







一、虚拟化技术概述

虚拟化[Virtualization]技术最早出现在 20 世纪 60 年代的 IBM 大型机系统,在70年代的 System370 系列中逐渐流行起来,这些机器通过⼀种叫虚拟机监控器[Virtual Machine Monitor,VMM,即现在的Hypervisor]的程序在物理硬件之上生成许多可以运行独立操作系统软件的虚拟机[Virtual Machine]实例。随着近年多核系统、集群、网格甚至云计算的广泛部署,虚拟化技术在商业应用上的优势日益体现,不仅降低了 IT 成本,而且还增强了系统安全性和可靠性,虚拟化的概念也逐渐深入到人们日常的工作与生活中。
虚拟化是⼀个广义的术语,对于不同的人来说可能意味着不同的东西,这要取决他们所处的环境。在计算机科学领域中,虚拟化代表着对计算资源的抽象,而不仅仅局限于虚拟机的概念。例如对物理内存的抽象,产生了虚拟内存技术,使得应用程序认为其自身拥有连续可用的地址空间[Address Space],而实际上,应用程序的代码和数据可能是被分隔成多个碎片页或段),甚至被交换到磁盘、闪存等外部存储器上,即使物理内存不足,应用程序也能顺利执行。
二、主流虚拟化方案介绍
1、虚拟化技术主要分类
- 平台虚拟化(Platform Virtualization)
针对计算机硬件和操作系统的虚拟化。
- 资源虚拟化(Resource Virtualization)
针对特定的系统资源的虚拟化,比如内存、CPU、存储、网络资源等。
- 应用程序虚拟化(Application Virtualization)
包括仿真、模拟、解释技术等。
2、平台虚拟化技术分类
我们通常所说的虚拟化主要是指平台虚拟化技术,通过使用控制程序(Control Program,也被称为Virtual Machine Monitor 或Hypervisor),隐藏特定计算平台的实际物理特性,为⽤户提供抽象的、统⼀的、模拟的计算环境(称为虚拟机)。虚拟机中运行的操作系统被称为客户机操作系统(Guest OS),运行虚拟机监控器的操作系统被称为主机操作系统(Host OS),当然某些虚拟机监控器可以脱离操作系统直接运行在硬件之上(如 VMWARE 的 ESX 产品)。运行虚拟机的真实系统我们称之为主机系统。
(1)、操作系统级虚拟化(Operating System Level Virtualization)
在传统操作系统中,所有用户的进程本质上是在同⼀个操作系统的实例中运行,因此内核 或应用程序的缺陷可能影响到其它进程。操作系统级虚拟化是⼀种在服务器操作系统中使用的轻量级的虚拟化技术,内核通过创建多个虚拟的操作系统实例(内核和库)来隔离不同的进程,不同实例中的进程完全不了解对方的存在。比较著名的有 Solaris Container,FreeBSD Jail 和 OpenVZ 等。比如OPENVZ:这个平台是最便宜的VPS平台,在各个vps商哪里都是价格最低的。OPENVZ本身运行在linux之上,它通过自己的虚拟化技术把⼀个服务器虚拟化成多个可以分别 安装操作系统的实例,这样的每⼀个实体就是⼀个VPS,从客户的角度来看这就是⼀个虚拟的 服务器,可以等同看做⼀台独立的服务器。OPENVZ虚拟化出来的VPS只能安装linux操作系统,不能安装windows系统 ,比如Centos、Fedora、Gentoo、Debian等。不能安装windows操作系统是openvz的第⼀个缺点, 需要使用windows平台的用户不能使用OPENVZVPS。OPENVZ的第⼆个缺点是OPENVZ不是完全的虚拟化 , 每个VPS账户共用宿主机内核 ,不能单 独修改内核。好在绝大多少用户根本不需要修改内核,所以这个缺点对多数人可以忽略不计。 而这⼀点也正是openvz的优点,这⼀共用内核特性使得openvz的效率最高,超过KVM、 Xen、VMware等平台。在不超售的情况下,openvz是最快速效率最高的VPS平台。
(2)、部分虚拟化(Partial Virtualization)
VMM 只模拟部分底层硬件 ,因此客户机操作系统不做修改是无法在虚拟机中运行的,其它程序可能也需要进行修改。在历史上,部分虚拟化是通往全虚拟化道路上的重要里程碑,最早出现在第⼀代的分时系统 CTSS 和 IBM M44/44X 实验性的分页系统中。
(3)、全虚拟化(Full Virtualization)
全虚拟化是指虚拟机模拟了完整的底层硬件,包括处理器、物理内存、时钟、外设等,使得为原始硬件设计的操作系统或其它系统软件完全不做任何修改就可以在虚拟机中运行。
操作系统与真实硬件之间的交互可以看成是通过⼀个预先规定的硬件接口进行的。全虚拟化 VMM 以完整模拟硬件的方式提供全部接口(同时还必须模拟特权指令的执行过程)。举例而言,x86 体系结构中,对于操作系统切换进程页表的操作,真实硬件通过提供⼀个特权CR3 寄存器来实现该接口,操作系统只需执行 "mov pgtable,%%cr3"汇编指令即可。
全虚拟化 VMM 必须完整地模拟该接口执行的全过程。如果硬件不提供虚拟化的特殊支持,那么这个模拟过程将会十分复杂:⼀般而言,VMM 必须运行在最高优先级来完全控制主机系统,而 Guest OS 需要降级运行,从而不能执行特权操作。当 Guest OS 执行前面的特权汇编指令时,主机系统产生异常(General Protection Exception),执行控制权重新从 Guest OS转到 VMM 手中。VMM 事先分配⼀个变量作为影子CR3 寄存器给 Guest OS,将 pgtable 代表的客户机物理地址(Guest Physical Address)填⼊影子 CR3 寄存器,然后 VMM 还需要pgtable 翻译成主机物理地址(Host Physical Address)并填⼊物理 CR3 寄存器,最后返回到 Guest OS中。随后 VMM 还将处理复杂的 Guest OS 缺页异常(Page Fault)。
比较著名的全虚拟化 VMM 有 Microsoft Virtual PC、VMware Workstation、Sun Virtual
Box、Parallels Desktop for Mac 和 QEMU。
(4)、超虚拟化
这是⼀种修改 Guest OS 部分访问特权状态的代码以便直接与 VMM 交互的技术。解决了全虚拟化在特权指令情况下报错的问题,比全虚拟化更高级。在超虚拟化虚拟机中,部分硬件接口以软件的形式提供给客户机操作系统,这可以通过 Hypercall(VMM 提供给 Guest OS 的直接调用,与系统调用类似)的方式来提供。例如,Guest OS 把切换页表的代码修改为调用Hypercall 来直接完成修改影子CR3 寄存器和翻译地址的工作。 由于不需要产生额外的异常和模拟部分硬件执行流程,超虚拟化可以大幅度提高性能 ,比较著名的 VMM 有 Denali、Xen。
(5)、硬件辅助虚拟化(Hardware-Assisted Virtualization)
硬件辅助虚拟化是指借助硬件(主要是主机处理器)的支持来实现高效的全虚拟化。例如有了 Intel-VT 技术的支持,Guest OS 和 VMM 的执行环境自动地完全隔离开来,Guest OS 有自己的"套寄存器", 可以直接运行在最高级别 。因此在上面的例子中,Guest OS 能够执行修改页表的汇编指令。Intel-VT 和 AMD-V 是目前 x86 体系结构上可用的两种硬件辅助虚拟化技术。
三、KVM虚拟化技术简介
1、KVM架构
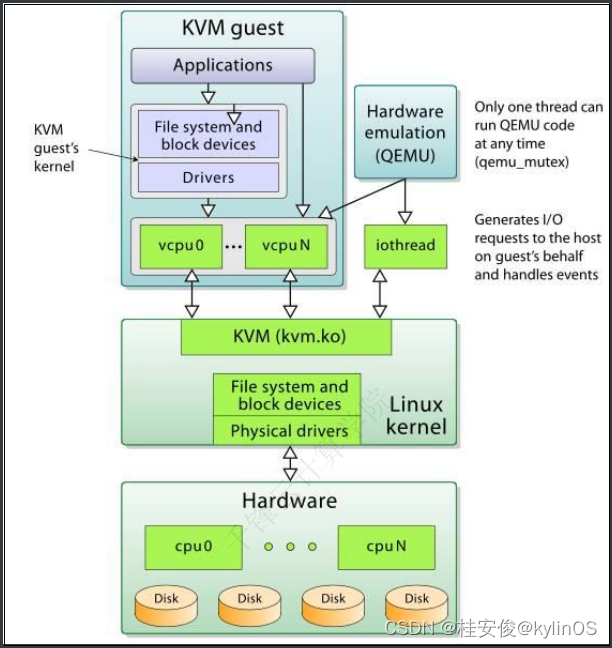
2、KVM架构解析
从rhel6开始使用,红帽公司直接把KVM的模块做成了内核的⼀部分。
xen用在rhel6之前的企业版中默认内核不支持,需要重新安装带xen功能的内核
KVM 针对运⾏在 x86 硬件上的、驻留在内核中的虚拟化基础结构。KVM 是第⼀个成为原⽣ Linux 内核(2.6.20)的⼀部分的 hypervisor,它是由 Avi Kivity 开发和维护的,现在归 Red Hat 所有。
这个 hypervisor 提供 x86 虚拟化,同时拥有到 PowerPC和 IA64 的通道。另外,KVM 最近还添加了对对称多处理(SMP)主机(和来宾)的⽀持,并且⽀持企业级特性,⽐如活动迁移(允许来宾操作系统在物理服务器之间迁移)。
KVM 是作为内核模块实现的,因此 Linux 只要加载该模块就会成为⼀个hypervisor。KVM 为⽀持hypervisor 指令的硬件平台提供完整的虚拟化(⽐如 Intel® Virtualization Technology [Intel VT] 或AMD Virtualization [AMD-V] 产品)。KVM 还⽀持准虚拟化来宾操作系统,包括 Linux 和 Windows。这种技术由两个组件实现。第⼀个是可加载的 KVM 模块,当在 Linux 内核安装该模块之后,它就可以管理虚拟化硬件,并通过 /proc ⽂件系统公开其功能。第⼆个组件⽤于 PC 平台模拟,它是由修改版QEMU 提供的。QEMU 作为⽤户空间进程执⾏,并且在来宾操作系统请求⽅⾯与内核协调。当新的操作系统在 KVM 上启动时(通过⼀个称为 KVM 的实⽤程序),它就成为宿主操作系统的⼀个进程,因此就可以像其他进程⼀样调度它。但与传统的 Linux 进程不⼀样,来宾操作系统被 hypervisor标识为处于 "来宾" 模式(独⽴于内核和⽤户模式)。每个来宾操作系统都是通过 /dev/KVM 设备映射的,它们拥有⾃⼰的虚拟地址空间,该空间映射到主机内核的物理地址空间。如前所述,KVM 使⽤底层硬件的虚拟化⽀持来提供完整的(原⽣)虚拟化。I/O请求通过主机内核映射到在主机上(hypervisor)执⾏的 QEMU 进程。KVM 在 Linux 环境中以主机的⽅式运⾏,不过只要底层硬件虚拟化⽀持,它就能够⽀持⼤量的来宾操作系统。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











