






索引基本概念
数据库系统中文件索引的工作方式非常类似书本的索引,即可以在书本的索引定位章节并找到出现的页。
为了在数据库中检索一条给定ID的student数据,数据库系统会查找索引,找到相应记录的磁盘块,然后读取磁盘块得到所需的student记录。
但是用ID来实现student的索引是非常不合理的,这里引出了两个问题:
1.索引本身可能会非常庞大
2.当一名学生从数据库中被添加或被删除时候以ID为索引的这种数据结构也要相应的维护,而这个维护代价非常昂贵。
索引类型
1.顺序索引(ordered Index):基于值的顺序索引。
2.散列索引(hash index):基于将值平均分不到若干桶中。而一个值分配到哪个桶是由一个函数决定的。
而一个索引的创建必须基于下面的这些因素:
访问类型:能有效支持的访问类型。
访问时间:在查询中找到一个特定数据或者数据集所花费的时间。
插入时间:插入一个数据所花费的时间。
删除时间:删除一个数据所花费的时间。
空间开销:索引的数据结构所占用的空间。
顺序索引
顺序索引按照排好的顺序存储索引值,并将每个索引的值与对应的记录关联起来。一张表可以有多个索引,分别基于不同的属性。
如果索引的值还定义了对应数据的存储次序,那么这样的索引称为聚集索引。通过我们会看到拿主key当做索引值,这时候的主key构成的索引就是聚集索引。
如果索引的值次序与对应数据的存储次序不同,那么这样的索引称为非聚集索引。
| ID | NAME | DEPTH | SALARY |
|---|
通过一个例子来详细介绍顺序索引。我们先假定上述表结构的所有的数据都是按照某种索引顺序存储。
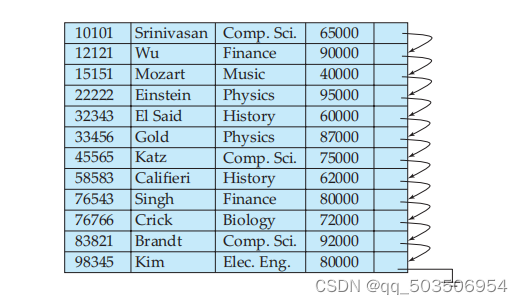
顺序索引可以对每个索引值都进行存储,每个索引值都对应该条记录的指针,通过指针我们能找到该条记录所存储的磁盘块和磁盘块内的对应偏移量。而这种每个索引值都存储的顺序索引称为稠密索引。
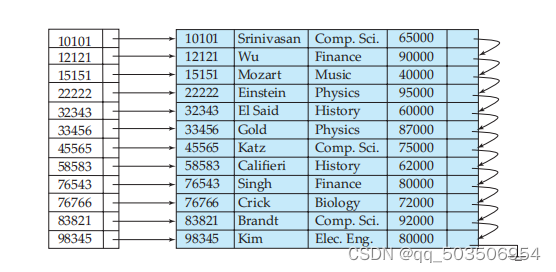
如上图,我们用第一列属性为ID(主Key)的字段作为索引进行稠密索引的创建。
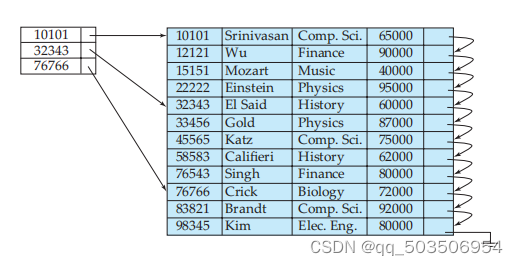
我们也可以只根据某些索引值创建索引,这种称为稀疏索引。
现在我们要查找一条ID为"22222"的数据,在稠密索引中我们顺着索引表马上能定位到相应的数据,而在稀疏索引中我们只能先定位到“10101”,读取了“10101”对应数据的磁盘块,我们再查找"22222"的数据。
可见在访问时间上稠密索引要比稀疏索引快,但稀疏索引占用的空间更小,并且维护索引结构的成本也更小(插入和删除)。
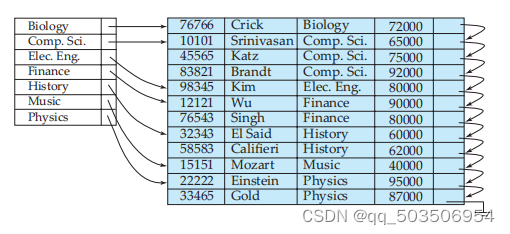
更常见的情况是我们用字母顺序而不是像ID这样的主Key来建立稀疏索引。
系统设计者必须在存取时间和空间开销之间进行权衡,这实际上就是选择使用稀疏索引还是稠密索引的问题。通常来说选择稀疏索引是一种较好的方案。原因在于,一个数据库的查询开销主要是由把磁盘块从磁盘读取到内存中所花费的时间来决定的。一旦我们把磁盘块读取到内存中,在内存内扫描磁盘块的时间是可以忽略不计的。
多级索引
假设我们的表有1000000条数据,而我们用100个索引值来构建稠密索引。在磁盘内保存100个索引值假设需要4KB的磁盘块。那我们将占用10000个块(大约是40MB的空间)。
假设我们的表有100000000条数据,而我们用1000000个索引值来稠密索引。在磁盘内保存100个索引值假设需要4KB的磁盘块。那我们将占用1000000个块(大约是4GB的空间)。
可以看出在数据量足够大的表中构建索引时会产生下面的问题:
1.索引的数据结构太大,没办法一次性将其从磁盘块中读取到内存内。哪怕能一次性读取到,内存也要花费过多开销在处理索引上,这会拖累计算机上其他任务的处理。
2.我们在对一个巨大的顺序索引进行块的读取时,哪怕使用二分法也依然要花很多时间。假如索引占据b个块,使用二分法平均也要读取log2(b)个块。
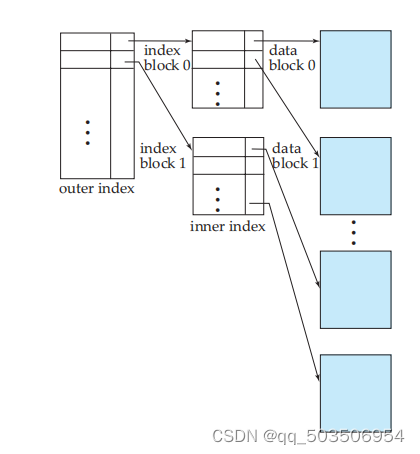
为了处理上述问题,我们调整索引的数据结构:在原始的索引上构造一个稀疏的外层索引。
回到开头的假设,100000000条数据的表索引占用1000000个块,我们给外层假设占用10000个块(大约是4MB的空间),这样我们的内存只需要读取40MB的外层索引,对外层索引进行二分查找找到内层块,再对内层块进行查找并找到对应数据。
B树索引
我们对多级索引的数据结构进行改造,将得到更加高效的数据结构B树。
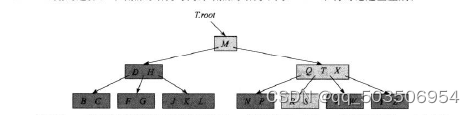
B树是一颗具有以下性质的有根树
1.每个结点x有下面属性
a. x.n,当前存储在结点x中的关键字个数
b. x.n个关键字本身x.key1,x.key2 … ,x.keyx.n以非降序存放,即x.key1<= x.key2<= … <=x.keyx.n
c. x.leaf为布尔值,如果x是叶结点,则为TRUE,如果是内部结点则为FALSE
2.每个内部结点x包含x.n+1个指向其孩子结点的指针x.c1,x.c2…,x.cx.n+1。叶节点没有孩子结点。
3.关键字x.keyi对存储在个子树的关键字范围加以分割:如果ki为任意一格存储在以x.keyi为根的子树中的关键字,那么
k1<=x.key1<=k2<=x.key2<=…<=x.keyn<=kn+1
4.每个叶子结点具有相同的树高度h
5.每个结点所包含的关键字个数具有上界和下界。用一个被称为B树的最小度数的固定整数t>=2来表示这个界。
a. 每个结点至少包含t-1个关键字
b. 每个结点至多包含2t-1个关键字
B的基本操作:创建
public class Node<T>
{
public bool leaf { get; set; }
public int n { get; set; } = 0;
public int[] key { get; set; }
public T[] data;
public Node<T>[] c { get; set; }
}
public class BTree<T>
{
public int t = 2;
public Node<T> Root { get; set; }
public BTree(int tValue)
{
t = tValue;
}
}
#region "磁盘操作"
/// <summary>
/// 为结点初始化对应的磁盘页
/// </summary>
/// <typeparam name="T"></typeparam>
/// <returns></returns>
private static Node<T> ALLOCATE_NODE<T>()
{
return new Node<T>()
{
leaf = true,
n = 0
};
}
/// <summary>
/// 磁盘写操作
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="node"></param>
private static void DISK_WRITE<T>(Node<T> node)
{
Console.WriteLine($"Do DISK_WRITE:{node}");
}
/// <summary>
/// 磁盘读操作
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="node"></param>
/// <returns></returns>
private static void DISK_READ<T>(Node<T> node)
{
Console.WriteLine($"Do DISK_READ:{node}");
}
#endregion
/// <summary>
/// B树创建
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="bTree"></param>
private static void B_TREE_CREATE<T>(BTree<T> bTree)
{
var x = ALLOCATE_NODE<T>();
var length = 2 * bTree.t - 1;
x.key = new int[length];
x.data = new T[length];
x.c = new Node<T>[length + 1];
DISK_WRITE(x);
bTree.Root = x;
}
B的基本操作:插入
/// <summary>
/// B树插入
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="bTree"></param>
/// <param name="k"></param>
public static void B_TREE_INSERT<T>(BTree<T> bTree, int k, T data)
{
var r = bTree.Root;
if (r.n == bTree.t * 2 - 1)
{
var s = ALLOCATE_NODE<T>();
var length = 2 * bTree.t - 1;
s.key = new int[length];
s.data = new T[length];
s.c = new Node<T>[length + 1];
r.leaf = true;
s.leaf = false;
s.c[0] = r;
bTree.Root = s;
B_TREE_SPLIAT_CHILD(bTree, s, 0);
B_TREE_INSERT_NOFULL(bTree, s, k, data);
}
else
{
B_TREE_INSERT_NOFULL(bTree, r, k, data);
}
}
/// <summary>
/// B树插入(非满结点)
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="bTree"></param>
/// <param name="x"></param>
/// <param name="k"></param>
private static void B_TREE_INSERT_NOFULL<T>(BTree<T> bTree, Node<T> x, int k, T data)
{
var i = x.n - 1;
if (x.leaf)
{
while (i >= 0
&& x.key[i] >= k)
{
x.key[i + 1] = x.key[i];
x.data[i + 1] = x.data[i];
i--;
}
i++;
x.key[i] = k;
x.data[i] = data;
x.n++;
}
else
{
while (i >= 0
&& x.key[i] >= k)
{
i--;
}
i++;
DISK_READ(x.c[i]);
if (x.c[i].n == bTree.t * 2 - 1)
{
B_TREE_SPLIAT_CHILD(bTree, x, i);
if (x.key[i] < k)
{
i++;
}
}
B_TREE_INSERT_NOFULL(bTree, x.c[i], k, data);
}
}
/// <summary>
/// 结点分裂
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="bTree"></param>
/// <param name="x"></param>
/// <param name="i"></param>
private static void B_TREE_SPLIAT_CHILD<T>(BTree<T> bTree, Node<T> x, int i)
{
var t = bTree.t;
var y = x.c[i];
var z = ALLOCATE_NODE<T>();
z.key = new int[t * 2 - 1];
z.data = new T[t * 2 - 1];
z.c = new Node<T>[t * 2];
z.leaf = y.leaf;
z.n = t - 1;
for (var j = 0;
j < t - 1;
j++)
{
z.key[j] = y.key[t + j];
z.data[j] = y.data[t + j];
}
if (!y.leaf)
{
for (var j = 0;
j < t;
j++)
{
z.c[j] = y.c[t + j];
}
}
y.n = t - 1;
for (var j = x.n - 1;
j >= i;
j--)
{
x.key[j + 1] = x.key[j];
}
x.key[i] = y.key[t - 1];
x.data[i] = y.data[t - 1];
for (var j = x.n;
j >= i + 1;
j--)
{
x.c[j + 1] = x.c[j];
}
x.c[i + 1] = z;
x.n++;
}















 1488
1488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









