






1.第一行为文档声明:<?xml version="1.0" encoding="UTF-8"?>
2.标签有大小写区分
3.标签是通过属性来存取数据的:由于第一种与第二种格式解析不同,所以大家要统一才可以。
例如 <students>
<student id="1" ><!--第一种属性-->
</student>
<student>
<id><!--第二种属性-->
2
</id>
</student>
</students>
students
| student | 1 |
| student | 2 |
和数据库十分相似!!!!!!!!!
由于大家方式不同,于是有了一种叫做 DTD 或者 Schma 的约束,防止格式不同。
xml的应用是保存任意不规则的数据。
解析XML
基于DOM(指倒立的节点数)见下图
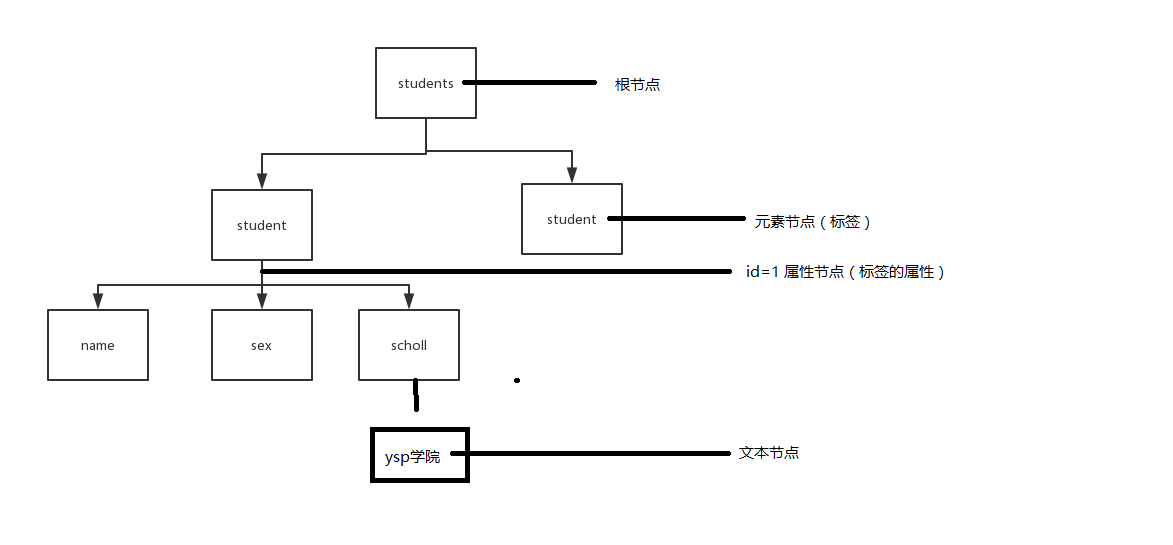
注意: 元素节点 类型为 1
属性节点类型为2
文本节点类型3
当你得到节点类型 getNodeType时显示的是 1 2 3;
注意 编写标签时 一个换行为一个空节点(元素节点的数量);
比如说
<student></student> 元素节点数量为0
<student>
</student> 元素节点数量为1
以下为一段代码:
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// TODO Auto-generated method stub
String xml="src/NewFile.xml";
//需要有一个解析器,但是解析器的的构造函数无法调用,于是用工厂模式来。
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();//用工厂模式实例化解析器
//加载要解析的文档;
Document doc = builder.parse(xml);
//开始解析文档 获取根节点,以根节点为中心来处理数据
org.w3c.dom.Element root = doc.getDocumentElement();
System.out.println(root.getNodeType());
// NodeList list1=root.getChildNodes(); //返回的类型为一个list集合 不推荐这种浏览方式
// System.out.println(list1.getLength());
NodeList list=root.getElementsByTagName("student");//将student下元素节点全部都传给 list
for (int i = 0; i < list.getLength(); i++) {
Element node=(Element) list.item(i);
System.out.println(node.getAttribute("id"));//只有文本节点才可以使用 node.getNodeValue();
}
}
最后也是最重要的一条:解析XML得到的数据就是为了要处理所以需要设计一个符合XML的类来接收数据
接下来是关于查找数据
这是查找的数据
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1" name="ysp" school="google">
<id>2</id>
<name>lsh</name>>
<school>ysp学院</school>
</student>
</students>
查找的方法:
NodeList list=root.getElementsByTagName("student");//将student下元素节点全部都传给 list
System.out.println(list.item(0).getTextContent());
结果:
2
lsh>
ysp学院
结论:getTextContent()得到该标签下所有标签的值
NodeList list=root.getElementsByTagName("student");//将student下元素节点全部都传给 list
for (int i = 0; i < list.getLength(); i++) {
Element node=(Element) list.item(i);
String id = node.getAttribute("id");
System.out.println(id);
}
结果:9
结论:String id = node.getAttribute("id");得到属性的值
总体:
NodeList list=root.getElementsByTagName("student");//将student下元素节点全部都传给 list
for (int i = 0; i <list.getLength(); i++) {
Element student=(Element) list.item(i);//f返回的是一个节点
String id=student.getAttribute("id");//访问属性
Element nameNode=(Element) student.getElementsByTagName("name").item(0);//访问标签
System.out.println(id);
System.out.println(nameNode.getAttribute("name"));
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









