









目录
摘要
解剖标志的检测是医学图像分析和诊断、解释和指导应用的重要步骤。
对地标进行手工注释是一个乏味的过程,需要特定领域的专业知识,并引入观察者之间的可变性。本文提出了一种基于多智能体强化学习的多地标的检测方法。
我们的假设是,在人体解剖学中,所有解剖地标的位置都是相互依赖的和非随机的,因此找到一个地标可以帮助推断其他地标的位置。
利用深度Q-网络(DQN)架构,我们构建了一个具有隐式相互通信的环境和代理,这样我们就可以容纳K个代理同时行动和学习,同时它们尝试检测K个不同的地标。
在培训期间,代理们通过分享他们积累的知识来进行集体合作。
我们将我们的方法与最先进的架构进行了比较,与减少50%的检测误差相比,需要更少的计算资源和更少的训练时间。代码和可视化可用: https://github。com/thanosvlo/MARL-for-Anatomical-Landmark-Detection
介绍
医学图像中解剖标志的精确定位是许多临床应用的关键要求,如图像配准和分割以及计算机辅助诊断和干预的应用。
例如,为了规划心脏干预措施,有必要确定心脏的标准化平面,例如短轴和2/4室视图[1]。
它在产前胎儿筛查中也起着至关重要的作用,它被用来估计生物特征测量,如胎儿生长速率,以识别病理发育[17]。
此外,通常用于脑图像配准和评估异常情况的中矢状面,是根据前接合(AC)和后接合(PC)[2]等标志物来识别的。
人工标注地标通常是一项耗时和乏味的任务,需要大量的解剖学方面的专业知识,并存在观察者内部和观察者内部的错误。
另一方面,自动方法的设计也具有挑战性,因为不同器官的外观和形状变化很大。
贡献
这项工作提出了一种新的多代理强化学习(MARL)方法,通过共享代理的经验,有效地和同时检测多个地标。
主要贡献可以总结为:
(i)我们介绍了MARL框架中多重地标检测问题的新公式;
(ii)提出了一种新的协作深度量子网络(DQN),用于使用代理之间的隐式通信进行训练;(iii)对不同数据集进行广泛的评估,并与最近发表的方法(决策森林、卷积神经网络(CNNs)和单代理RL)进行比较。
相关工作
在文献中,自动地标检测方法采用了机器学习算法来学习基于外观和基于图像的组合模型,例如使用回归森林[16]和统计形状先验[6]。
Zheng等人[19]提出使用两个cnn进行地标检测;第一个网络通过提取候选位置来学习搜索路径,第二个网络通过对候选图像块进行分类来学习识别地标。
Li等人[13]提出了一种基于补丁的迭代CNN,可以同时检测单个或多个地标。
Ghesu等人[8]引入了一个单一的深度RL代理,以在3D图像中导航到目标地标。
人工代理学习在RL场景中有效地搜索和检测地标。该搜索可以使用固定的或多尺度的步骤策略[7]来执行。
Alansary等人[2]提出使用不同的深度q网络(DQN)架构使用新的层次动作步骤进行地标检测。
代理学习一个最优策略,使用3D图像(环境)中的顺序操作步骤从任何起点导航目标地标。
在[2]中,报告的实验表明,这种方法可以实现最先进的结果,以检测来自不同的数据集和成像模式的多个地标。然而,这种方法被设计为为每个地标分别学习单个代理。
在[2]中,也表明不同策略和结构的性能强烈地依赖于目标地标的解剖位置。因此,我们假设,在尝试同时检测时共享信息,减少了上述依赖性
方法
在[8]和[2]的工作基础上,我们将地标检测的公式扩展为马尔可夫决策过程(MDP),其中人工代理学习针对其目标地标的最优策略,这定义了一个并发的部分可观察马尔可夫决策过程(co-POMDP)[9]。
我们认为我们的框架是并发的,因为代理一起训练,但每个人都学习自己的个人政策,将其私人观察映射到一个个人行动[10]。
我们假设这是必要的,因为不同地标的定位需要学习部分异构的策略。这对于集中式学习系统的应用是不可能实现的。
我们的RL框架是由环境的状态、主体的行为、它们的奖励功能和终端状态来定义的。
我们认为环境是一个人体解剖学的三维扫描,并将一个状态定义为一个以代理位置为中心的感兴趣区域(ROI)。这使得我们的公式成为一个POMDP,因为代理只能看到环境[11]的一个子集。
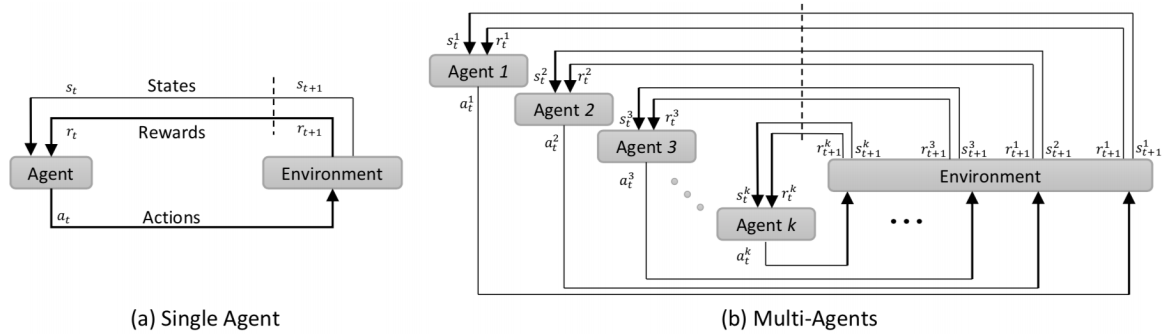
图1: (a)单个代理和(b)多代理在RL环境中交互
我们将帧历史定义为由四个roi组成。
在这个设置中,每个代理都可以沿着x、y、z轴移动,从而创建一组六个动作。
在我们的多智能体框架中,每个智能体在他们的策略不相交时计算其单独的奖励。
在训练过程中,我们认为当代理到达距离目标地标1mm以内的区域时,搜索已经收敛。
在训练和测试中都引入了情景游戏。
在训练中,情节被定义为代理需要找到地标的时间,或者直到他们完成了预定义的最大步数。
如果一个代理比所有其他代理先发现它的里程碑,我们将冻结训练并禁用从该代理派生的网络更新,同时允许其他代理继续探索环境。
在测试期间,当代理开始在一个位置周围振荡或超过定义的最大帧数时,我们终止事件。
协作代理
[2]、[7]和[8]以前处理地标检测问题的方法认为是单一代理寻找单一地标。
这意味着需要用代理的单独实例来训练进一步的地标,这使得大规模的应用不可行。
我们的假设是,在人体解剖学中,所有的解剖地标的位置都是相互依赖的和非随机的,因此找到一个地标可以帮助推断出其他地标的位置。
当使用隔离的代理时,没有利用这些知识。
因此,为了减少定位多个地标的计算负荷,并通过解剖相互依赖提高精度,我们提出了一个协作的多智能体地标检测框架(Collab-DQN)。
为了简单地表示,下面的描述将只假设两个代理。然而,我们的方法可以扩展到K个代理。在我们的实验中,我们使用两个、三个和五个一起训练的代理来进行评估。
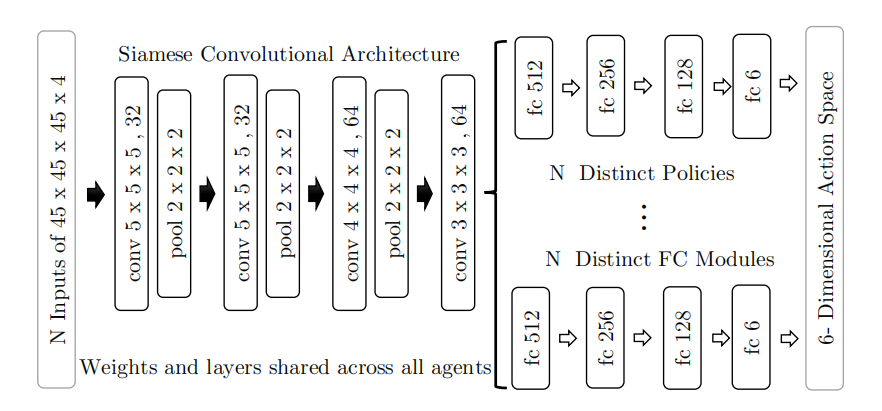
图2:两个代理情况下提出的协作DQN;卷积层和相应的权值在所有代理之间共享,使它们成为暹罗架构的一部分,而每个代理的完全连接层是独立的
一个DQN由三个卷积层与最大池层交错,然后是三个完全连接的层组成。受暹罗架构[3]的启发,在我们的Collab-DQN中,我们构建了K个DQN网络,其权重在卷积层之间共享
全连接层保持独立,因为这些将作出最终的行动决定。通过这种方式,浏览环境所需的信息被编码到共享层中,而地标特定信息则保留在完全连接的层中。在图2中,我们以图形化的方式表示了两个代理的建议体系结构。在卷积层之间共享权值有助于网络学习更广义的特征,可以拟合两个输入,同时在参数中添加隐式正则化,避免过拟合。共享的权重使得在代理之间的参数空间中可以间接地转移知识,因此,我们可以将该模型视为协作学习[10]的一个特殊情况。
实验
数据集
我们在三个任务上评估了我们提出的框架和模型:
(i)728个训练和104个检测量[12]的脑MRI地标检测;
(ii)364个训练和91个检测量[14]的心脏MRI地标检测;
(iii)51个训练和21个测试量的胎儿脑超声地标检测。
每个模式包括7-14个解剖真实地标位置,由专家临床医生[2]注释。
训练
在训练过程中,从体积的内部80%中选择一个初始随机位置,以避免在有意义的区域之外进行采样。
初始ROI是在随机选择的点周围的45×45×45像素。
代理遵循![]() -贪婪探索策略,每隔几个步骤它们就从均匀分布中选择一个随机动作,而在剩下的步骤中它们则贪婪地行动。情景学习,并为已经达到终端状态的代理添加冻结动作更新,直到情节结束,详见第2节
-贪婪探索策略,每隔几个步骤它们就从均匀分布中选择一个随机动作,而在剩下的步骤中它们则贪婪地行动。情景学习,并为已经达到终端状态的代理添加冻结动作更新,直到情节结束,详见第2节

表1:脑MRI和胎儿脑超声的结果,以毫米为单位。我们提出的Collab DQN在所有情况下都表现更好,除了CSP,我们匹配单个代理的性能。
测试
对于每个代理,我们固定了19个不同的起点,以便在不同的方法之间进行公平的比较。这些点用于每个模式的25%,体积大小的50%和75%的所有测试体积。
对于每个体积,每19次运行的结束位置和目标位置之间的欧氏距离取平均值。以mm为单位的平均距离被认为是药剂在特定体积中的性能。使用我们提出的体系结构已经执行了多个测试。
并与多尺度RL地标检测[7]、全监督深度卷积神经网络(CNN)[13]以及单代理DQN地标检测算法[2]的性能进行了比较。在心脏标志物方面,我们与利用决策森林的[16]进行了比较。不同的DQN变体,如Double DQN 或 Duelling DQNs没有被评估,因为它们的表现对[2]中所显示的解剖标志检测任务几乎没有改善。
尽管我们的方法在有足够计算能力的情况下可以扩展到K agents,但我们将比较限制在大脑的前连合(AC)和后连合(PC);心脏的尖点(AP)和二尖瓣中心(MV);右小脑(RC)、左小脑(LC)和透明腔(CSP)。
这些都是常见的,有诊断价值的地标使用在临床实践和以前的自动地标检测算法。为了完整性和便于将来的比较,我们还提供了同时训练3个和5个代理的性能比较。在表1中,我们展示了使用不同方法的大脑MRI和胎儿脑US标志的表现。在表2中,我们展示了同时训练的3种和5种agent的结果以及心脏MRI标志物的结果。
讨论
如表1和表2所示,我们提出的方法在地标检测方面显著优于目前的最先进技术。来自所有实验的一个配对的student-t test检验的p值都在0.01到0.0001的范围内。我们通过训练单个代理的双重迭代实例和双倍的批量大小来进行消融研究。这项研究是在心脏MRI标志上进行的,这些标志显示出最大的定位困难,因为在受试者之间的解剖差异比在大脑数据中观察到的更大。我们的结果证实了代理之间共享基本信息,这有助于它们更有效地执行任务。
我们的假设是,从多智能体系统的经验和知识中收集的正则化效应是有利的。
此外,我们创建了一个具有加倍内存的单一代理,但由于经验内存的随机初始化,该代理无法学习。
此外,如表2(a)所示,包含更多的agent会导致所有标志物的相似或改进的结果。
值得注意的是,尽管我们在所有地标中都表现得更好,但我们的方法只能匹配CSP地标的单个代理DQN的性能。
我们的理论认为,这是由于RC、LC标志与CSP标志的解剖性质不同,因此联合检测没有优势。
在本文中,我们选择使用DQN,而不是现有的策略梯度方法,如A3C,因为DQN是由一个单一的深度CNN表示的,该CNN与单个环境交互。
A3C使用了许多异步和并行交互的代理实例。
多个A3C代理和这样的环境的计算上是昂贵的。
在今后的工作中,我们将研究使用协作或竞争代理进行多地标检测的应用。
计算性能
同时训练多个代理不仅有利于地标定位的性能,还减少了训练的时间和记忆需求。
与两个和三个独立网络的参数相比,在卷积层之间共享权重有助于使可训练参数减少5%,三个代理的可训练参数分别减少6%。
此外,与单个独立代理相比,在我们的架构中添加单个代理可以减少所需的参数数量的6%。
由于正的正规化效应,多个代理在他们的训练和隐式知识转移,我们的方法需要的平均训练时间25.000-50.000少时间步骤收敛与一个DQN和每个训练时代需要大约30分钟不到两个时代的训练在一个单独的DQN(NVIDIA Titan-X,12 GB)。推理与单一代理在∼20fps。
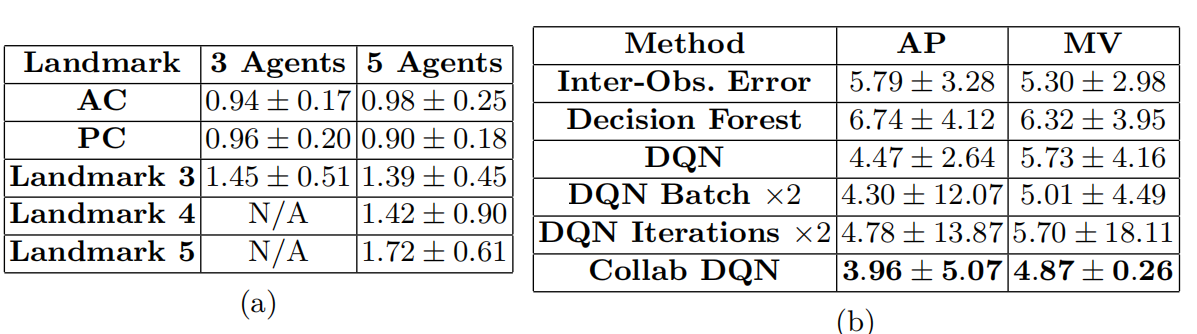
表2:(a)在脑MRI中进行多agent表现、训练和测试;标志3、4、5分别代表胼胝体压部的外侧、下尖和内侧;(b)多agent在心脏MRI数据集上的表现;
结论
本文将多重解剖地标检测问题表述为多智能体强化学习场景,并引入了CollabDQN,一种用于脑和心脏MRI体积和三维超声中地标检测的协同DQN。
我们一起训练K个代理来寻找K个地标。这些代理共享它们的卷积层权值。
通过这种方式,我们利用每个代理传递的知识来教授其他代理。
与次优方法相比[2]的性能,同时比连续训练K代理花费更少的时间和更少的内存。
我们相信,贝叶斯探索方法是一个自然的下一步,这将在未来的工作中得到解决。
脑MRI: adni.loni.usc.edu,
超声数据:仅在知情同意,经批准和正式的数据共享协议。
卡里达克数据: digital-heart.org。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









