







正文
- 表、栈、队列:
表:
1.表的简单实现:数组。
2.为了避免插入和删除的线性开销,表可以不连续存储。
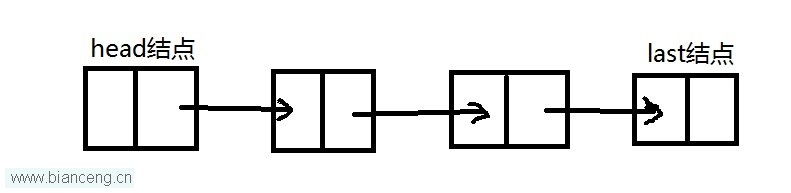
链表,由一系列节点组成,这些节点不必再内存中相连。每一个节点均含有表元素和到包含该元素后继元素的链,也称为next链。
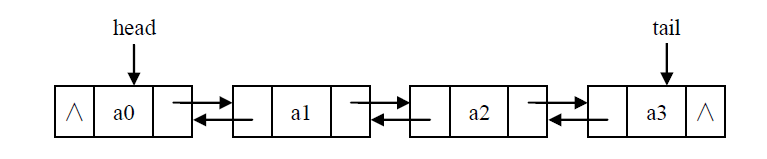
双链表,让每一个节点持有一个指向它在表中的前驱节点的链。
List类,ArrayList类和LinkedList类:
ArrayList与LinkedList对比:
1.ArrayList首先提供了List ADT的一种可增长数组的实现。其的优点在于,对get和set的调用花费常数时间,缺点是,新项的插入和现有项的删除代价敖贵,除非在ArrayList的末端进行。
2.LinkedList提供了List ADT的双链表实现。其优点在于,对新项的插入和现有项的删除均开销很小。但其缺点是他不容易做索引,对此get的调用是很昂贵的。
对于搜索而言,ArrayList和LinkedList都是低效的,对于Collection的contains和remove的调用均花费线性时间。
ArrayList的底层实现是数组。
LinkedList的底层实现是node节点。- 栈:是限制插入和删除只能在一个位置上进行的表,该位置在栈的末端,叫做栈顶。对栈的基本操作有push进栈和pop出栈。
栈的底层实现还是表,因此ArrayList和LinkedList都支持栈的操作。单链表也可实现。 队列ADT
像栈一样,队列也是表。树:对于大量的输入数据,链表的线性访问时间太慢,不宜使用。
- 二叉查找树:是两种库集合类TreeSet和TreeMap实现的基础。
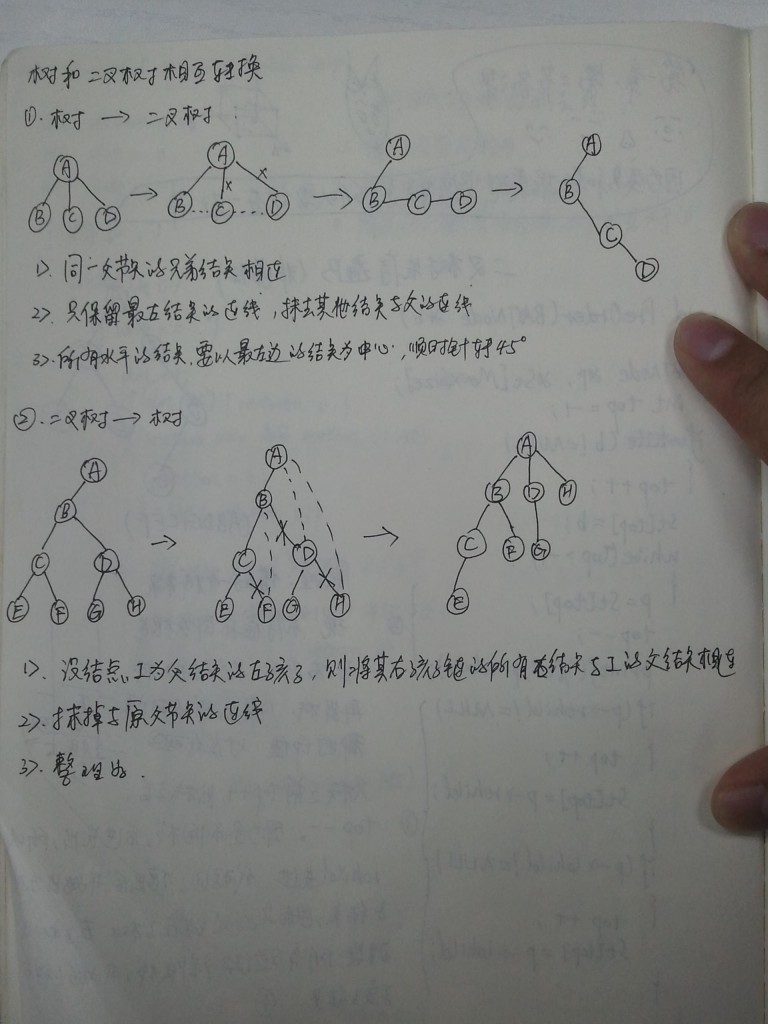
- 树的表现方式,递归。根和若干子树组成。实现树的方法可以事在每一个节点除数据外还要有一些链,使得该节点的每一个儿子都有一个链指向它。
- 遍历树的策略分先序遍历和后序遍历。
- 二叉树:其中每个节点都不能有多于两个的儿子。
Java常用数据结构总结
- ArrayList 和 Vector :
相同的:
1.都是采用数组方式存储数据
2.都允许直接序号索引元素
3.索引数据快,插入数据慢
不同点:
1.Vector使用synchronized方法(线程安全)性能差,时间慢
2.ArrayList使用双向链表实现存储,插入速度快 线性表,链表,哈希表
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
│├TreeSet
│├HashSet
Map
├TreeMap
├Hashtable
├HashMap
└WeakHashMap1.Collection:它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素
2.LinkedList:LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)
注:LinkedList**没有同步**方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(…));
使用情景:涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素
3.ArrayList:和LinkedList一样,ArrayList也是非同步的(unsynchronized)
使用情景:需要快速随机访问元素
4.Vector:Vector非常类似ArrayList,但是Vector是同步的。但必须捕获ConcurrentModificationException异常
5.Stack : Stack继承自Vector,实现一个后进先出的堆栈
6.Set : Set是一种不包含重复的元素的Collection
6.1.TreeSet:根据二叉树实现的,也就是TreeMap, 放入数据不能重复且不能为null,可以重写compareTo()方法来确定元素大小,从而进行升序排序。
7.Map : Map没有继承Collection接口,Map提供key到value的映射
8.Hashtable :Hashtable继承Map接口,实现一个key-value映射的哈希表,Hashtable是同步的。
9.HashMap : 和Hashtable类似,不同之处在于HashMap是非同步的
10.WeakHashMap:WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收
关于同步建议:在《Practical Java》一书中Peter Haggar建议使用一个简单的数组(Array)来代替Vector或ArrayList。尤其是对于执行效率要求高的程序更应如此。因为使用数组(Array)避免了同步、额外的方法调用和不必要的重新分配空间的操作。
11.树形数据结构:树结合了两种数据结构的有点:一种是有序数组,树在查找数据项的速度和在有序数组中查找一样快;另一种是链表,树在插入数据和删除数据项的速度和链表一样
12.二叉树 :二叉树的遍历有三种:先序、中序、后序,每种又分递归和非递归
Java常用数据结构总结
- SpareArray :SparseArrays map integers to Objects. Unlike a normal array ofObjects, there can be gaps in the indices. It is intended to be more efficientthan using a HashMap to map Integers to Objects
- 大概意思是SparseArrays是映射Integer—> Objects 类型的,就像这样: SparseArrays< Object>而且在指数级别的数量的增长上来说和HashMap相比较的话,性能方面SparseArrays更好
参考文章
http://blog.csdn.net/hunter4ever/article/details/6912693
http://blog.csdn.net/zhangerqing/article/details/8822476
http://blog.csdn.net/u011803341/article/details/52777959
http://poarry.blog.51cto.com/5970996/1633205/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









