







Hadoop是一个能够对大量数据进行分布式处理的软件框架,先来了解hadoop结构
| 组件 | 功能 |
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
分布式文件系统HDFS:
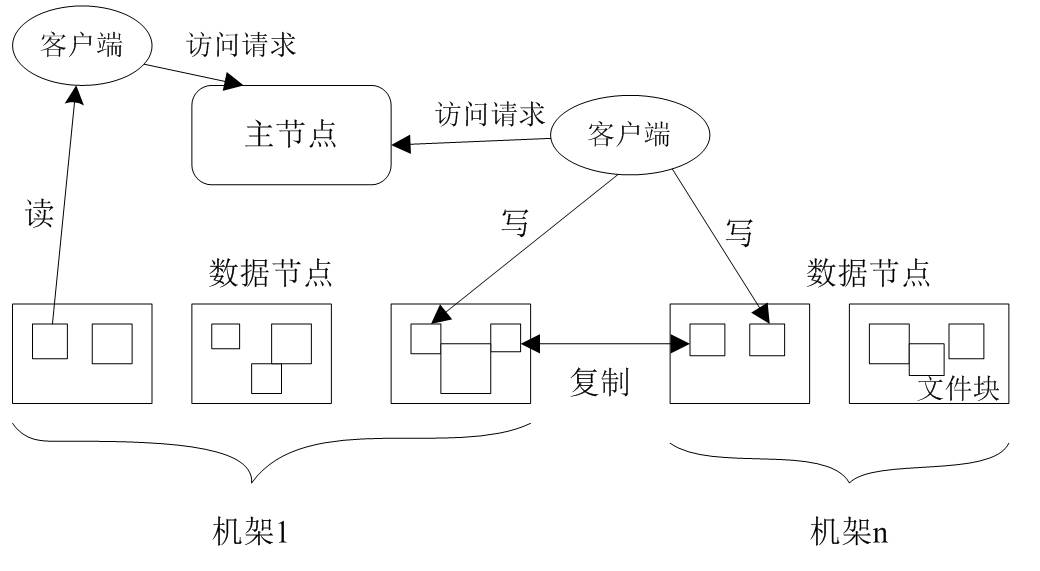
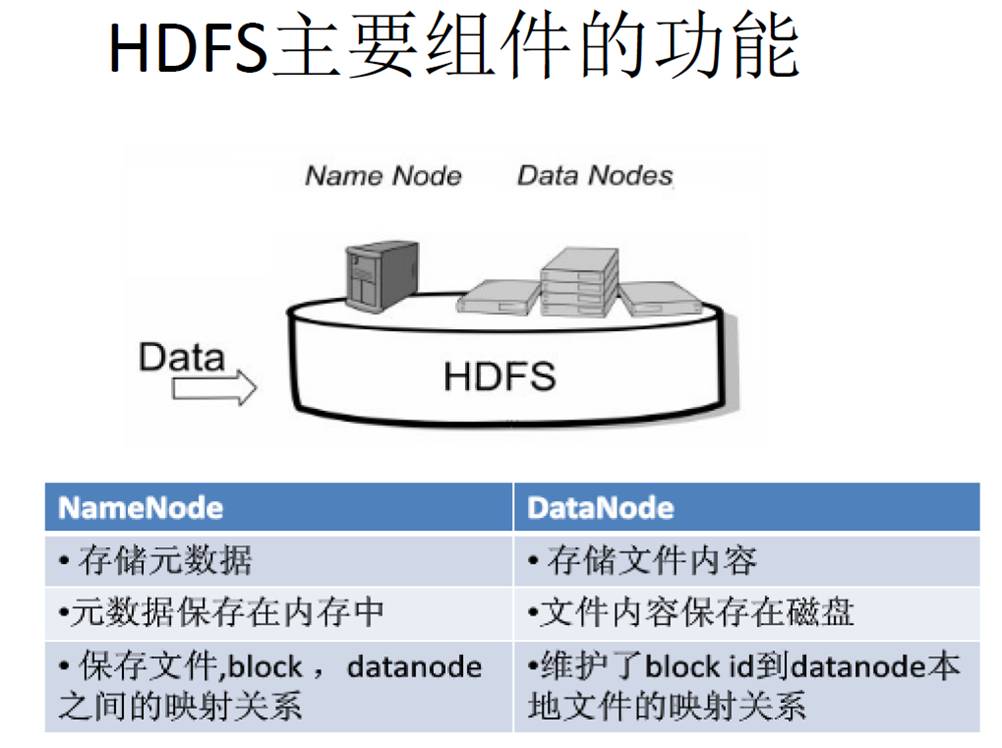
分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群,都是由普通的硬件设备组成,成本很低,分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)
hdfs:
兼容廉价的硬件设备
流数据读写
大数据集
简单的文件模型
强大的跨平台兼容性
有优点的同时也存在一些局限性
不适合低延迟数据访问(低延迟可采用hbase)
无法高效存储大量小文件
不支持多用户写入及任意修改文件
HDFS存取文件是通过块的方式来存取文件,将文件写在HDFS会把文件按块来划分,
HDFS默认一个块128MB,一个文件被分成多个块,以块作为存储单位
块的大小远远大于普通文件系统,可以最小化寻址开销,块的大小可以进行配置,配置地址:

nameNode 和 DateNode 的地址,在hdfs-site.xml 文件中 ,配置,其中dfs.name.dir是元素据nameNode 的存放地址,dfs.data.dir 是DateNode 的存放地址

解决:SecondaryNameNode 第二名称节点
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上
DataNode

通过TCP/IP进行传输的分布式文件存储系统
这里说一下 HDFS采取的是冗余数据保存

配置的时候如果配置是1,只会在一台机器上存数据,其他机器上没有数据,(伪分布式)HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上,数据块1被分别存放到数据节点A和C上,数据块2被存放在数据节点A和B上,这样会加快数据的传输速度
在数据存放的时候
另外可以配置HDFS的地址端口,通过 core-site.xml 中

读取:
val filePath = "hdfs://10.20.30.91:8020/app*.log"
val bankText = sc.textFile(filePath)
写:
String filename = " hdfs://10.20.30.91:8020/app.log "; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
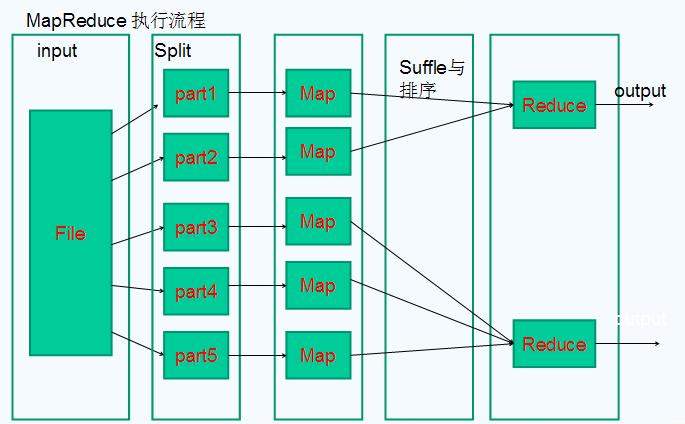
mapduce:
首先给大家看几张图:
这是mapreduce的运行机制图
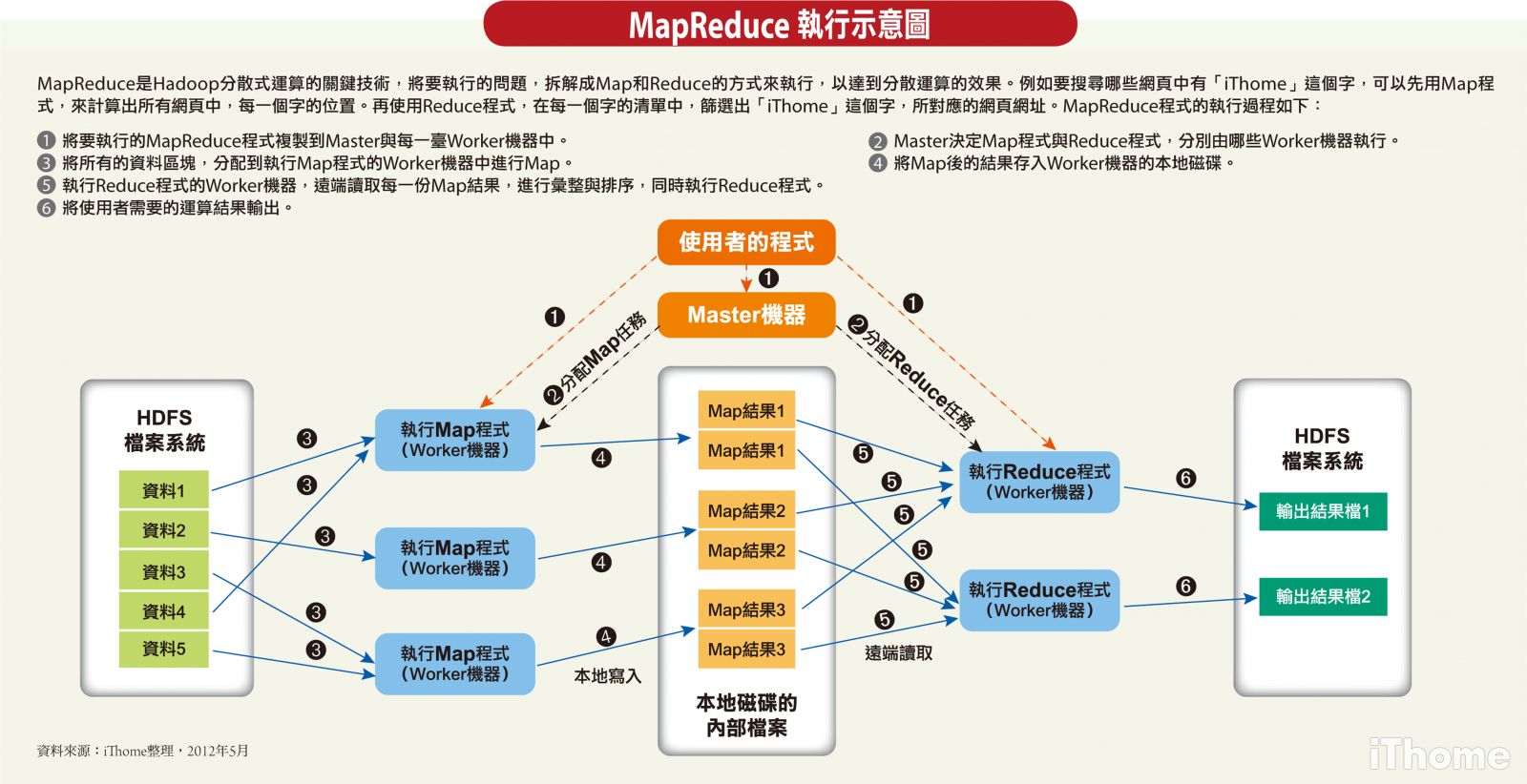
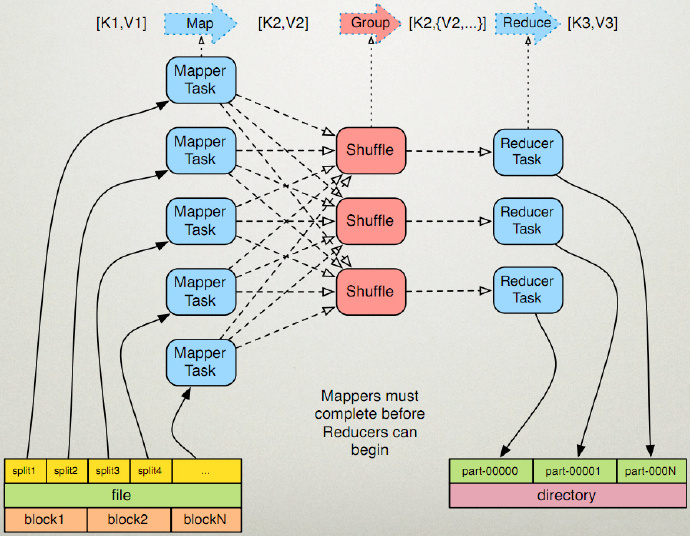
开始讲一下我的理解
mapduce是一个计算框架,有输入有输出,mapduce 分为map 和duce
一个比较形象的语言解释MapReduce:
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes.
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
Now we get together and add our individual counts. That’s reduce.
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
mapduce 将数据进行分区,每一个分区交给一个map去处理,处理之后,再交给duce 进行整合
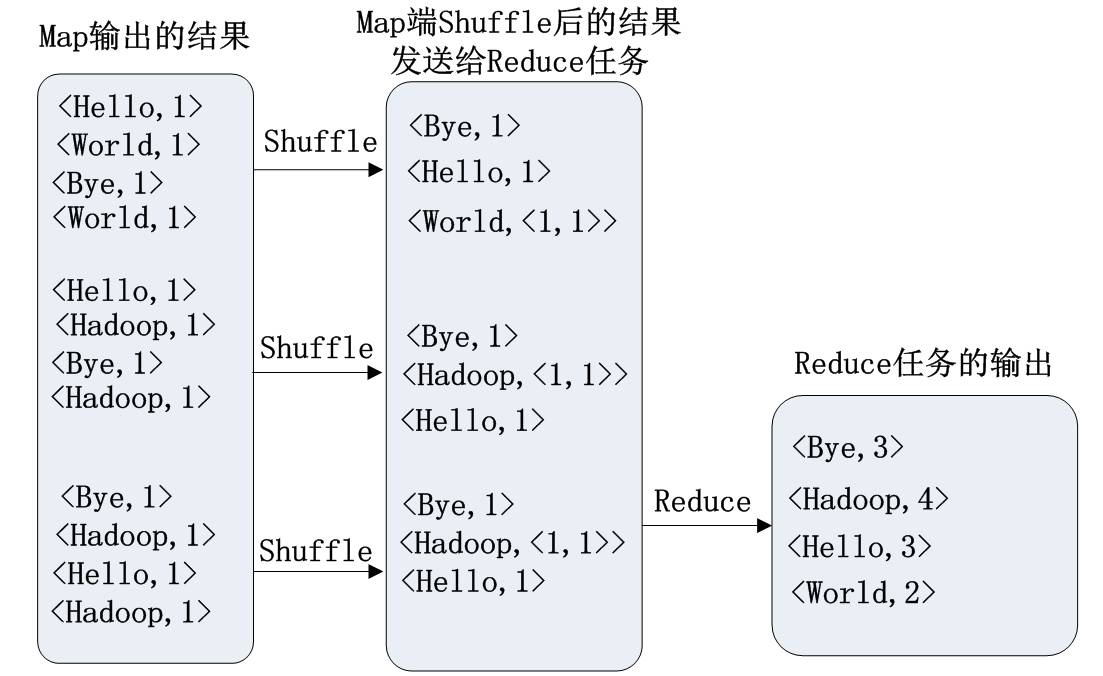
WordCount程序任务

待更新















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









