







 本文介绍了几种高效的数据存储和查找方法,包括平衡二叉树、散列表、布隆过滤器等,探讨了它们的工作原理、优缺点及应用场景。
本文介绍了几种高效的数据存储和查找方法,包括平衡二叉树、散列表、布隆过滤器等,探讨了它们的工作原理、优缺点及应用场景。
从海量数据中查询某个字符串是否存在?
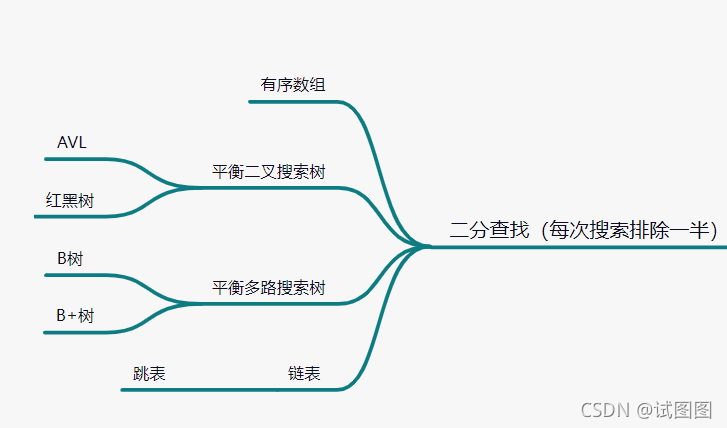
平衡二叉树
| 增删改查时间复杂度为 平衡的目的是增删改后,保证下次搜索能稳定排除一半的数据; 通过比较保证有序,通过每次排除一半的元素达到快速索引的目的。
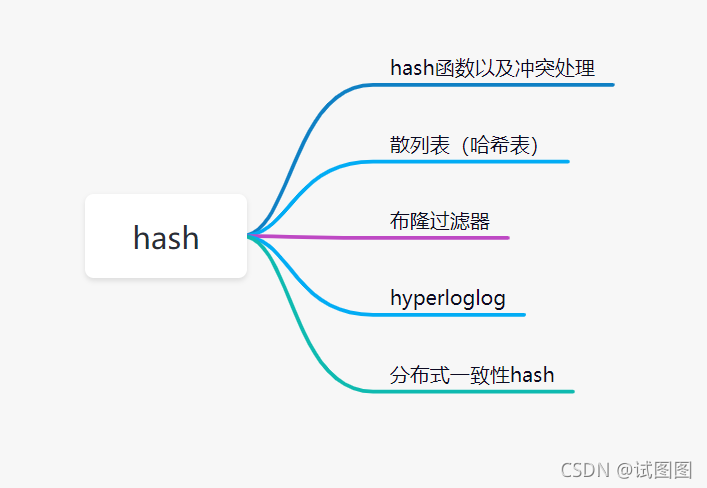
散列表根据 key 计算 key 在表中的位置的数据结构;是 key 和其所在存储地址的映射关系; 注:其中K\V存储在一起; hash函数 哈希函数可能会把两个或两个以上的不同key映射到同一地址,这种情况称为哈希冲突(哈希碰撞); 选择哈希
负载因子
冲突处理
引用链表来处理哈希冲突;也就是将冲突元素用链表链接起来;这也是常用的处理冲突的⽅ 式;但是可能出现一种极端情况,冲突元素比较多,该冲突链表过长,这个时候可以将这个链表转换为红黑树;由原来链表时间复杂度 转换为红黑树时间复杂度 ;那么判断该链表过长的依据是多少?可以采⽤超过 256(经验值)个节点的时候将链表结构转换为红黑树结构;
将所有的元素都存放在哈希表的数组中,不使用额外的数据结构;一般使用线性探查的思路
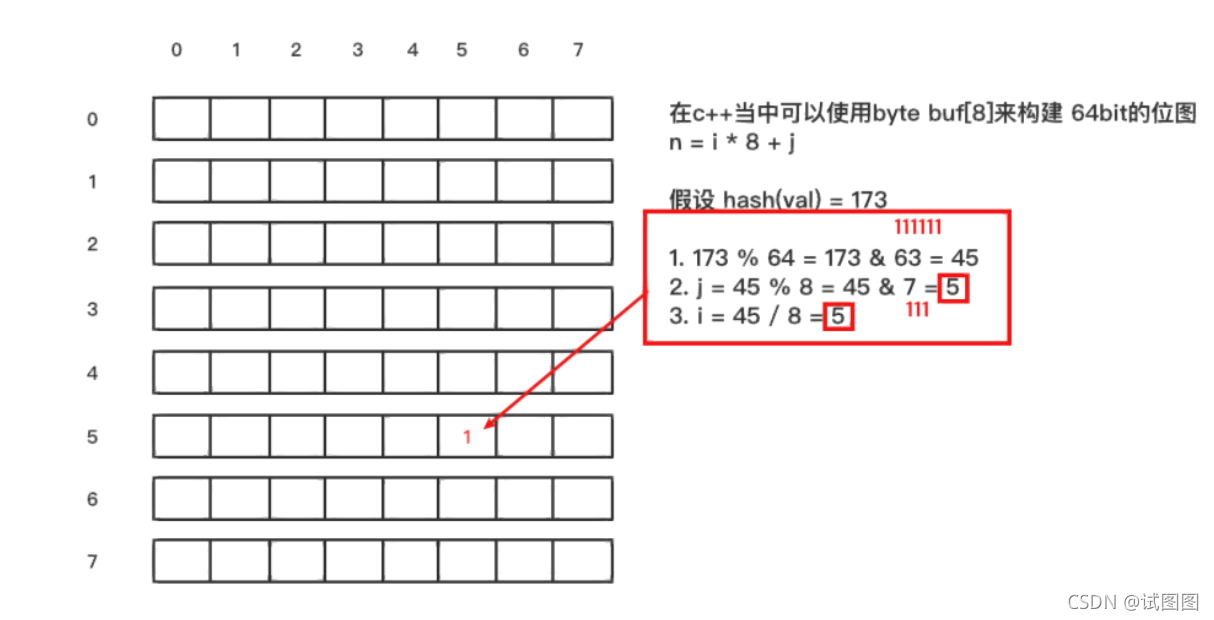
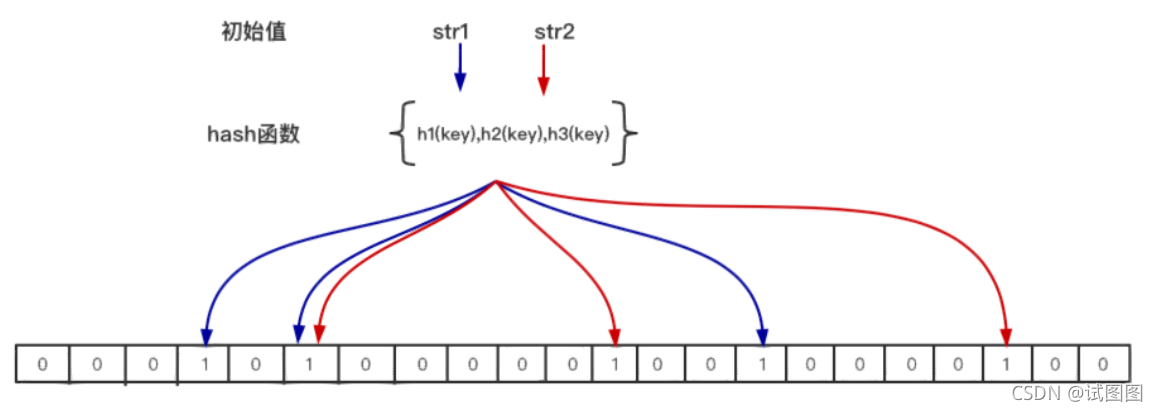
布隆过滤器布隆过滤器是一种概率型数据结构,他的特点是高效地插入和查询,能确定某个字符串一定不存在或者可能存在。 布隆过滤器不存储具体数据,占用空间小,查询存在可控误差,同时不支持删除操作。 构成位图(BIT数组)+ n个哈希函数
原理当一个元素加入位图时,通过k个哈希函数将这个元素映射到位图的k个点,并把他们置位1; 当检索时,再通过k个哈希函数运算检测位图k个点是否都为1;如果有不为1的点,那么认为该key不存在;如果全部为1,则可能存在。 在位图每个槽位只有两个状态(0或1),一个槽位被设置为1状态,但不确定它被设置了多少次;也就是不知道多少个哈希映射而来以及具体是被哪个哈希函数映射而来。
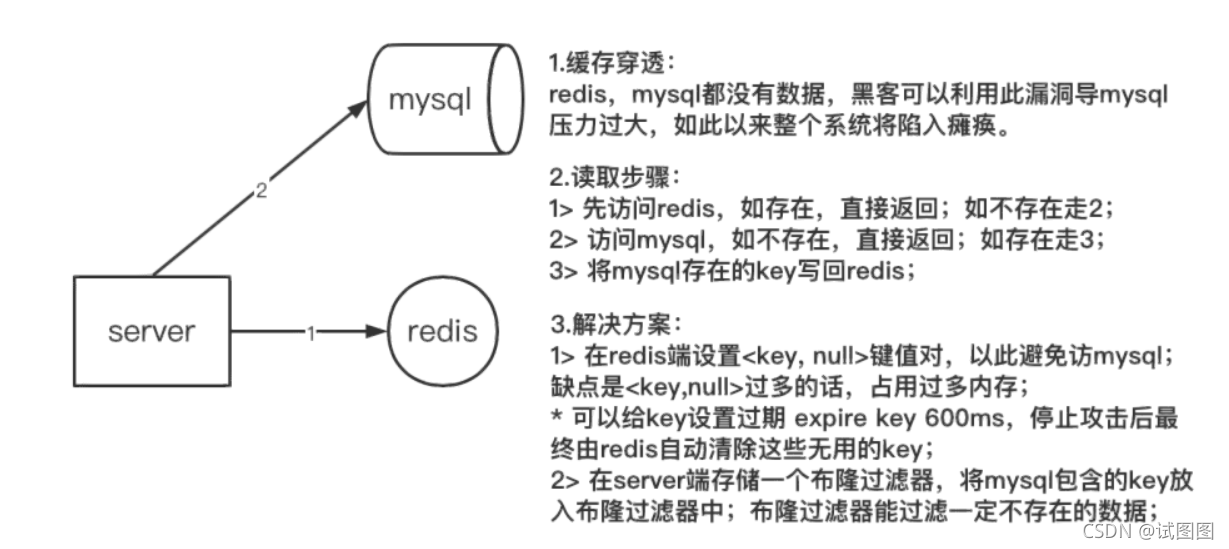
应用场景布隆过滤器常用于判断某个key一定不存在的场景,同时允许判断存在时有误差的情况; 常见处理场景:
应用分析在实际应用中,选择多少哈希函数?分配多少位图空间?预期存储多少元素?如何控制误差? n--预期布隆过滤器中的元素个数; 公式如下: | ; |


















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









