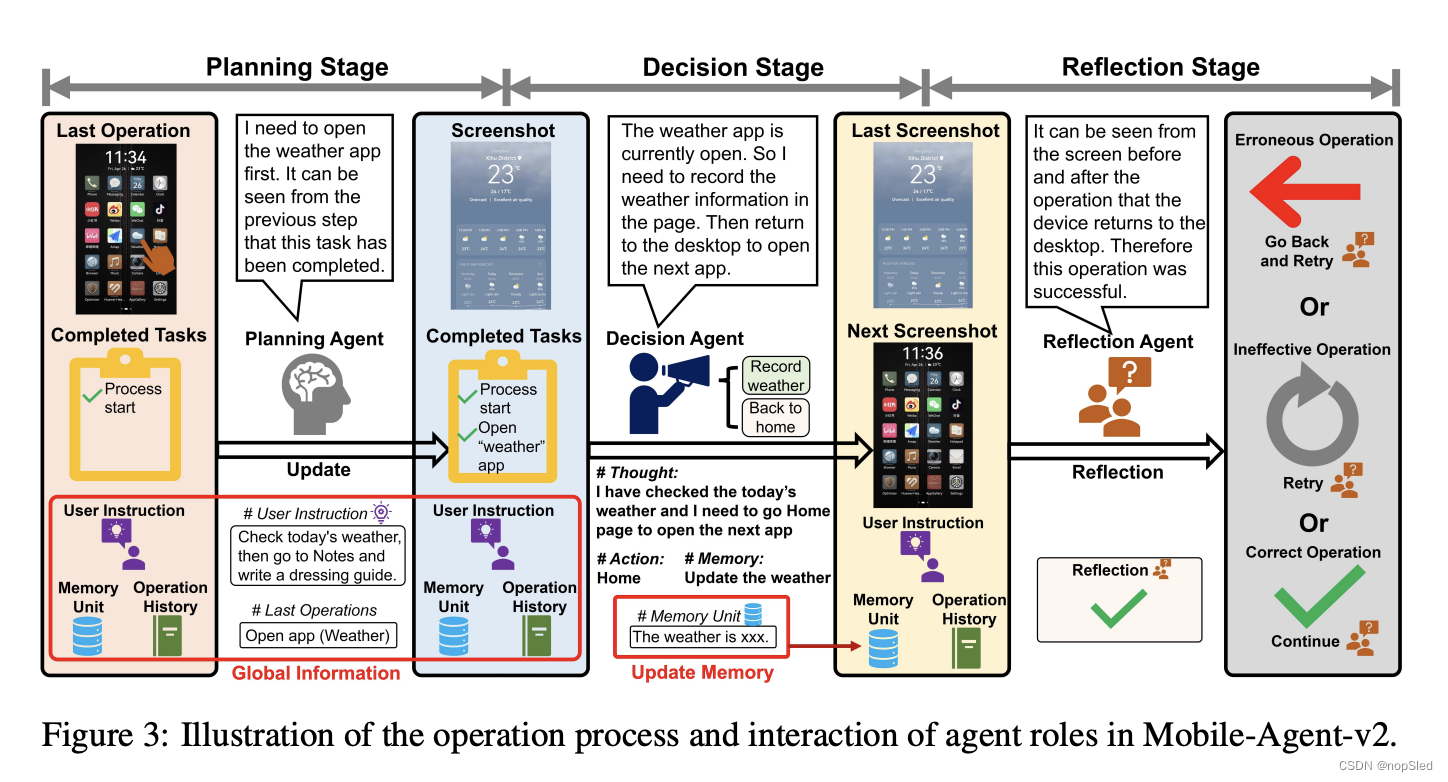
本文提出了Mobile-Agent-v2,一个通过多Agent协作实现有效导航的移动设备操作助手。Mobile-Agent-v2有三个专门的Agent角色:规划Agent、决策Agent和反思Agent。规划Agent需要根据历史操作生成任务进度。为了保存历史屏幕中的焦点内容,我们设计了一个记忆单元来记录与任务相关的焦点内容。决策Agent在生成操作时会观察这个单元,同时检查屏幕上是否有焦点内容并将其更新到记忆中。由于决策Agent无法观察前一个屏幕进行反思,我们设计了反射Agent来观察决策Agent操作前后屏幕的变化,判断操作是否符合预期。如果发现操作不符合预期,它将采取适当的措施重新执行操作。整个流程如图3所示。三个Agent角色分别在进度、决策和反思阶段工作,相互协作,缓解导航难度。
我们的贡献总结如下:
- 我们提出了一个多Agent架构 Mobile-Agent-v2,以缓解单Agent框架在移动设备操作任务中固有的各种导航困难。我们设计了一个规划Agent,根据历史操作生成任务进度,确保决策Agent有效地生成操作。
- 为了避免焦点内容导航和反思能力的丧失,我们设计了记忆单元和反思Agent。记忆单元由决策Agent用焦点内容更新。反思Agent评估决策Agent的操作是否符合预期,如果没有达到预期,则生成适当的补救措施。
- 我们对 Mobile-Agent-v2 在各种操作系统、语言环境和应用程序中进行了动态评估。实验结果表明,MobileAgent-v2 实现了显著的性能提升。此外,我们通过经验验证了 Mobile-Agent-v2 的性能可以通过手动操作知识注入进一步提升。
2.Related Work
2.1 Muiti-agent Application
大型语言模型 (LLM) 强大的理解和推理能力使得基于 LLM 的智能体能够独立执行任务。受人机协作的启发,多智能体框架被提出。Park et al. (2023) 在沙盒环境中构建了由 25 个智能体组成的 Smallville。Li et al. (2023b) 提出一种基于角色扮演的多智能体协作框架,使两个扮演不同角色的智能体能够自主协作。Chen et al. (2024) 创新性地提出了一种有效的多智能体框架,用于协调多个专家智能体的协作。Hong et al. (2024) 提出了一种开创性的元编程多智能体协作框架。Wu et al. (2024) 提出了一个通用的多智能体框架,允许用户配置智能体数量、交互模式和工具集。 Chan et al. (2024);
Subramaniam et al. (2024); Tao et al. (2024) 研究了多智能体辩论框架的实现,旨在评估不同文本或生成内容的质量。Abdelnabi et al. (2024); Xu et al. (2024); Mukobi et al. (2024) 将多智能体交互与博弈论策略相结合,旨在增强合作和决策能力。
2.2 LLM-based UI Operation Agent
网页作为 UI Agent的经典应用场景,引起了对 Web Agent研究的广泛关注。Yao et al. (2022) 和 Deng et al. (2023) 旨在通过构建高质量的网站任务数据集来提高Agent在真实网页任务上的性能。Gur
et al. (2024) 利用预训练的 LLM 和自我经验学习来自动执行真实网站上的任务处理。Zheng et al. (2024) 利用 GPT-4V 进行视觉理解和网页操作。同时,基于 LLM 的移动平台的 UI Agent 研究也引起了广泛关注。Wen et al. (2023) 将图形用户界面 (GUI) 信息转换为 HTML 表示,然后利用 LLM 结合特定于应用程序的领域知识。Yan et al. (2023) 提出了一种基于 GPT-4V 的多模态智能移动Agent,探索直接利用 GPT-4V 感知带有标注的屏幕截图。与前一种在带有数字标签的屏幕上操作的方法不同,Zhang et al. (2023a) 结合应用程序的 XML 文件进行定位操作,模仿人类在操作移动应用程序时的空间自主性。Wang et al. (2024) 消除了对应用程序 XML 文件的依赖,并利用可视化模块工具进行定位操作。此外,Hong et al. (2023) 设计了一个基于预训练视觉语言模型的 GUI Agent。Chen and Li (2024a,b,c) 提出了用于实际设备部署的小规模客户端模型。Zhang et al. (2024a) 提出了一种针对 Windows 操作系统量身定制的 UI Multi-Agent框架。尽管Multi-Agent架构在许多任务中实现了显着的性能改进,但目前尚无在移动设备操作任务中使用Multi-Agent架构的工作。为了解决移动设备操作任务中长上下文导航的挑战,本文引入了Multi-Agent架构 Mobile-Agent-v2。
3.Mobile-Agent-v2
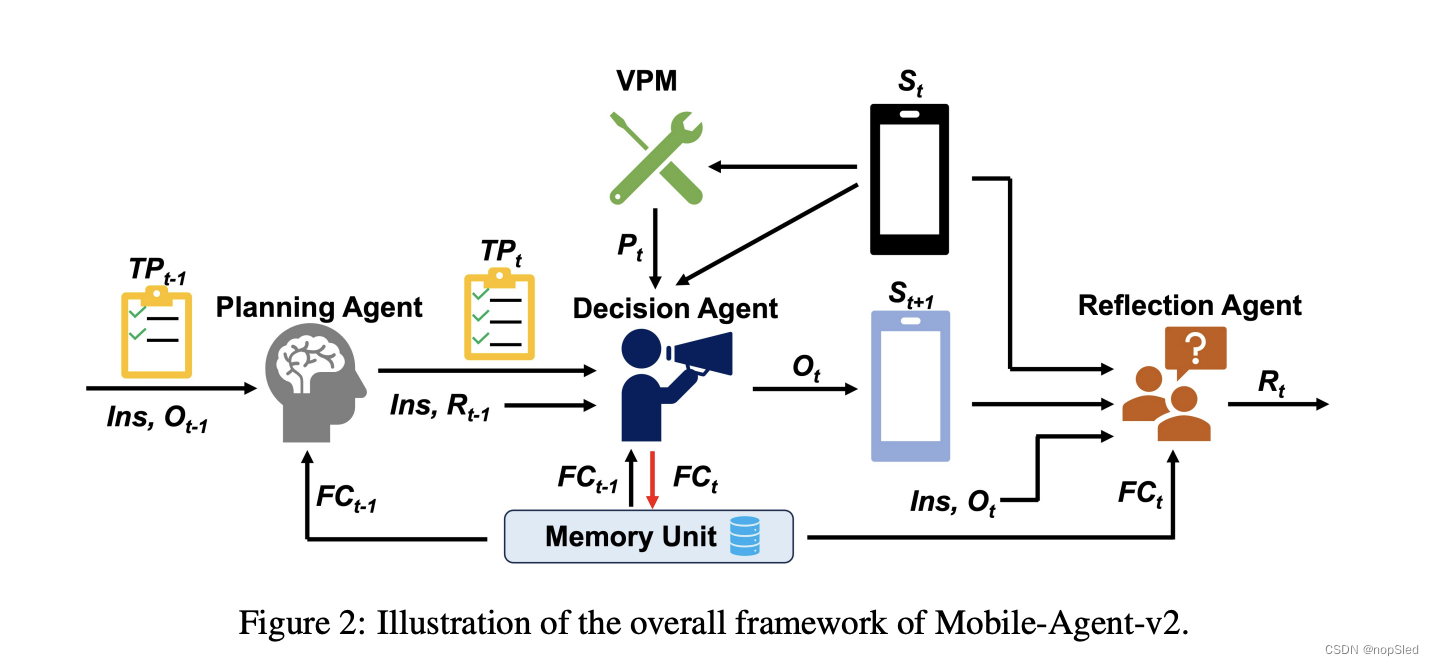
本节将详细介绍 Mobile-Agent-v2 的架构。Mobile-Agent-v2 的操作是迭代的,其流程如图 2 所示。Mobile-Agent-v2 有三个专门的Agent角色:规划Agent、决策Agent和反思Agent。我们还设计了视觉感知模块和记忆单元,以增强Agent的屏幕识别能力和从历史中导航焦点内容的能力。首先,规划Agent更新任务进度,让决策Agent导航当前任务的进度。然后,决策Agent根据当前任务进度、当前屏幕状态和反思(如果上一次操作有误)进行操作。随后,反思Agent观察操作前后的屏幕,以确定操作是否符合预期。
3.1 Visual Perception Module
即使对于最先进的 MLLM 来说,端到端处理时屏幕识别仍然具有挑战性。因此,我们整合了一个视觉感知模块来增强屏幕识别能力。在这个模块中,我们使用了三个工具:文本识别工具、图标识别工具和图标描述。将屏幕截图输入此模块最终将得到屏幕上的文本和图标信息以及它们各自的坐标。这个过程由以下公式表示:
P
t
=
V
P
M
(
S
t
)
(1)
P_t=VPM(S_t)\tag{1}
Pt=VPM(St)(1)
其中
P
t
P_t
Pt表示第
t
t
t次迭代中屏幕的感知结果。
3.2 Memory Unit
由于规划Agent生成的任务进度是文本形式,历史屏幕中焦点内容的导航仍然具有挑战性。为了解决这个问题,我们设计了一个记忆单元来存储历史屏幕中与当前任务相关的焦点内容。记忆单元是一个短期记忆模块,会随着任务的进展而更新。记忆单元对于涉及多个应用程序的场景至关重要。例如,如图3所示,决策Agent观察到的天气信息将在后续操作中使用。此时,与天气应用程序页面相关的信息将在记忆单元中更新。
3.3 Planning Agent
我们的目标是通过使用单独的Agent来减少决策过程中对冗长历史操作的依赖。我们观察到,尽管每轮操作发生在不同的页面上并且不同,但多个操作的目标往往是相同的。例如,在图 1 所示的示例中,前四个操作都是关于搜索匹配结果。因此,我们设计了一个规划Agent来汇总历史操作并跟踪任务进度。
我们将决策Agent在第
t
t
t次迭代中生成的操作定义为
O
t
O_t
Ot。在决策Agent做出决策之前,规划Agent会观察决策Agent自上一次迭代以来的操作
O
t
−
1
O_{t−1}
Ot−1,并将任务进度
T
P
t
−
1
TP_{t−1}
TPt−1更新为
T
P
t
TP_t
TPt。任务进度包括已经完成的子任务。规划Agent生成任务进度后,将其传递给决策Agent,以帮助决策Agent考虑尚未完成的任务内容,从而促进下一个操作的生成。如图3所示,规划Agent的输入包括四部分:用户指令
I
n
s
Ins
Ins、记忆单元中的焦点内容
F
C
t
FC_t
FCt、上一次操作
O
t
−
1
O_{t−1}
Ot−1和上一次任务进度
T
P
t
−
1
TP_{t−1}
TPt−1。基于以上信息,规划Agent生成
T
P
t
TP_t
TPt。该过程用以下公式表示:
T
P
t
=
P
A
(
I
n
s
,
O
t
−
1
,
T
P
t
−
1
,
F
C
t
−
1
)
(2)
TP_t=PA(Ins,O_{t-1},TP_{t-1},FC_{t-1})\tag{2}
TPt=PA(Ins,Ot−1,TPt−1,FCt−1)(2)
其中
P
A
PA
PA表示LLM的规划Agent。
3.4 Decision Agent
决策Agent在决策阶段运行,生成操作
O
O
O并在设备上执行,同时负责更新记忆单元中的焦点内容
F
C
FC
FC。该过程在图3所示的决策阶段中进行了说明,并由以下公式表示:
O
t
=
D
A
(
I
n
s
,
T
P
t
−
1
,
F
C
t
−
1
,
R
t
−
1
,
S
t
,
P
t
)
(3)
O_t=DA(Ins,TP_{t-1},FC_{t-1},R_{t-1},S_t,P_t)\tag{3}
Ot=DA(Ins,TPt−1,FCt−1,Rt−1,St,Pt)(3)
其中,
D
A
DA
DA表示决策Agent的MLLM,
R
t
R_t
Rt表示反思Agent的反思结果。
Operation Space。为了降低操作的复杂性,我们设计了一个操作空间,并限制决策Agent只能从这个空间中选择操作。对于自由度更高的操作,例如点击和滑动,我们加入了一个额外的参数空间来定位或处理特定内容。下面是操作空间的详细描述:
- Open app (app name),若当前页面为首页,则该操作可以打开名为“应用名称”的应用。
- Tap (x, y)。此操作用于点击坐标为 ( x , y ) (x,y) (x,y)的位置。
- Swipe (x1, y1), (x2, y2)。该操作用于从坐标 ( x 1 , y 1 ) (x1,y1) (x1,y1)的位置滑动到坐标 ( x 2 , y 2 ) (x2,y2) (x2,y2)的位置。
- Type (text)。若当前键盘处于活动状态,则可以通过此操作在输入框中输入“文本”的内容。
- Home。此操作用于从任意页面返回主页。
- Stop。如果决策Agent认为所有要求都已得到满足,则可以使用此操作来终止整个操作过程。
Memory Unit Update。由于决策Agent的每一次操作都与任务高度相关,且基于当前页面的视觉感知结果,因此非常适合观察屏幕页面中与任务相关的焦点内容。因此,我们赋予决策Agent更新记忆单元的能力。在进行决策时,会提示决策代理观察当前屏幕页面中是否存在与任务相关的焦点内容。如果观察到此类信息,决策Agent就会将其更新到记忆中,以供后续决策参考。这个过程用以下公式表示:
F
C
t
=
D
A
(
I
n
s
,
F
C
t
−
1
,
S
t
,
P
t
)
(4)
FC_t=DA(Ins, FC_{t-1},S_t,P_t)\tag{4}
FCt=DA(Ins,FCt−1,St,Pt)(4)
3.5 Reflection Agent
即使加入了视觉感知模块,Mobile-Agent-v2 仍然可能产生意想不到的操作。在特定场景下,MLLM 甚至可能产生严重的幻觉,即使是最先进的 MLLM GPT-4V 也会出现这种情况。因此,我们设计了反思Agent,用于观察决策Agent操作前后的屏幕状态,以判断当前操作是否符合预期。这个过程用以下公式表示:
R
t
=
R
A
(
I
n
s
,
F
C
t
,
O
t
,
S
t
,
P
t
,
S
t
+
1
,
P
t
+
1
)
(5)
R_t=RA(Ins,FC_t,O_t,S_t,P_t,S_{t+1},P_{t+1})\tag{5}
Rt=RA(Ins,FCt,Ot,St,Pt,St+1,Pt+1)(5)
其中 RA 表示反思Agent的 MLLM。
如图3所示,反思Agent在操作执行后会产生三种类型的反思结果:错误操作、无效操作、正确操作。下面将对这三种反思结果进行描述:
- 错误操作是指导致设备进入与任务无关的页面的操作。例如,Agent本想在消息应用程序中与联系人 A 聊天,但却意外打开了联系人 B 的聊天页面。
- 无效操作是指不会导致当前页面发生任何变化的操作。例如,Agent本想点击某个图标,但却点击了图标旁边的空白处。
- 正确操作是指符合决策Agent期望的操作,是实现用户指令要求的一步。
若操作错误,页面会恢复到操作前的状态。若操作无效,页面会保持当前状态。错误和无效的操作都不会记录在操作历史中,以防止Agent跟踪这些操作。若操作正确,操作会更新到操作历史中,页面也会更新到当前状态。

















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









