







一、合久必分——MapReduce
- HDFS是hadoop的云存储,而MapReduce即是hadoop云计算。
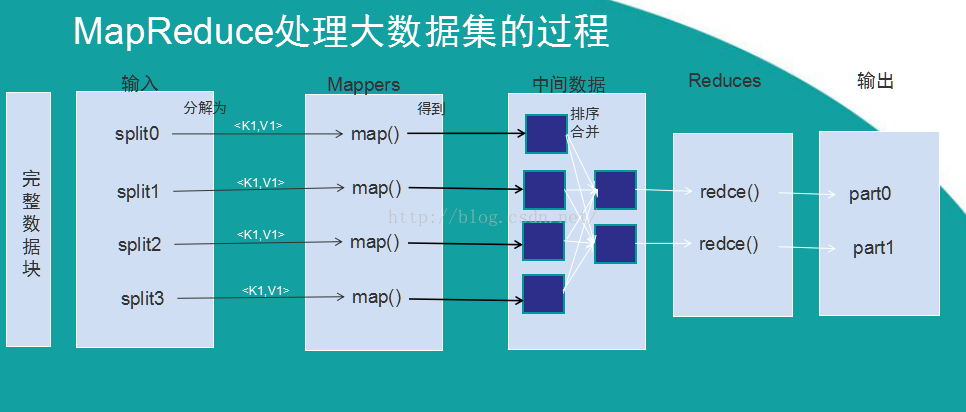
- MapReduce采用”分而治之“的思想,把对大规模数据集的操作,分发给一个主节点管理下的各分节点共同完成,然后通过整合各分节点的中间结果,得到最终的结果。
- Map阶段:MapReduce框架将任务的输入数据分割成固定大小的片段(splits),随后将每个split进一步分解成一批键值对<K1,V1>。Hadoop为每一个split创建一个Map任务用于执行用户自定义的map函数,以<K1,V1>对作为输入,得到计算的中间结果<K2,V2>。接着将中间结果按照K2进行排序,并将key值相同的value组合成为<K2,list<V2>>元组,分组后对应不同的Reduce任务
- Reduce阶段:Reduce把从不同Mapper接收来的数据整合在一起,调用用户自定义的reduce函数,对从map传来得<K2,list<V2>>进行相应的处理,得到最终结果<K3,V3>并输出到HDFS上
一、WordCount案例
package com.yc.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
private final static IntWritable one = new IntWritable(1);
/**
* 自定义Mapper
* 功能:将输入的文本设为key,将value设为1,
* 当map()运行完后Hadoop框架会对中间数据进行排序合并
* @author wrm
*
*/
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text word = new Text();
protected void map(LongWritable key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] vs=value.toString().split("\\s");
for (String v : vs) {
context.write(new Text(v), one);
}
}
}
/**
* 自定义Reduce
* 功能:将从Mapper输入的数据进行计算。由于Hadoop对中间数据进行了合并
* Key又是单词,所以相同的单词就会变为<K,list<V>>模式,迭代,累加后输出
* @author wrm
*
*/
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable vs : value) {
count+=vs.get();
}
context.write(key, new IntWritable(count)); //输出数据
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// System.out.println(otherArgs);
// if (otherArgs.length != 2) {
// System.err.println("Usage: wordcount <in> <out>");
// System.exit(2);
// }
Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCount.class); //设置程序启动类
job.setMapperClass(TokenizerMapper.class); //设置Mapper使用类
job.setReducerClass(IntSumReducer.class); //设置Reduce使用类
job.setOutputKeyClass(Text.class); //设置从Map中输出的Key的数据类型
job.setOutputValueClass(IntWritable.class); //设置从Map中输出的Value的数据类型
FileInputFormat.addInputPath(job, new Path("C:/Users/wrm/Desktop/1.txt")); //设置源目录
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.108:9000/file1/")); //设置目标目录
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}二、自定义数据类型
Hadoop有八大数据类型分别对应Java中的:
Hadoop Java
BooleanWritable boolean
ByteWritable byte
DoubleWritable double
FloatWritable float
IntWritable int
LongWritable long
Text String
NullWritable Null
这八大数据类型肯定是不够用的,那么就必须像JavaBean一样的自定义数据类型。而Hadoop是基于流操作的,所以它的数据类型必须要有读出和写入的操作。如下实例是一个用户的数据类型:
package com.yc.hadoop.bean;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.nio.ByteBuffer;
import java.nio.charset.CharacterCodingException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
public class UserInfo implements WritableComparable<UserInfo>,Serializable {
/**
*
*/
private static final long serialVersionUID = -5923323181398894001L;
private String name;
private String id;
private String age;
private String sex;
public String getName() {
return name;
}
@Override
public String toString() {
return "name:" + name + " id:" + id + " age:" + age + " sex:" + sex;
}
public UserInfo() {
}
public UserInfo(String id,String name,String age, String sex) {
this.name = name;
this.id = id;
this.age = age;
this.sex = sex;
}
/**
* 必有,作用是从流中读取出参数
*/
@Override
public void readFields(DataInput in) throws IOException {
this.name=in.readUTF();
this.id=in.readUTF();
this.age=in.readUTF();
this.sex=in.readUTF();
}
/**
* 必有:将对象写入流中
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeUTF(id);
out.writeUTF(age);
out.writeUTF(sex);
}
/**
* 需做Key时必有,因为Key在中间数据阶段需要排序,必须要能判断其大小
*/
@Override
public int compareTo(UserInfo o) {
return Integer.parseInt(this.id)-Integer.parseInt(o.id);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((age == null) ? 0 : age.hashCode());
result = prime * result + ((id == null) ? 0 : id.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((sex == null) ? 0 : sex.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
UserInfo other = (UserInfo) obj;
if (age == null) {
if (other.age != null)
return false;
} else if (!age.equals(other.age))
return false;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (sex == null) {
if (other.sex != null)
return false;
} else if (!sex.equals(other.sex))
return false;
return true;
}
public void setName(String name) {
this.name = name;
}
public void setId(String id) {
this.id = id;
}
public void setAge(String age) {
this.age = age;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getId() {
return id;
}
public String getAge() {
return age;
}
public String getSex() {
return sex;
}
}其的使用方法:
job.setOutputKeyClass(UsetInfo.class); //作为Key时
job.setOutputValueClass(UserInfo.class); //作为value时以上,就是MapReduce的基本用法和自定义数据类型的用法。更多的加深实际上是在算法层面的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









