







String字符串
存储类型
- INT整型
- float 单精度浮点数
- String 字符串
存储(实现)原理
以 set KeyWord ValueWord为例
- KeyWord是一个字符串,redis自己实现了一个字符串类型为SDS,所以KeyWord指向一个SDS结构
- ValueWord:Redis并没有直接使用SDS存储,而是存储在redisObject中,然后redisObject再通过一个指针指向实际的数据结构
typedef struct redisObject{
unsigned type:4;//对象类型:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET
unsigned encoding:4;//具体的数据结构
unsigned lru:LRU_BITS;//24位,对象最后一次被命令访问的时间,与内存回收无关
int refcount;//引用计数 为0时 可以进行垃圾回收
void *ptr;//指向对象实际的数据结构
}robj;
所以*ptr会指向一个SDS
KeyValue会有三种不同的编码
- int 存储8个字节的长整型
- embstr 代表embstr格式的SDS,存储小于44个字节的字符串 (只读)
- raw 存储大于44个字节的字符串,如果embstr编码类型修改过,则变成raw,所以长度小于44字节,也可能是raw,因为embstr修改后会变成raw
SDS结构
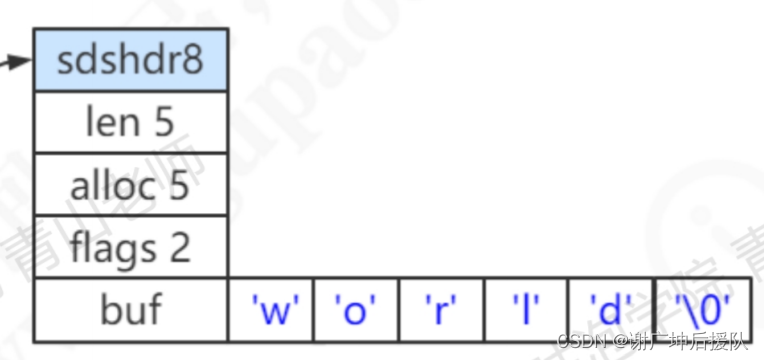
为什么使用SDS
C语言本身没有字符串类型,只能用字符数组char[]实现,char[]有以下问题
- 使用字符串数组必须先给目标变量分配足够的空间,否则可能会溢出
- 如果要获取字符串长度,必须遍历字符串数组,时间复杂度O(n)
- C字符串长度的变更会对字符数组做内存重分配
- 通过从字符串开始到结尾碰到的第一个’\0’来标记字符串的结束,因为不能保存图片、音频、视频、压缩文件等二进制保存的内容,二进制不安全
SDS的特点
- 不用担心内存溢出的问题,如果需要会对SDS进行扩容
- 获取字符串长度时间复杂度为O(1),因为定义了len属性
- 通过“空间预分配”和“惰性空间释放”,防止多次重分配内存
- 判断是否结束可以结合len属性和 通过判断’\0’,可以保存文本或者二进制数据
为什么要对底层数据结构用redisObject包装一层?
因为无论是设计redisObject,还是对存储字符设计这么多的SDS,都是为了根据存储的不同内容选择不同的存储方式,这样可以尽量的节省内存空间和提升查询速度
应用场景
- 缓存热点数据(明星橱柜、网站首页、报表数据等)
- 分布式锁
- 全局ID 利用原子性incrby
- 计数器:incr 文章阅读量、微博点赞数
- 限流:访问者ip做key
Hash 哈希
存储类型
存储多个无序键值对 最大存储数量 40亿左右 2^32-1 个
存储(实现)原理
内层的哈希底层使用两种数据结构实现
- zipList:OBJ_ENCODING_ZIPLIST(压缩列表)
- hashtable:OBJ_ENCODING_HT(哈希表)
ziplist:压缩列表,是一个经过特殊编码的,由连续内存块组成的双向链表,它不存储只想上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,这样读写可能会慢一些,因为要计算长度,但是可以节省内存,是一种时间换空间的思想
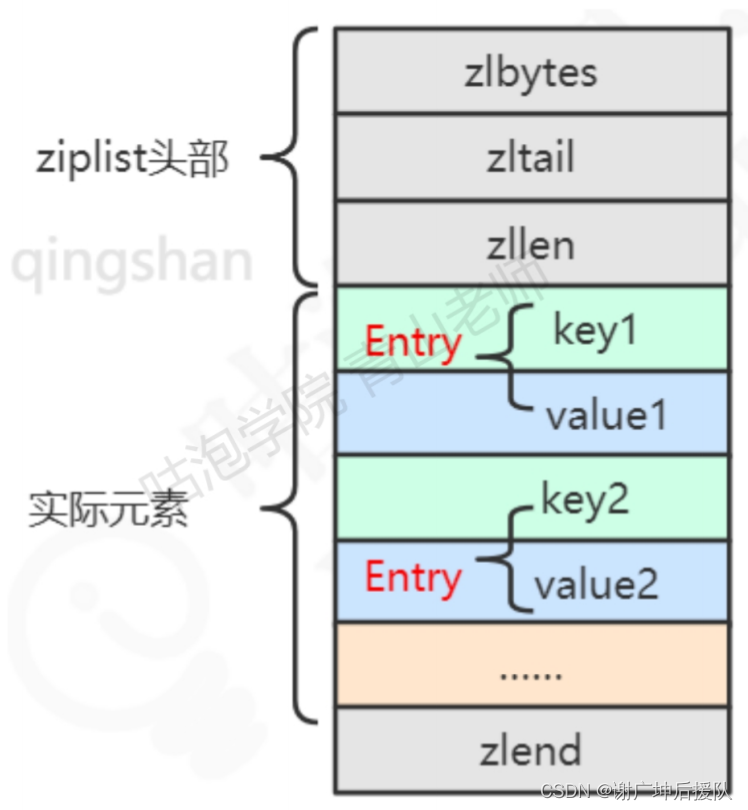
typedef struct zlentry{
unsigned int prevrawlensize;//存储上一个链表节点的长度值所需要的字节数
unsigned int prevrawlen;//上一个链表节点占用的长度
unsigned int lensize;//当前链表节点长度数值所需要的字节数
unsigned int len;//当前链表节点占用的长度
unsigned int headersize;//当前链表节点的头部大小
unsigned int encoding;//编码方式
unsigned char *p;//指向当前节点的起始位置
}zlentry
什么时候使用ziplist存储?
当hash对象同时满足以下两个条件时,使用ziplist编码:
- 哈希对象保存的键值对数量<512个
- 所有键值对的键和值的字符串长度都<64byte
配置:src/redis.conf
hash-max-ziplist-value 64
hash-max-ziplist-entries 512
超过这两个阈值任何一个,存储结构就会转换成hashtable,所以字段个数少,字段值小用ziplist
应用场景
- String 类型能做的,Hash都能做
- 多一种经典场景:购物车,每件商品的value中 存储了 商品的 id、name、购买数量等,这样同一件商品的购买数量的增加||减少可以利用 hincrby key field -1 处理
List列表
存储类型
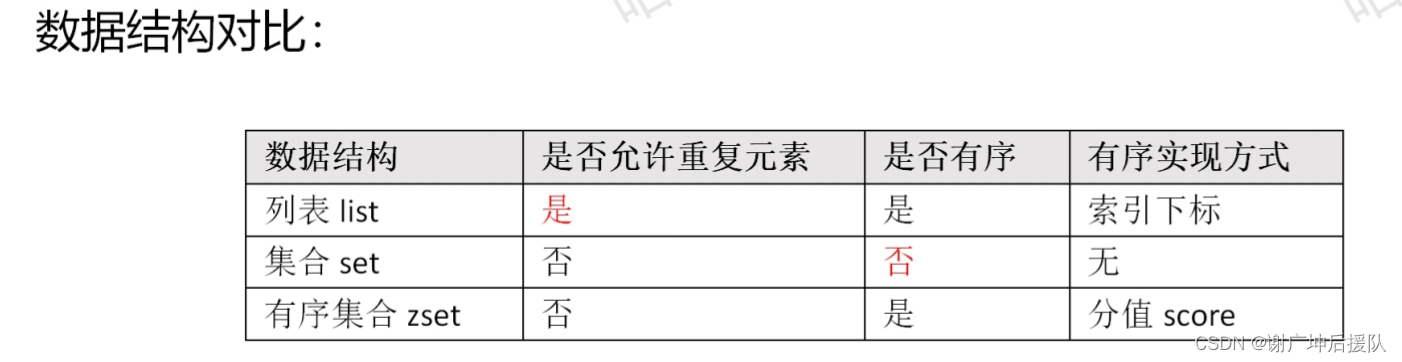
存储有序的字符串(从左到右),元素可以重复,最大存储数量2^32-1(40亿左右)

存储(实现)原理
3.2版本以后,统一用quicklist来存储,quicklist存储了一个双向链表,每个节点都是一个ziplist,所以是ziplist和linkedlist的结合体
typedef struct quicklist{
quicklistNode *head;//指向双向列表的表头
quicklistNode *tail;//指向双向列表的表尾
unsigned long count;//所有的ziplist中一共存了多少个元素
unsigned long len;//双向链表的长度 node的数量
int fill:QL_FILL_BITS;//zipList最大大小 对应list-max-ziplist-size
unsigned int compress:QL_COMP_BITS;//压缩深度 对应list-compress-depth
unsigned int bookmark_count:QL_BM_BITS;//bookmarks数组的大小
quicklistBookmark bookmarks[];//
}quicklist
quicklist就是一个 数组+链表的结构
应用场景
主要是存储有序内容的场景
- 用户消息列表、网站公告列表、活动列表、博客文章列表、评论列表
- 队列/栈使用
Set集合
存储类型
存储String类型的无序集合,最大存储数量2^32-1(40亿左右)
存储(实现)原理
用intset或hashtable存储set,如果元素都是整数类型就用 inset存储
typedef struct intset{
uint32_t encoding;//编码类型
uint32_t lenth;//长度
int_8 contents[];//存储成员的动态数组
}intset
如果不是整数类型,就用hashtable(数组+链表的存储结构)
应用场景
- 抽奖 spop myset 随机获取元素
- 点赞、签到、打卡
- 商品标签
- 商品筛选 获取差集、交集、并集 等
- 用户关注、推荐模型 -互相关注?-可能认识的人?
ZSet 有序集合
存储类型
sorted set 存储哦有序的元素,每个元素有个score,按照score从小到大排名,score相同时,按照key的ASCII码排序
存储(实现)原理
默认使用ziplist编码,在ziplist内部,按照score排序递增来存储,插入的时候要移动之后的书,如果元素大于等于128个,或者任一member长度大于64字节使用skiplist+dict存储
什么是skiplist(跳表)?
有点像二分查找
应用场景
顺序会动态变化的列表
- 百度热榜、微博热搜














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









