







获取百度百科图册内图片,严重失败!!
目标获得‘百度百科图册内图片’,如下
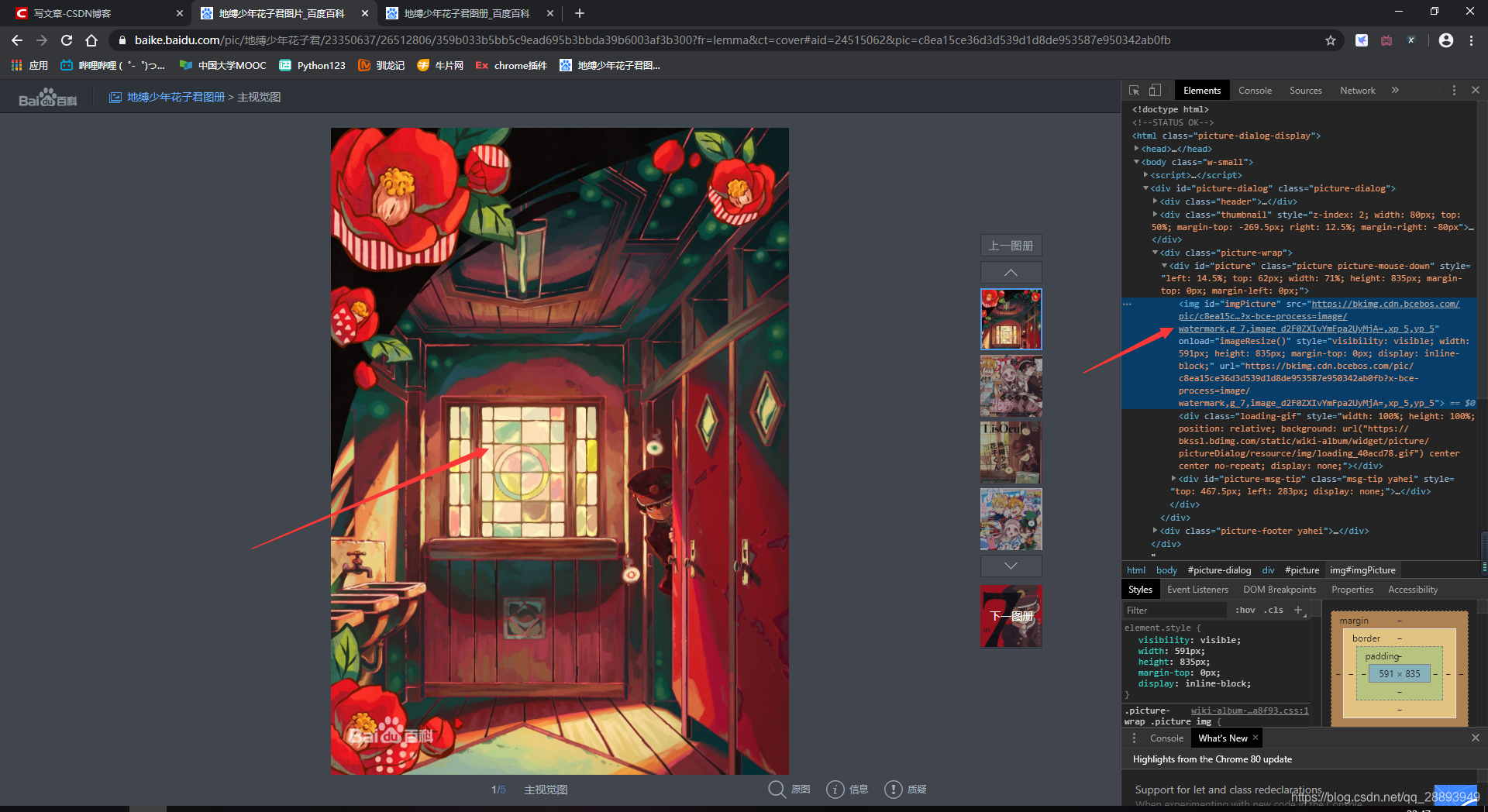
下面是base_url的界面
成功实现“代码半小时,改错一晚上,最终仍失败”~哭
代码先贴上
import requests
from lxml import etree
import time
import os
def get_html(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36'}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.content
except:
print("我才不会告诉你网络连接有问题呢(金毛式发言)")
def get_info(html):
html = etree.HTML(html)
# 获得不同图片的地址(由于网页本身问题,每组存在一张相同图片,后续改进)
urls = html.xpath('//div[@class="pic-list"]/a/@href')
pic_add = [[],[]]
for url in urls:
html2 = get_html('https://baike.baidu.com' + url)
html2 = etree.HTML(html2)
# 将图片名存储在name中,将对应地址存放在img中,将列表name和img存储在pic_add(二维列表)中
name = str(html2.xpath('//div[@class="breadcrumb"]/span/text()')[0])
img = str(html2.xpath('//div[@class="picture-wrap"]/div/img/@src')[0])
pic_add[0].append(name)
pic_add[1].append(img)
return pic_add
def main():
base_url = 'https://baike.baidu.com/pic/%E5%9C%B0%E7%BC%9A%E5%B0%91%E5%B9%B4%E8%8A%B1%E5%AD%90%E5%90%9B/23350637'
html = get_html(base_url)
pic_add = get_info(html)
# print(pic_add[0])
names = pic_add[0]
imgs = pic_add[1]
for name in names:
# 判断文件名是否重复(是否已有文件以该名称命名),并将文件命名创建
count = 0
way = 'img\\' + name + '0' + '.jpg'
while os.path.exists('img\\' +name + str(count)+'.jpg'):
count += 1
way = 'img\\' + name + str(count) + '.jpg'
# 下载文件,通过imgs[names.index(name)]找到name对应的img
try:
with open(way, 'wb') as f:
print('正在下载:{}'.format(name))
print(imgs[names.index(name)])
f.write(imgs[names.index(name)].encode('utf-8'))
#time.sleep(0.1)
except:
print('这图老子不下了!!')
if __name__ == '__main__':
main()
由于新手上路,代码可能存在大量冗余及不规范的地方,敬请见谅
最后出现图片无法写入文件的问题,头秃,求大佬支援
先加载库
import requests
from lxml import etree
import time
import os
再构建一个简单的函数获取html
def get_html(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36'}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.content
except:
print("我才不会告诉你网络连接有问题呢(金毛式发言)")
观察url并提取数据
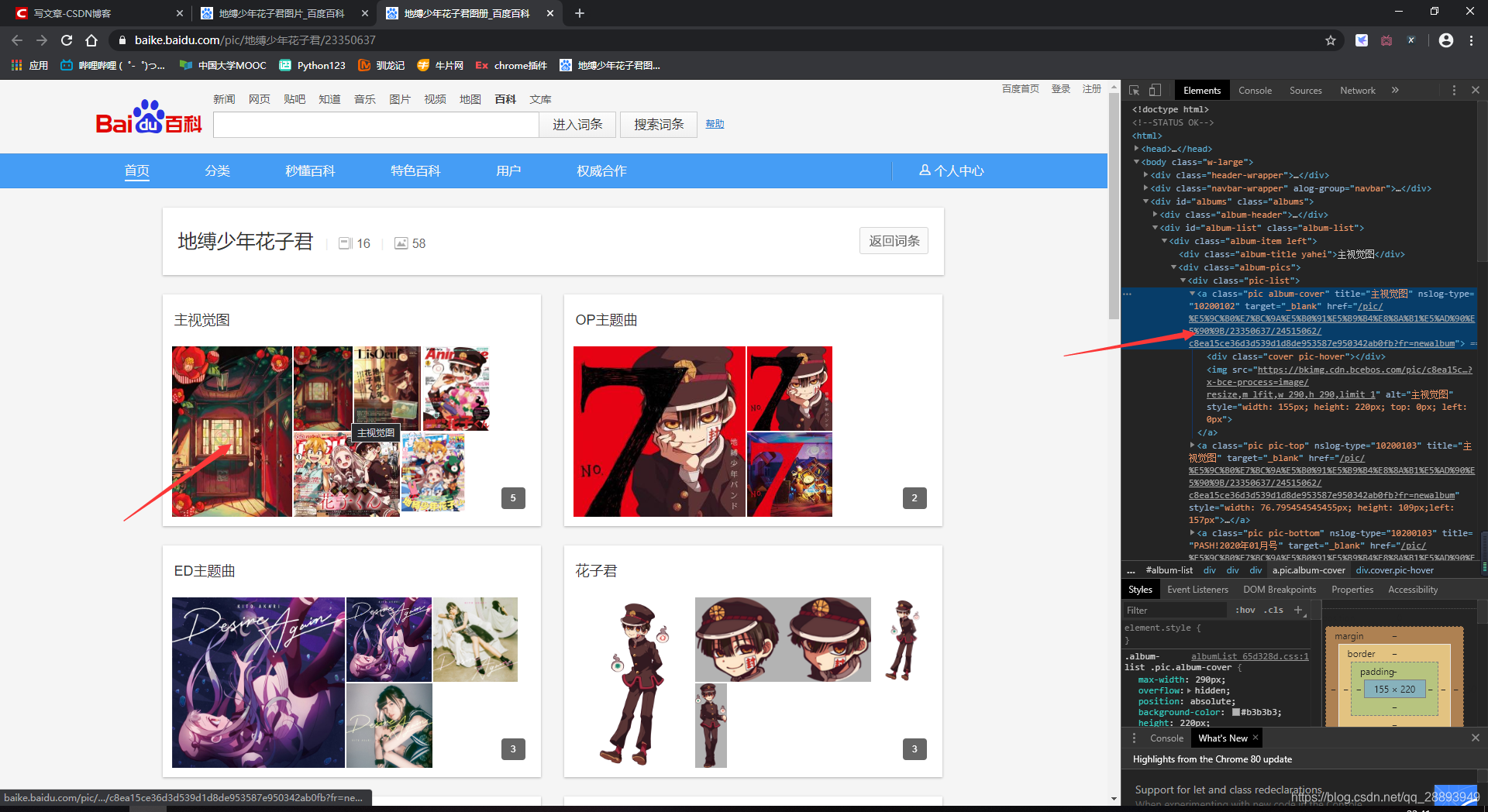
html = etree.HTML(html)
# 获得不同图片的地址(由于网页本身问题,每组存在一张相同图片,后续改进)
urls = html.xpath('//div[@class="pic-list"]/a/@href')
html2 = get_html('https://baike.baidu.com' + url)
html2 = etree.HTML(html2)
# 将图片名存储在name中,将对应地址存放在img中,将列表name和img存储在pic_add(二维列表)中
name = str(html2.xpath('//div[@class="breadcrumb"]/span/text()')[0])
img = str(html2.xpath('//div[@class="picture-wrap"]/div/img/@src')[0])
pic_add[0].append(name)
pic_add[1].append(img)
然后就是简单的主函数
def main():
base_url = 'https://baike.baidu.com/pic/%E5%9C%B0%E7%BC%9A%E5%B0%91%E5%B9%B4%E8%8A%B1%E5%AD%90%E5%90%9B/23350637'
html = get_html(base_url)
pic_add = get_info(html)
# print(pic_add[0])
names = pic_add[0]
imgs = pic_add[1]
for name in names:
# 判断文件名是否重复(是否已有文件以该名称命名),并将文件命名创建
count = 0
way = 'img\\' + name + '0' + '.jpg'
while os.path.exists('img\\' +name + str(count)+'.jpg'):
count += 1
way = 'img\\' + name + str(count) + '.jpg'
# 写入文件,通过imgs[names.index(name)]找到name对应的img
try:
with open(way, 'wb') as f:
print('正在下载:{}'.format(name))
print(imgs[names.index(name)])
f.write(imgs[names.index(name)].encode('utf-8'))
#time.sleep(0.1)
except:
print('这图老子不下了!!')
if __name__ == '__main__':
main()
!!!!失败啦!!!!
最后导出图片失败,程序运行结果如下
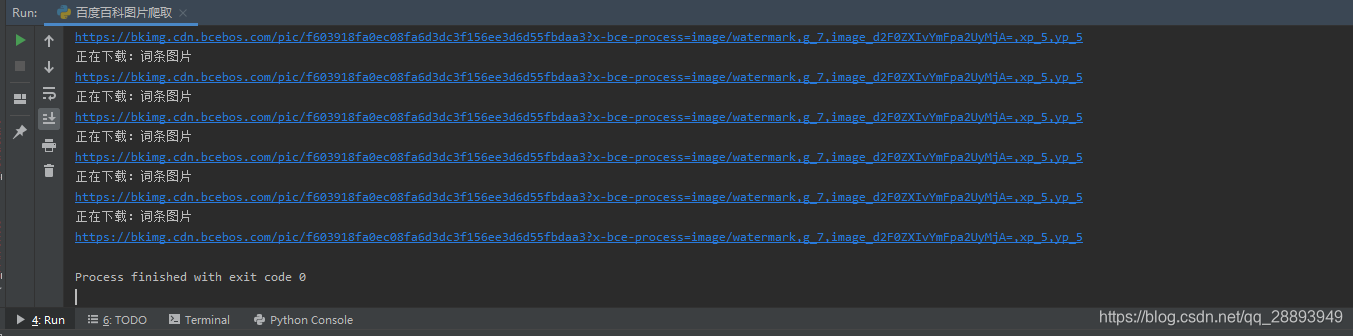
新手瞎猜环节
怀疑是得到的url不是类似https://img-blog.csdnimg.cn/20200414225309734.png这样以png或jpg结尾导致的
求大手子们拉萌新一把,哭


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









