







记录一下,我从百度飞桨深度学习学院 《强化学习7日打卡营-世界冠军带你从零实践》,了解到的东西吧。。。
这不是按键精灵,靠颜色判断来打怪
这不是游戏辅助,用内存读写来刷图
而是真正的让AI学会玩游戏。。。
这就叫做-强化学习
什么是强化学习
- 强化学习(英语:
Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。 - 核心思想:智能体
agent在环境environment中学习,根据环境的状态state(或观测到的observation),执行动作action,并根据环境的反馈reward(奖励)来指导更好的动作。
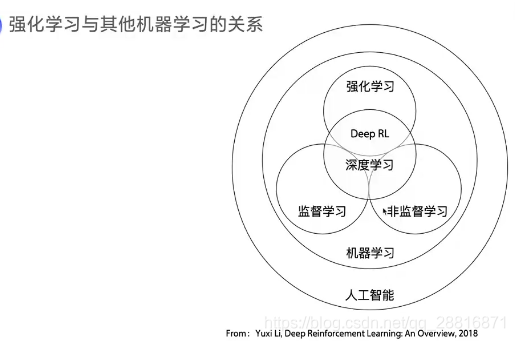
课程中用到的是如下利器:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









