







一、线性表的链式存储结构
顺序存储结构线性表的最大问题:插入和删除需要移动大量的元素(时间复杂度高),如何解决呢?
链式存储的定义:
为了表示每个元素与其直接后继元素之间的逻辑关系,数据元素除了存储本身的信息之外,还需要存储其直接后继的信息。

通过保存地址的关系将数据元素链接起来。Ai和Ai+1是线性表中的两个相邻的数据元素,在物理内存中无相邻关系。
链式存储逻辑结构:基于链式存储结构的线性表,每个结点都包含数据域和指针域。
数据域:存储数据元素本身。
指针域:存储相邻结点的地址。
专业术语:顺序表——基于顺序存储结构的线性表
链表:基于链式存储结构的线性表。
单链表:每个结点只包含直接后继的地址信息
循环链表:单链表中的最后一个结点的直接后继为第一个结点
双向链表:单链表中的结点包含直接前驱和后继的地址信息。
链表中的基本概念:
头结点:链表中的辅助结点,包含指向第一个数据元素的指针。//不包含数据信息,只包含地址信息
数据结点:链表中代表数据元素的结点,表现形式为:(数据元素、地址)。
尾结点:链表中的最后一个数据结点,包含的地址信息为空。
struct Node: public Object //继承自Object顶层父类
{
T value; //数据元素的具体类型
Node* next; //指向后继结点的指针
};Node:单链表中结点类型。

头结点在单链表中意义:辅助数据元素的定位,方便插入和删除操作,因此,头结点不存储实际的数据元素。
在目标位置处插入数据元素:
1、从头结点开始,通过current指针定位到目标位置;
2、从堆空间申请新的Node结点
3、执行操作:
node->value = e;
node->next = current->next;
current->next = node;从目标位置处删除数据元素: //核心思维就是先替换,再删除
1、从头结点开始,通过current指针定位到目标位置;
2、使用toDel指针指向需要删除的结点;
3、执行操作:
toDel = current->next;
current->next = toDel->next;
delete toDel;注意:
1、链表中的数据元素在物理内存中无相邻关系;
2、链表中的结点都包含数据域和指针域;
3、头结点用于辅助数据元素的定位,方便插入和删除操作;
4、插入和删除操作需要保证链表的完整性。
二、单链表的具体实现
LinkList设计要点:
1、类模板:通过头结点访问后继结点;
2、定义内部结点类型Node,用于描述数据域和指针域;
3、实现线性表的关键操作(增、删、查、等)。
template < typename T>
class LinkList : public List<T>
{
protected:
struct Node : public Object
{
T value;
Node* next; //?
};
mutable struct : public Object //如果不继承自Object,就会导致内存布局上面的不同
{
char reserved[sizeof(T)];
Node* next;
} m_header;
//创建m_header时,不再调用泛指类型的构造函数
//为什么呢?
//因为头结点的构造,只需要对泛指类型进行sizeof()操作,不涉及到具体对象的构建。
//头结点类型需要重新定义,定义头结点的时候,忽视继承自顶层父类,导致内存布局上的不同。
//只要进行代码改动,就需要重新测试功能。
int m_length;
int m_step; //游标每次移动的数目
Node* m_current;
Node* position(int i) const
{
Node* ret = reinterpret_cast<Node*>(&m_header); //强制类型转换
for(int p=0; p<i; p++)
{
ret = ret->next;
}
return ret;
}
virtual Node* create()
{
return new Node(); //一开始是在堆空间中申请任意内存;
}
virtual void destroy(Node* pn)
{
//cout<< " 父类的析构函数"<< endl;
delete pn;
}
public:
LinkList()
{
m_header.next = NULL;
m_length = 0;
m_step = 1;
m_current = NULL;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool insert(int i, const T& e)
{
bool ret = ( (0 <= i) && ( i <= m_length));
if(ret)
{
Node* node = create(); //取决的当前的对象是单链表的对象还是静态单链表对象 因为是虚函数 可以实现多态
if( node != NULL)
{
Node* current = position(i);
node->value = e;
node->next = current->next;
current->next = node;
m_length++;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException,"No memoty to insert a node");
}
}
return ret;
}
bool remove(int i)
{
bool ret = ( (0 <= i) && ( i <= m_length));
if(ret)
{
Node* current =position(i);
Node* toDel = current->next;
if( m_current == toDel)
{
m_current = toDel->next;
}
current->next = toDel->next;
m_length--;
destroy(toDel) ;
}
return ret;
}
bool set(int i, const T& e)
{
bool ret = ( (0 <= i) && ( i <= m_length));
if(ret)
{
position(i)->next->value = e;
}
return ret;
}
virtual T get( int i) const //重载的get()函数
{
T ret;
if( get(i, ret) )
{
return ret;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException,"No memory to insert a element");
}
return ret;
}
bool get(int i, T& e) const
{
bool ret = ( (0 <= i) && ( i <= m_length));
if(ret)
{
e = position(i)->next->value;
}
return ret;
}
int length() const
{
return m_length;
}
void clear()
{
while( m_header.next )
{
Node* toDel = m_header.next;
m_header.next = toDel->next;
m_length--;
destroy( toDel );
}
}
virtual int find(const T& e) const
{
int ret = -1;
int i=0;
Node* node = m_header.next;
while( node )
{
if( node->value == e)
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}
virtual bool move(int i, int step = 1) //将游标定位到目标位置
{
bool ret = (0 <= i) && (i < m_length) && (step > 0);
if( ret)
{
m_current = position(i)->next;
m_step = step;
}
return ret;
}
virtual bool end() //游标是否到达尾部(是否为空)
{
return ( m_current == NULL );
}
virtual T current() //获取游标所指向的数据元素
{
if( !end() )
{
return m_current->value;
}
else
{
THROW_EXCEPTION(InvalidOperationException,"No valve at current position ...");
}
}
virtual bool next() //移动游标
{
int i = 0;
while( (i< m_step) && !end() )
{
m_current = m_current->next;
i++;
}
return ( i == m_step);
}
~LinkList()
{
clear();
}
};针对头结点可能存在的隐患:
class Test : public Object
{
public:
Test()
{
Throw 0;
}
};如果库是一个商用的库,并没有创建Test类的对象,构造的时候需要调用构造函数创建Test的对象。
构造头结点的时候不去调用泛指类型的构造函数,创建新的匿名类型(注意内存布局,可以继承自同一父类),定义的目的仅仅是为了头结点,定义单链表对象头结点的时候,定义仅仅为了占空间的数组对象,在内存布局上面和之前无差异,差异在于不管泛指类型T是任何情况,都不会调用构造函数。
mutable struct : public Object //如果不继承自Object,就会导致内存布局上面的不同
{
char reserved[sizeof(T)];
Node* next;
} m_header;代码优化:insert()、remove()、get()、set()等操作都设计元素定位——设计position()函数。
总结:通过类模板实现链表,包含头结点成员和长度成员;定义结点类型,并通过堆中的结点对象构成链式存储;为了避免构造错误的隐患,头结点类型需要重新定义;代码优化是编码完成后必不可少的环节。
三、顺序表与单链表的对比分析
如何判断某个数据元素是否存在于线性表中?
find()函数:int find(const T& e) const;
参数:待查找的数据元素
返回值:>=0:数据元素在线性表中第一次出现的位置;
-1:数据元素不存在。
virtual int find(const T& e) const
{
int ret = -1;
int i=0;
Node* node = m_header.next;
while( node )
{
if( node->value == e)
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}针对自定义类类型的比较操作(自定义类类型应该也继承自顶层父类),在顶层父类中,实现相等比较操作符的重载函数:
bool Object::operator ==(const Object& obj) //默认实现
{
return (this == &obj);
}
bool Object::operator !=(const Object& obj)
{
return (this != &obj);
}时间复杂度对比分析:
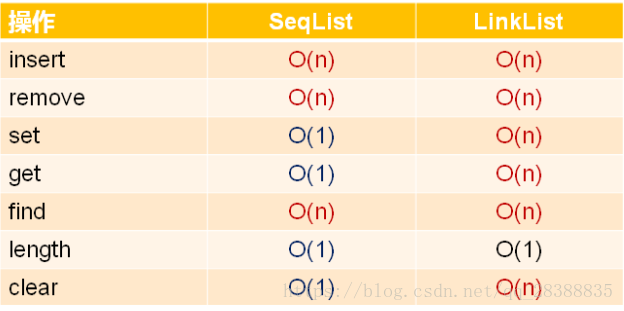
顺序表的整体时间复杂度比单链表要低,那么单链表还有使用价值吗?
效率的深度分析:时间的工程开发中,时间复杂度只是效率的一个参考标准:
对于内置基础类型,顺序表和单链表(指针操作,4字节或者8字节)的效率不相上下;
对于自定义类类型,顺序表在效率上低于单链表(依旧指针操作,和数据类型无关)。
插入和删除:
顺序表:涉及大量数据对象的复制操作;
单链表:只涉及指针操作,效率与数据对象无关。
数据访问:
顺序表:随机访问,可直接定位数据元素;
单链表:顺序访问,必须从头访问数据对象,无法直接定位。
工程开发中的选择:
顺序表:数据元素的类型相对简单,不涉及深拷贝;
数据元素相对稳定,访问操作远多于插入和删除操作。
单链表:数据元素的类型相对复杂,复制操作相对耗时;
数据元素不稳定,需要经常插入和删除,访问操作较少。
总结:顺序表适用于访问需求量较大的场合(随机访问)
单链表适用于数据元素频繁插入删除的场合(顺序访问)
四、单链表的遍历与优化
如何遍历单链表中的每一个数据元素?
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++) //O(N)
{
list.insert(i);
}
for(int i=0; i<list.length(); i++) //O(?) ---> O(N*N)
{
cout << list.get(i) << endl;
}
return 0;
}问题:单链表不能以线性的时间复杂度完成单链表的遍历
新的需求:为单链表提供新的方法,在线性时间内完成遍历。
设计思路(m_current:指针):
1、在单链表的内部定义一个游标(Node* m_current)
2、遍历开始前将游标指向位置为0的数据元素
3、获取游标指向的数据元素
4、通过结点中的next指针移动游标
提供一组遍历相关的函数,以线性的时间复杂度遍历链表
virtual bool move(int i, int step = 1) //将游标定位到目标位置
virtual bool next() //移动游标
virtual T current() //获取游标所指向的数据元素
virtual bool end() //游标是否到达尾部(是否为空)
具体使用如下:
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++) //O(N)
{
list.insert(0, i);
}
for(int i=0; i<list.length(); i++) //O(N)
{
cout << list.get(i) << endl;
}
for(list.move(0); !list.end(); list.next())
{
cout << list.current() << endl;
}
for(list.move(0, 2); !list.end(); list.next())
{
cout << list.current() << endl;
}
for(list.move(0, 10); !list.end(); list.next())
{
cout << list.current() << endl;
}
return 0;
}单链表内部的一次封装——可以增强扩展性:
virtual Node* create()
{
return new Node(); //一开始是在堆空间中申请任意内存;
}
virtual void destroy(Node* pn)
{
//cout<< " 父类的析构函数"<< endl;
delete pn;
}五、静态单链表的实现(StaticLinkList)
单链表的一个陷阱:
触发条件:长时间使用单链表对象频繁增加和删除数据元素
可能的结果:堆空间产生大量的内存碎片,导致系统运行缓慢。
新的线性表——设计思路:
List <--- LinkList <--- StaticLinkList
在“单链表”内部增加一片预留的空间(连续的内存),所有的Node对象都在这片空间中动态创建和动态销毁。
静态单链表的实现思路:
1、通过模板定义静态单链表(staticlinklist)
2、在类中定义固定大小的空间(unsigned char[])
3、重写create和destroy函数,改变内存的分配和归还方式
4、在Node类中重载operator new,用于在指定内存上创建对象。
template < typename T, int N >
class StaticLinkList : public LinkList<T>
{
protected:
typedef typename LinkList<T>::Node Node; //加typename的原因在于 编译器不知道访问的是类型还是静态成员变量
struct SNode :public Node //单纯使用Node类型会涉及构造函数的调用,
{
void* operator new(unsigned int size, void* loc) //分配好内存之后,在指定的内存上调用构造函数,两个参数,
{
(void)size; //C语言中的暴力声明
return loc; //返回调用构造函数的内存地址
}
};
unsigned char m_space[sizeof(Node)* N];
int m_used[N];
Node* create()
{
SNode* ret = NULL;
for(int i=0; i<N; i++)
{
if( !m_used[i] )
{
ret = reinterpret_cast<SNode*>(m_space) + i; //指针运算 单纯的分配内存 不涉及构造
ret = new(ret)SNode(); //通过new关键字在指定的内存空间上调用SNode的构造函数
m_used[i] = 1;
break;
}
}
return ret;
}
void destroy(Node *pn)
{
SNode* space = reinterpret_cast<SNode*>(m_space);
SNode* psn = dynamic_cast<SNode*>(pn); //强制类型转换,将父类指针转换成子类指针
for(int i=0; i<N; i++)
{
if( psn == (space + i) ) //第i个内存单元需要归还
{
m_used[i] = 0;
psn->~SNode(); //默认的析构函数
break; //空间归还后。对象析构,立即跳出循环
}
}
}
public:
StaticLinkList()
{
for(int i=0; i<N; i++)
{
m_used[i] =0; //标记每一个内存单元都是可用的
}
}
int capacity()
{
return N;
}
~StaticLinkList()
{
this->clear();
}
};main()函数的实现
int main()
{
StaticLinkList<int, 5> list;
for(int i=0; i<5; i++) //O(N)
{
list.insert(0, i);
}
try{
list.insert(6); // 已经设置了该类型的初始化内存数量
}
catch(const Exception& e)
{
cout << e.message() <<endl;
}
for(list.move(0); !list.end(); list.next())
{
cout << list.current() << endl;
}
return 0;
}注意:LinkList中的insert()函数中
Node* node = create(); //取决的当前的对象是单恋的对象还是静态单链表对象 因为是虚函数 可以实现多态在单链表可以使用的地方,均可以使用静态单链表。
在上一小节中提到的问题,LinkList中封装create和destroy函数的意义是什么?
答案:为静态单链表(staticlinklist)的实现做准备,StaticLinkList与LinkList的不同仅在于链表节点内存分配上的不同,因此,将仅有的不同,封装于父类和子类的虚函数中。
小结:顺序表和单链表相结合后衍生出静态单链表;
静态单链表是LinkList的子类,拥有单链表的所以操作;
静态单链表在预留的空间中创建结点对象;
静态单链表适用于频繁增删数据元素的场合。(最大元素个数固定)
六、循环链表的实现
什么是循环链表?
概念上:任意数据元素都有一个前驱和一个后继,所有的数据元素的关系构成一个逻辑上的环。
实现上:循环链表是一种特殊的单链表,尾结点的指针域保存了首结点的地址。

循环链表的实现思路:
通过模板定义CircleList类,继承自LinkList类;
定义内部函数last_to_first(),用于将单链表首尾相连
特殊处理:首元素的插入操作和删除操作
重新实现:清空操作和遍历操作。
循环链表的实现要点:
插入位置为0时:
头结点和尾结点均指向新结点;
新结点成为首结点插入链表。
删除位置为0时:
头结点和尾结点指向位置为1的结点;
安全销毁首结点。
Node* last() const //获取尾结点
{
return this->position(this->m_length-1)->next;
}
void last_to_first() const
{
last()->next = this->m_header.next;
}注意Node仍为别名
typedef typename LinkList<T>::Node Node;针对参数i较大的情形,进行取余操作:
int mod(int i) const
{
return (this->m_length == 0) ? 0:(i % this->m_length);
}
插入结点操作:
bool insert(const T& e)
{
return insert(this->m_length, e);
}
bool insert( int i, const T& e)
{
bool ret = true;
i = i %(this->m_length + 1); //注意i为0的情形
ret = LinkList<T>::insert(i, e); //调用父类的insert();
if( ret && (i == 0)) // 注意插入位置为0的时候,即形成循环链表的地方。判断i的值,若为0,则首尾相连
{
last_to_first();
}
return ret;
}删除结点操作:
bool remove( int i ) //循坏链表 i值很大
{
bool ret = true;
i = mod(i);
if( i == 0)
{
Node* toDel = this->m_header.next; //即将删除的结点
if( toDel != NULL)
{
this->m_header.next = toDel->next;
this->m_length--;
if( this->m_length > 0)
{
last_to_first();
if( this->m_current == toDel)
{
this->m_current = toDel->next;
}
}
else //删除之后链表消失
{
this->m_header.next = NULL;
this->m_current = NULL;
}
this->destroy(toDel); //异常安全到最后一步销毁首结点
}
else
{
ret = false;
}
}
else
{
ret = LinkList<T>::remove(i);
}
return ret;
}
set()、get()、find()的实现
bool set(int i, const T& e)
{
return LinkList<T>::set( mod(i), e);
}
T get(int i) const
{
return LinkList<T>::get( mod(i));
}
T get(int i, const T& e)const //? type arguement?
{
return LinkList<T>::get( mod(i), e);
}
int find(const T& e)const
{
int ret = -1;
//last()->next = NULL;
// ret = LinkList<T>::find(e); //出异常怎么办? 怎么解决异常安全?
// last_to_first(); //find出异常后,该行语句不会执行,会损害数据:不建议try_catch,会降低可移植性
Node* slider = this->m_header.next; //指向首结点
for(int i=0; i<this->m_length; i++)
{
if( slider->value == e)
{
ret = i;
break;
}
slider = slider->next;
}
return ret;
}清除操作clear()
void clear()
{
while ( this->m_length > 1)
{
remove(1); //如果每次为0,效率低下。 可以参照remove()函数实现
}
if( this->m_length == 1)
{
Node* toDel = this->m_header.next;
this->m_header.next = NULL;
this->m_length = 0;
this->m_current =NULL;
this->destroy(toDel);
}
} bool move(int i, int step )
{
return LinkList<T>::move(mod(i), step);
}
bool end()
{
return (this->m_length == 0) || (this->m_current == NULL);
}
~CircleList()
{
clear();
}
分析:构建一个循环链表,通过move()函数,设置步长和移除位置,每次移除一个数,通过最后移除的两个数字,就可以确定站在那个位置比较安全。
编程实现如下:
void josephus(int n, int s, int m) //start,murder
{
CircleList<int> cl;
for(int i=1; i<=n; i++)
{
cl.insert(i); //调用父类的insert()函数实现单链表,调用子类的insert()实现循环链表。
}
cl.move(s-1, m-1);
while (cl.length() > 0)
{
cl.next();
cout<< cl.current() <<endl;
cl.remove(cl.find(cl.current()));
}
}
int main()
{
josephus(41, 1, 3);
return 0;
}运行结果如下:

小结:尾结点的指针域保存了首结点的地址
特殊处理首元素的插入操作和删除操作
重新实现了清空操作和遍历操作
七、双向链表的实现
单链表的缺陷一:单向性:只能从头结点开始高效访问链表中的数据元素
单链表的缺陷二:缺陷:如果需要逆向访问单链表中的数据元素将极其低效。

解决方案——设计新的数据结构:
在“单链表”的结点中增加一个指针pre,用于指向当前结点的前驱结点。
双向链表继承自LinkList,具体实现如下:
template <typename T>
class DualLinkList : public List<T>
{
protected:
struct Node : public Object
{
T value;
Node* next;
Node* pre; //新增的前驱结点
};
mutable struct : public Object //头结点
{
char reserved[sizeof(T)];
Node* next;
Node* pre; //新增的前驱结点
}m_header;
int m_length;
int m_step; //游标每次移动的数目
Node* m_current;
Node* position(int i) const
{
Node* ret = reinterpret_cast<Node*>(&m_header);
for(int p=0; p<i; p++)
{
ret = ret->next;
}
return ret;
}
virtual Node* create()
{
return new Node(); //一开始是在堆空间中申请任意内存;
}
virtual void destroy(Node* pn)
{
//cout<< " 父类的析构函数"<< endl;
delete pn;
}
public:
DualLinkList()
{
m_header.next = NULL;
m_header.pre = NULL;
m_length = 0;
m_step = 1;
m_current = NULL;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool insert(int i, const T& e)
{
bool ret = ( (0 <= i) && ( i <= m_length));
if(ret)
{
Node* node = create(); //取决的当前的对象是单恋的对象还是静态单链表对象 因为是虚函数 可以实现多态
if( node != NULL )
{
Node* current = position(i);
Node* next = current->next;
node->value = e;
node->next = next; //step1
current->next = node; //step2
if(current != reinterpret_cast<Node*>(&m_header)) //注意current是不是头结点
{
node->pre = current; //step3
}
else
{
node->pre = NULL;
}
if(next != NULL) //不是插入在链表最后 为空则 (next==NULL) = 1
{
next->pre = node; //step4
}
m_length++;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException,"No memoty to insert a node");
}
}
return ret;
}
bool remove(int i)
{
bool ret = ( (0 <= i) && ( i <= m_length));
if(ret)
{
Node* current =position(i);
Node* toDel = current->next;
Node* next = toDel->next;
if( m_current == toDel)
{
m_current = next;
}
current->next = next; //step1
if( next != NULL) //step2
{
next->pre = toDel->pre ;
}
m_length--;
destroy(toDel) ;
}
return ret;
}
bool set(int i, const T& e)
{
}
virtual T get( int i) const
{
}
bool get(int i, T& e) const
{
}
int length() const
{
}
virtual int find(const T& e) const
{
}
virtual void clear()
{
}
virtual bool move(int i, int step = 1) //将游标定位到目标位置
{
}
virtual bool end() //游标是否到达尾部(是否为空)
{
}
virtual T current() //获取游标所指向的数据元素
{
}
virtual bool next() //移动游标
{
}
virtual bool pre()
{
int i = 0;
while( (i< m_step) && !end() )
{
m_current = m_current->pre;
i++;
}
return ( i == m_step);
}
~DualLinkList()
{
clear();
}
};双向链表和单链表虽然相似,但是具体实现是不同的(数据结构不同)。
双向链表是为了弥补单链表的缺陷而重新设计的;
在概念上,双向链表不是单链表,没有继承关系;
双向链表中的游标能够直接访问当前结点的前驱和后继;
双向链表是线性表概念的最终实现。
八、双向循环链表的实现(使用Linux内核链表实现)
使用Linux内核链表实现双向循环链表。
template<typename T> class DualCircleList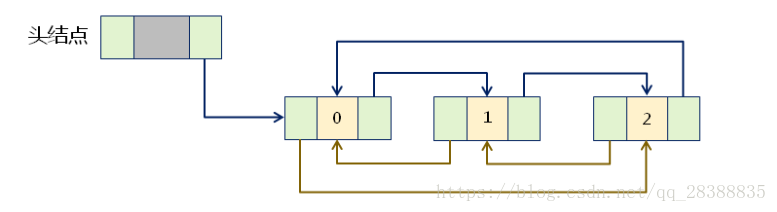
实现思路:通过模板定义DualCircleList类,继承自DualLinkList类;
在DualCircleList内部使用Linux内核链表进行实现;
使用struct list_head定义DualCircleList的头结点;
特殊处理:循环遍历时忽略头结点
实现要点:
1、通过list_head进行目标结点定位(position(i));
2、通过list_entry将list_head指针转换为目标结点指针;
3、通过list_for_each实现int find(const T& e)函数;
4、遍历函数中的next()和pre()需要考虑跳过头结点。
将Linuxlist中的new操作符替换为node。














 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









