







常见数据结构和算法实现(排序/查找/数组/链表/栈/队列/树/递归/海量数据处理/图/位图/Java版数据结构)
数据结构和算法作为程序员的基本功,一定得稳扎稳打的学习,我们常见的框架底层就是各类数据结构,例如跳表之于redis、B+树之于mysql、倒排索引之于ES,熟悉了底层数据结构,对框架有了更深层次的理解,在后续程序设计过程中就更能得心应手。掌握常见数据结构和算法的重要性显而易见,本文主要讲解了几种常见的数据结构及基础的排序和查找算法,最后对高频算法笔试面试题做了总结。本文是Java数据结构第四讲-树/递归
文章目录
9、树部分面试题
9.1、如何遍历一棵二叉树?
二叉树是n个有限元素的集合,由根元素以及左右子数组成。集合可以为空。
- 概念:结点的度,结点所拥有的子树的个数称为度。
叶节点,度为o的结点。
分支节点,即非叶子结点 - 路径:n1,n2,,,nk的长度为路径
- 层数:根结点层数为1,其余的结点++双亲
- 深度:最大层数
- 满二叉树:所有叶子结点在同一层
- 完全二叉树:叶子结点只能出现在最下层和次下层。
- 性质: 非空二叉树第i层最多2{i-1}个结点
深度为k,最多2{k}-1个结点,最少k个结点
非空二叉树,度为0的节点数比度为2的节点数多1,n0=n2+1;
n个结点的完全二叉树的深度为lgn+1 - 存储:1、基于指针或者应用的二叉链式存储法;2、基于数组的顺序存储法(适合完全二叉树)
链式存储法:每个结点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针
顺序存储法:节点X存储在数据中下标为i的位置,下标为2i的位置存储的是左子节点,下标为2i+1的位置存储的是右子节点。 - 遍历:使用队列来实现对二叉树的层序遍历,思路:根结点放入队列,每次从队列中取出一个结点,打印值。若这个值有子结点,子结点入队尾,直至队列为空。 代码P305(是一种广度优先的遍历算法)
递归实现:中序遍历,先序遍历,后序遍历(表示的是节点与它的左右子树节点遍历打印的先后顺序) 时间复杂度O(n)
非递归中序遍历:首先要移动到结点的左子树,完成左子树的遍历后,再将结点出栈进行
void InOrderNonRecursive(TreeNode root){
if (root == null) {
return;
}
Stack s = new Stack();
while(true){
while (root !=null) {
s.push(root);
root = root.left;
}
if (s.isEmpty()) {
break;
}
root = (TreeNode) s.pop();
System.out.println(root.val);
root = root.right;
}
}
非递归先序遍历:需要使用一个栈来记录当前节点,以便在完成左子树遍历后能返回到右子树中进行遍历;
* 在遍历左子树之前,把当前节点保存在栈中,直至遍历完左子树,将该元素出栈,然后找到右子树进行遍历。
void PreOderNonRecursive(TreeNode root){
if (root == null) {
return;
}
Stack s= new Stack();//使用栈保存将要遍历的结点
while(true){
while (root !=null) {
System.out.println(root.val);
s.push(root);
root = root.left;
}
if (s.isEmpty()) {
break;
}
root = (TreeNode) s.pop();
root = root.right;
}
}
递归后序遍历:
void PostOrder(TreeNode root){
if (root!= null) {
PostOrder(root.left);
PostOrder(root.right);
System.out.println(root.val);
}
}
层序遍历:
void LevelOrder(TreeNode root){
TreeNode temp;
Queue q= new ArrayBlockingQueue(0);
if (root == null)
return;
q.add(root);
while (!q.isEmpty()) {
temp = (TreeNode) q.remove();
System.out.println(temp.val);
if (temp.left != null) {
q.add(temp.left);
}
if (temp.left != null) {
q.add(temp.right);
}
}
q.clear();
}
9.2、二叉查找树(二叉搜索树)(Mysql索引的底层)
二叉查找树最大的特点就是,支持动态数据集合的快速插入、删除、查找操作
1、查找操作:我们先去根节点,如果它等于我们要查找的数据,就返回;如果比根节点小,就在左子树中递归查找;如果比根节点值大,就在右子树中递归查找。
public class BinarySearchTree {
private Node tree;
public Node find(int data) {
Node p = tree;
while (p != null) {
if (data < p.data) p = p.left;
else if (data > p.data) p = p.right;
else return p;
}
return null;
}
public static class Node {
private int data;
private Node left;
private Node right;
public Node(int data) {
this.data = data;
}
}
}
2、插入操作 得先比较,从根节点开始
public void insert(int data) {
if (tree == null) {
tree = new Node(data);
return;
}
Node p = tree;
while (p != null) {
if (data > p.data) {
if (p.right == null) {
p.right = new Node(data);
return;
}
p = p.right;
} else { // data < p.data
if (p.left == null) {
p.left = new Node(data);
return;
}
p = p.left;
}
}
}
3、二叉查找树的删除操作(1、如果要删除的节点没有子节点,我们只需要直接将父节点中指向要删除节点的指针置为null;2、要删除的节点有一个子节点,我们只需要更新父节点,指向要删除节点的指针
3、要删除的节点有两个子节点,找到这个节点的右子树中的最小节点,替换到要删除的节点上)
public void delete(int data) {
Node p = tree; // p指向要删除的节点,初始化指向根节点
Node pp = null; // pp记录的是p的父节点
while(p != null && p.data != data) {
pp = p;
if (data > p.data) p = p.right;
else p = p.left;
}
if (p == null) return; // 没有找到
//要删除的节点有两个子节点
if (p.left != null && p.right != null) {//查找右子树中最小节点
Node minP = p.right;
Node minPP = p; // minPP表示minP的父节点
while (minP.left != null) {
minPP = minP;
minP = minP.left;
}
p.data = minP.data; // 将minP的数据替换到p中
p = minP; // 下面就变成了删除minP了
pp = minPP;
}
//删除节点是叶子节点或者仅有一个子节点
Node child; // p的子节点
if (p.left != null) child = p.left;
else if (p.right != null) child = p.right;
else child = null;
if (pp == null) tree = child; // 删除的是根节点
else if (pp.left == p) pp.left = child;
else pp.right = child;
}
二叉查找树的执行效率:若是根节点的左右子树季度不平衡,已经退化到了链表,查找的时间复杂度为O(n);平衡二叉查找树的时间复杂度O(lgn)
9.3、红黑树的应用场景(TreeMap 红黑树:一种近似平衡的二叉查找树:二叉树中任意一个节点的左右子树的高度相差不能大于1。包括完全二叉树、满二叉树) 红黑树一定得掌握
-
红黑树的由来
红黑树是于1972年发明的,当时称为对称二叉B树,1978年得到优化,正式命名为红黑树。它的主要特征是在每个节点上增加一个属性来表示节点的颜色,可以是红色,也可以是黑色。红黑树和 AVL 树类似,都是在进行插入和删除元素时,通过特定的旋转来保持自身平衡的, 从而获得较高的查找性能。与AVL树相比,红黑树并不追求所有递归子树的高度差不超过1, 而是保证从根节点到叶子节点的最长路径不超过最短路径的2 倍,所以它的最坏运行时间也是 O(logn)。红黑树通过重新着色和左右旋转,更加高效地完成了插入和删除操作后的自平衡调整。当然 , 红黑树在本质上还是二叉查找树,它额外引入了 5 个约束条件,如下 -
红黑树的特点
1、每个节点要么是红色,要么是黑色;
2、根节点必须是黑色;
3、红色节点不能连续(红色节点的孩子和父亲都不能是红色);
4、对于每个节点,从该点至叶子的任何路径,都含有相同个数的黑色节点;
5、确保节点的左右子树的高度差,不会超过二者中较低那个的一倍; -
应用场景:搜索,插入删除次数多(为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的)
1、map和set都是用红黑树实现的
2、linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块
3、epoll在内核中的实现,用红黑树管理事件块
4、nginx中,用红黑树管理timer
5、Java的TreeMap实现
AVL树适合用于插入删除次数比较少,但查找多的情况 -
关于动态数据结构:链表/栈/队列/哈希表(链表适合遍历的场景,插入和删除操作方便;栈和队列可以算一种特殊的链表,分别使用先进后出和先进先出的场景;哈希表适合插入和删除比较少,查找比较多的场景;红黑树对数据要求有序,对数据增删改查都有一定要求的时候)
-
散列表/跳表/红黑树性能对比:
1、散列表:插入删除查找都是O(1),是最常用的,缺点是不能顺序遍历以及扩容缩容的性能损耗。适用于不需要顺序遍历、数据更新不那么频繁的;
2、跳表:插入删除查找都是O(lgn),能顺序遍历,缺点是空间复杂度O(n),适用于不那么在意内存空间的,其顺序遍历和区间查找非常方便;
3、红黑树:插入删除查找都是O(lgn),中序遍历即是顺序遍历,稳定。缺点是难以实现,去查找不方便。
9.4、数据结构 堆
- 满足条件:1、堆是一个完全二叉树;2、堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
堆都支持哪些操作以及如何存储一个堆(通过数组来存储) - 缺点:对于一组已经有序的数据来说,经过建堆后,数据反而变得更无序了
- 堆排序的过程:1、建立初始堆(把数组中的元素的序列看成是一颗完全二叉树,对该二叉树进行调整,使之成为堆) 根节点的索引是1
2、堆排序(把根元素与最右子节点交换,然后再次构建堆,再与倒数第二集结点交换,然后再构建堆) 生成由小到大排列的数组
时间复杂度:假设有n个数据,需要进行n-1次建堆,每次建堆本身耗时lgn,则其时间效率为O(nlgn) 空间复杂度O(1)
建堆操作:
private static void buildHeap(int[] a, int n) {
for (int i = n/2; i >= 1; --i) {
heapify(a, n, i);
}
}
private static void heapify(int[] a, int n, int i) {
while (true) {
int maxPos = i;
if (i*2 <= n && a[i] < a[i*2]) maxPos = i*2;
if (i*2+1 <= n && a[maxPos] < a[i*2+1]) maxPos = i*2+1;
if (maxPos == i) break;
swap(a, i, maxPos);
i = maxPos;
}
}
排序操作: //n表示数据的个数,数组a中的数据从下标1到n的位置。
public static void sort(int[] a, int n) {
buildHeap(a, n);
int k = n;
while (k > 1) {
swap(a, 1, k);
--k;
heapify(a, k, 1);
}
}
为什么快速排序要比堆排序性能好?
1、堆排序数据访问的方式没有快速排序友好(开拍是顺序访问;堆排序是跳着访问,对cpu缓存不友好)
2、同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序
应用:1、优先级队列;2、topK;3、流里面的中位数;
9.5、AC自动机:如何用多模式串匹配实现敏感词过滤功能?(使用Trie树)
字符串匹配算法:单模式串匹配算法(BF算法、RK算法、BM算法、KMP算法),多模式串匹配算法(Trie树 最长前缀匹配)
AC自动机算法包含两个部分,第一部分是将多个模式串构建成AC自动机,第二部分是在AC自动机中匹配主串。第一部分又分为两个小的步骤,一个是将模式串构建成Trie树,另一个是在Trie树上构建失败指针
适用场景:
- 单模式串匹配:
BF(直接匹配算法 简单场景,主串和模式串都不太长, O(mn) 效率最低)
KP(字符集范围不要太大且模式串不要太长,否则hash值可能冲突,O(n))
naive-BM(模式串最好不要太长(因为预处理较重),比如IDE编辑器里的查找场景;预处理O(mm),匹配O(n),实现较复杂,需要较多额外空间)
KMP(适合所有场景,整体实现起来也比BM简单,O(n+m),仅需一个next数组的O(n)额外空间;但统计意义下似乎BM更快)
还有一种比BM/KMP更快,且实现+理解起来都更容易的Sunday算法 - 多模式串匹配:
naive-Trie(适合多模式串公共前缀较多的匹配(O(n*k)) 或者 根据公共前缀进行查找(O(k))的场景,比如搜索框的自动补全提示 root不存储字符)
AC自动机(适合大量文本中多模式串的精确匹配查找, 查找的复杂度可以到O(n))**
定义:AC自动机实际上就是在Trie树之上,加了类似KMP的next数组,只不过此处的next数组是构建在树上
public class AcNode {
public char data;
public AcNode[] children = new AcNode[26]; //字符集只包含a~z这26个字符
public boolean isEndingChar = false; //结尾字符为true
public int length = -1; //当isEndingChar=true时,记录模式串长度
public AcNode fail; //失败指针 相当于KMP中失效函数next数组
public AcNode(char data) {
this.data = data;
}
}
9.6、B树和B+树的区别(为什么 MongoDB 索引选择B树,而 Mysql 选择B+树)?
一个是数据的保存位置,
- B树的数据每个节点既保存索引,又保存数据;B+树的数据只会落在叶子节点
一个是相邻节点的指向
- 增加了相邻节点的指向指针
上述两种特性造成的现象为:
1、B+树查询时间复杂度固定是logn,B树查询复杂度最好是 O(1)。
2、B+树相邻接点的指针可以大大增加区间访问性,可使用在范围查询等,而B树每个节点 key 和 data 在一起,无法区间查找。
3、B+树更适合外部存储,也就是磁盘存储。由于父级节点无 data 域,每个节点能索引的范围更大更精确
4、注意这个区别相当重要,B树每个节点即保存数据又保存索引,所以磁盘IO的次数很少,B+树只有叶子节点保存,磁盘IO多,但是区间访问比较好。
MongoDB
- MongoDB 是文档型的数据库,是一种 nosql,它使用类 Json 格式保存数据。比如之前我们的表可能有用户表、订单表、购物车表等等,还要建立他们之间的外键关联关系。但是类Json就不一样了。
- MongoDB使用B树,所有节点都有Data域,只要找到指定索引就可以进行访问,无疑单次查询平均快于Mysql。
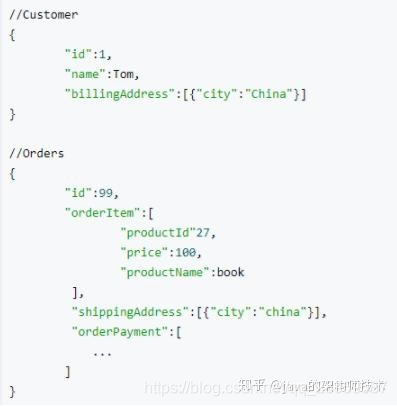
Mysql
- Mysql作为一个关系型数据库,数据的关联性是非常强的,区间访问是常见的一种情况,B+树由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。
10、递归方法
递归的使用场景
1、查询类目树
使用递归时应该注意的问题?
1、警惕堆栈溢出:(如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险) 解决方案:递归调用超过一定的深度后,就停止队规,返回错误(由于递归深度无法事先知道,这种方案不实用)
- 在递归调用类目树时遇到过,由于程序不当,造成了树一直被递归调用,从而导致堆栈溢出
2、递归代码的重复计算问题:某一个子问题被重复计算了多次。解决方案:通过一个数据结构(散列表)保存已经求结果的f(k),先看子问题是否被求解过,若是,直接从散列表中取值返回。
public int f(int n){
if(n==1) return 1;
if(n==2) return 2;
//hasSolvedList可以理解为一个Map,key是n,value是f(n)
hasSolvedList.containsKey(n){
return hasSolvedList.get(n);
}
int ret =f(n-1)+f(n-2);
hasSolvedList.put(n,ret);
return ret;
}//王争这道题没写好,他的本意是记忆化递归
3、空间复杂度,比较大,为O(n)
3、递归代码改写为非递归代码:f(x) =f(x-1)+1 ->
int f(int n){
int ret = 1;
for (int i = 2; i <= n; ++i) {
ret = ret + 1;
}
return ret;
}
f(n) = f(n-1)+f(n-2) ->
int f(int n){
if (n == 1) return 1;
if (n == 2) return 2;
int ret = 0;int pre = 2;int prepre = 1;
for (int i = 3; i <= n; ++i) {
ret = pre + prepre;
prepre = pre;
pre = ret;
}
return ret;
}
4、如何调试递归?调试递归:1.打印日志发现,递归值。2.结合条件断点进行调试
编程题2:如何找到“最终推荐人”?在数据库表中,我们可以记录两行数据,其中actor_id表示用户id,referrer_id表示推荐人id
long findRootReferrerId(long actorId) {
Long referrerId = select referrer_id from [table] where actor_id = actorId;
if (referrerId == null) return actorId;
return findRootReferrerId(referrerId);
}
可能出现的问题:1、递归很深会出现堆栈溢出的问题 2、若数据库中存在脏数据,可能会出现无限循环的问题 (如何来检测环的存在呢?)
- 检测环可以构造一个set集合或者散列表(下面都叫散列表)。每次获取到上层推荐人就去散列表里先查,没有查到的话就加入,如果存在则表示存在环了。当然,每一次查询都是一个自己的散列表,不能共用。
- 检测环的第二种方法:双指针法(从起点开始分别以2x,1x速度出发两个指针,当遇到null停止,相遇点为null时说明没有环,如果相遇点不为null,说明有环)
编程1;实现斐波那契数列求值f(n)=f(n-1)+f(n-2) or 假如这里有n个台阶,每次你可以跨1个台阶或者2个台阶,请问走这n个台阶有多少种走法?
递推公式:f(n)=f(n-1)+f(n-2) 递归终止条件:f(1)=1,f(2)=2
最终的递归代码是这样的:
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n-1) + f(n-2);
}
编程题2:汉诺塔(思想:将原柱最上面的n-1个圆盘移动到辅助柱;将第n个圆盘从原柱移到目的柱;将辅助柱的n-1个圆盘移动到目的柱)
void TowersOfHanoi(int n,char frompeg,char topeg,char auxpeg){
/*如果仅有一个圆盘,直接移动,然后返回*/
if(n==1){
syso("Move disk 1 from peg"+frompeg+"to peg"+topeg);
return;
}
/*利用c作为辅助,将A柱最上面的n-1个圆盘移动到B柱*/
TowersOfHanoi(n-1, frompeg, topeg,auxpeg);
/*将余下的圆盘从A柱移动C柱*/
syso("Move disk 1 from peg"+frompeg+"to peg"+topeg);
/*利用A柱作为辅助,将B柱上的n-1个圆盘移到C柱*/
TowersOfHanoi(n-1, auxpeg,topeg,frompeg);
}
编程3;实现求阶乘n!
int Fact(int n){
//基本情形:当参数为0或1时,返回1
if (n==1) {
return 1;
}else if (n == 0) {
return 1;
}else {
return n*Fact(n-1);
}
}
编程4;实现一组数据集合的全排列
public class 实现一组数据集合的全排列 {
public void printAllSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
if (arr.length == 1) {
System.out.println(arr[0]);
}
List<List<Integer>> result = _printAllSort(arr);
int count=0;
for (List list : result) {
count++;
System.out.println(list+" 第"+count+"种");
}
}
private List<List<Integer>> _printAllSort(int[] tmpArr) {
// 结束条件
List<List<Integer>> result = new ArrayList<>();
if (tmpArr.length == 2) {
List<Integer> subList = new ArrayList<>();
List<Integer> subList2 = new ArrayList<>();
subList.add(tmpArr[0]);
subList.add(tmpArr[1]);
subList2.add(tmpArr[1]);
subList2.add(tmpArr[0]);
result.add(subList);
result.add(subList2);
return result;
}
// 当前层处理
for (int i = 0; i < tmpArr.length; i++) {
// 顺序拿出一个参数,其余交给下一层处理
int tmp = tmpArr[i];
int[] arr = new int[tmpArr.length - 1];
int offset = 0;
for (int j = 0; j < tmpArr.length; j++) {
if (i != j) {
arr[offset] = tmpArr[j];
offset++;
}
}
List<List<Integer>> nextLevelResult = _printAllSort(arr);
// 处理下一层结果(当前值加到结果的前面、后面)
for (List<Integer> nextList : nextLevelResult) {
List<Integer> appendList = new ArrayList<>();
appendList.add(tmp);
appendList.addAll(nextList);
result.add(appendList);
}
}
return result;
}
}//[1, 2, 3, 4] 第1种 [1, 2, 4, 3] 第2种 [1, 3, 2, 4] 第3种 [1, 3, 4, 2] 第4种 [1, 4, 2, 3] 第5种 [1, 4, 3, 2] 第6种
编程5;爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
//方法1:暴力法 使用递归
public int climbStairs(int n) {
return climb_Stairs(0, n);
}
public int climb_Stairs(int i, int n) {
if (i > n) {
return 0;
}
if (i == n) {
return 1;
}
return climb_Stairs(i + 1, n) + climb_Stairs(i + 2, n);
}//时间复杂度:O(2^n)
方法2:记忆化递归 每一步的结果存储在 memomemo 数组之中,每当函数再次被调用,我们就直接从 memomemo 数组返回结果
public class 记忆化递归 {
public int climbStairs(int n) {
int memo[] = new int[n + 1];
return climb_Stairs(0, n, memo);
}
public int climb_Stairs(int i, int n, int memo[]) {
if (i > n) {
return 0;
}
if (i == n) {
return 1;
}
if (memo[i] > 0) {
return memo[i];
}
memo[i] = climb_Stairs(i + 1, n, memo) + climb_Stairs(i + 2, n, memo);
return memo[i];
}
}
方法3:动态规划 第i阶可以由以下两种方法得到:在第(i-1)阶后向上爬一阶。在第(i-2)阶后向上爬 2 阶。状态转移公式:dp[i]=dp[i?1]+dp[i?2]
public class 动态规划求解爬楼梯 {
public int climbStairs(int n) {
if (n == 1) {
return 1;
}
int[] dp = new int[n + 1];
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}
11、散列表相关知识点(HashMap/LinkedHashMap)
11.1、什么是hash算法,他们用于什么?
hash算法是一个hash函数,他使用任意长度的字符串,并将其减少为唯一的固定长度字符串。他用于密码有效性、消息和数据完整性以及许多其他加密系统。
- 加密算法原理:加密是将明文转换成“密文”的过程。要转换文本,算法使用一系列被称为“键”的位来进行计算。密钥越大,创建密文的潜在模式越多。大多数加密算法使用长度约为64到128位的固定输入块,而有些则使用流方法。
- 常用的加密算法:3-way blowfish cast cmea gost des/triple des idea loki crc MD5
- 哈希算法的应用:安全加密(MD5/SHA)、数据校验、唯一标识、散列函数,负载均衡、数据分片、分布式存储 **
- 安全加密:第一是很难根据哈希值反向推导出原始数据,第二是散列冲突的概率很小。
- 唯一标识:图片的唯一id(我们可以把每个图片的唯一标识,和相应的图片文件在图库中的路径信息,都存储在散列表中)
- 数据校验:我们通过哈希算法,对100个文件块分别取哈希值,并且保存在种子文件中。哈希算法特点,对数据很敏感。只要文件块的内容有一丁点儿的改变,最后计算出的哈希值就会完全不同。所以,当文件块下载完成之后,我们可以通过相同的哈希算法,对下载好的文件块逐一求哈希值,然后跟种子文件中保存的哈希值比对。如果不同,说明这个文件块不完整或者被篡改了,需要再重新从其他宿主机器上下载这个文件块。
- 散列函数:对于冲突的要求低很多(即便出现个别散列冲突,只要不是过于严重,我们都可以通过开放寻址法或者链表法解决),更看重的是散列的平均性和哈希算法的执行效率。
- 在分布式系统中的应用:
- 负载均衡:(利用哈希算法替代映射表)通过哈希算法,对客户端IP地址或者会话ID计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。
数据分片:(通过哈希算法对处理的海浪数据进行分片,多机分布式处理,突破单机资源限制)
1、如何统计“搜索关键词”出现的次数?(难点:搜索日志很大,没办法放到一台机器的内存中;第二:如果只用一台机器处理数据,时间耗费很长)
我们可以先对数据进行分片,然后采用多台机器处理的方法,来提高处理速度(n台机器,从搜索记录的日志文件中,依次独处每个搜索关键词,并且通过哈希函数计算hash值,然后再跟n取模
最终得到的值,就是应该被分配到的机器编号)(MapReduce的基本设计思想)
2、如何快速判断图片是否在图库中?我们同样可以对数据进行分片,然后采用多机处理。我们准备n台机器,让每台机器只维护某一部分图片对应的散列表。我们每次从图库中读取一个图片,计算唯
一标识,然后与机器个数n求余取模,得到的值就对应要分配的机器编号,然后将这个图片的唯一标识和图片路径发往对应的机器构建散列表。
当我们要判断一个图片是否在图库中的时候,我们通过同样的哈希算法,计算这个图片的唯一标识,然后与机器个数n求余取模。假设得到的值是k,那就去编号k的机器构建的散列表中查找。
分布式存储:(利用一致性哈希算法,解决缓存等分布式系统的扩容/缩容导致数据大量搬移的问题)
假设我们有k个机器,数据的哈希值的范围是[0, MAX]。我们将整个范围划分成m个小区间(m远大于k),每个机器负责m/k个小区间。当有新机器加入的时候,我们就将某几个小区间的数据,从原来的机器中搬移到新的机器中。这样,既不用全部重新哈希、搬移数据,也保持了各个机器上数据数量的均衡。
散列表:散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是O(1)的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。
当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标。
散列函数:1. 散列函数计算得到的散列值是一个非负整数;2. 如果key1 = key2,那hash(key1) == hash(key2);3. 如果key1 ≠ key2,那hash(key1) ≠ hash(key2)(这一点即使是MD5/CRC算法也无法完全避免散列冲突)
- 应用:判断单词是否拼写错误(使用Trie树更好);redis的字典是使用链式法来解决散列冲突的,并且使用了渐进式rehash方式进行hash表的弹性扩容
Q:区块链使用的是哪种哈希算法?是为了什么问题而使用的呢?
A:区块链是一块块区块组成的,每个区块分为两部分:区块头和区块体(区块头保存着自己区块体和上一个区块头 的哈希值),因为这种链式关系和哈希值的唯一性,只要区块链上任意一个区块被修改过,后面所有区块保存的哈希值就不对了。区块链使用的是SHA256哈希算法,计算哈希值非常耗时,如果要篡改一个区块,就必须重新计算该区块后面所有的区块的哈希值,短时间内几乎不可能做到。
11.2、hash函数是怎么实现的?
1、散列算法 hash(key)&(capitity-1) //在插入或查找时,计算Key被映射到桶的位置。 当capacity为2的整数倍是该公式才成立。相当于对key的hash值对表厂取模,基于hashmap是2的幂次方特性,这种位运算速度更快。
2、hash的高16bit和低16bit做了一个异或
3、(n-1)&hash 得到下标
4、使用&代替取模,实现了均匀的散列,但效率要高很多,与运算比取模的效率高,由于计算机组成原理
代码:
int hash(Object key){
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小
}
public int hashCode(){
int var1 = this.hash;
if(var1 == 0 && this.value.length > 0){
char[] var2 = this.value;
for(int var3 = 0; var3 < this.value.length; ++var3) {
var1 = 31 * var1 + var2[var3];
}
this.hash = var1;
}
return var1;
}
11.3、hash冲突解决方案:(开放定址法/链表法)
使用链地址法,先找到下标i,KEY值找Entry对象,新值存放在数组中,旧值在新值的链表上,将存放在数组中的Entry设置为新值的next
- 开放定址法
散列表的冲突处理?散列表的冲突处理主要分为闭散列法和开散列法;常用:线性探测法、链地址法 20181230补
1、闭散列法(开放寻址法) 不开辟额外的存储空间 (当数据量比较小、装载因子小的时候,适合采用开放寻址法)
特点
1、不开辟额外的存储空间,还是在原先hash表的空间范围之内
2、当插入元素发生了散列冲突,就逐个查找下一个空的散列地址供插入,直到查找失败
方法
1、线性探测法:将散列表看作是一个循环向量,若初始地址是f(key)=d,则依照顺序d、d+1、d+2…的顺序取查找,即f(key)=(f(key)+1)mod N;(ThreadLocalMap使用的线性探测法)
2、二次探测法:基本思路和线性探测法一致,只是搜索的步长和方向更加的多样,会交替以两个方向,步长为搜索次数的平方来查找 **
3、 双重散列法:通常双重散列法是开放地址中最好的方法,其通过提供hash()和rehash()两个函数,前者产生冲突的时候,定制化后者rehash()重新寻址
2、开散列法(链地址法) 寻找额外的存储空间(基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略)
1、特点
1、一般通过将冲突的元素组织在链表中,采用链表遍历的方式查找
2、解决方法直观,实现起来简单,尤其在删除元素的时候此处只是简单的链表操作
3、开散列法可以存储超过散列表容量个数的元素
2、方法
1、链地址法:相同散列值的记录放到同一个链表中,他们在同一个Bucket中(java中LinkedHashMap采用此方法)
优化方案:将链表法中的链表改造为其他高效的动态数据结构,比如跳表、红黑树。
2、公共溢出法:将所有的冲突都放到一个公共的溢出表中去,适用于冲突情况很小的时候
11.4、面试题
-
1、假设我们有10万条URL访问日志,如何按照访问次数给URL排序
遍历10万条数据,以URL为key,访问次数为value,存入散列表,同时记录访问次数的最大值K,时间复杂度O(N),如果K不是很大,可以使用桶排序,时间复杂度O(N)。如果k非常大(10万),就使用快速排序,复杂度O(NlgN)- demo如下所示:
-
2、有两个字符串数组,每个数组大约有10万条字符串,如何快速找出两个数组中相同的字符串?
以第一个字符串数组构建散列表,key为字符串,value为出现次数。再遍历第二个字符串数组,以字符串为key在散列表中查找,如果value大于零,说明存在相同字符串。时间复杂度O(N)。 -
3、如何避免低效扩容?
当装载因子已经到达阈值,需要先进行扩容,再插入数据,这种操作很低效。解决方案:将扩容操作穿插在插入操作的过程中,分批完成。当装载因子触达阈值之后,我们只申请新空间,但并不将老的数据搬移到新散列表中。
当有新数据要插入时,我们将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。 -
5、如何通过哈希算法生成短网址?(王争的第56讲 http://t.cn是短网址服务的域名)
MurmurHash算法。现在它已经广泛应用到Redis、MemCache、Cassandra、HBase、Lucene等众多著名的软件中。 -
6、编程实现一个基于链表法解决冲突问题的散列表
public class HashTable {
private int tSize;
private int count;
}
public class HashTableNode {
private int blockCount;
private ListNode startNode;//维护的线性表
}
public class 基于散列表解决冲突的散列表 {
public final static int LOADFACTOR = 20;
public static HashTable createHashTable(int size) {
HashTable h = new HashTable();
//count默认设置为0;
h.settSize(size / LOADFACTOR);
for (int i = 0; i < h.gettSize(); i++) {
h.getTable()[i].setStartNode(null);
}
return h;
}
public static int hashSearch(HashTable h, int data) {
ListNode temp;
temp = h.getTable()[Hash(data, h.gettSize())].getStartNode();
while (temp != null) {
if (temp.getVal() ==data) {
return 1;
}
temp = temp.getNext();
}
return 0;
}
//散列函数
public static int Hash(int data, int gettSize) {
int h = data; /* data.hashCode(); */
return (h ^ (h >>> 16)) & (gettSize - 1); // capicity表示散列表的大小
}
}
7、编程实现一个LRU缓存淘汰算法 (使用散列表+链表组合实现缓存淘汰算法)LinkedHashMap(思路牛逼)(双向链表+散列表)(使用双向链表支持按照插入的顺序遍历数据,支持按照访问顺序遍历数据)
一个缓存(cache)系统主要包含下面这几个操作:往缓存中添加一个数据;从缓存中删除一个数据;在缓存中查找一个数据。
①使用双向链表存储数据,链表中每个节点存储数据(data)、前驱指针(prev)、后继指针(next)和hnext指针(解决散列冲突的链表指针)。
②散列表通过链表法解决散列冲突,所以每个节点都会在两条链中。一条链是双向链表,另一条链是散列表中的拉链。前驱和后继指针是为了将节点串在双向链表中,hnext指针是为了将节点串在散列表的拉链中。(牛逼)
- 往缓存中查找一个数据:在散列表中查找数据的时间复杂度为O(1),找到后,将其移动到双向链表的尾部
- 删除数据:在O(1)时间复杂度里找到要删除的结点,双向链表可以通过前驱指针O(1)时间复杂度获取前驱结点
- 添加一个数据:先看这个数据是否已经在缓存中。如果已经在其中,需要将其移动到双向链表的尾部;如果不在其中,还要看缓存有没有满。如果满了,则将双向链表头部的结点删除,然后再将数据放到链表的尾部;如果没有满,就直接将数据放到链表的尾部。
public class LRU缓存淘汰算法{
private ListNode head; //最近最少使用,类似列队的头,出队
private ListNode tail; //最近最多使用,类似队列的尾,入队
private Map<Integer, ListNode> cache;
private int capacity;
public LRU缓存淘汰算法(int capacity){
this.cache = new HashMap<>();
this.capacity = capacity;
}
public int get(int key) {
ListNode node = cache.get(key);
if (node == null) {
return -1;
} else {
moveNode(node);//把该数据移动到链表尾部
return node.value;
}
}
public void put(int key, int value) {
ListNode node = cache.get(key);
if(node != null){
node.value = value;
moveNode(node);//把该数据移动到链表尾部
} else{//缓存满了,移除链表的头结点
removeHead();
addNode(new ListNode(key, value));
}
cache.put(key, node);
}
private void removeHead() {
if (cache.size() == capacity) {
ListNode tempNode = head;
cache.remove(head.key);
head = head.next;
tempNode.next = null;
if (head != null)
head.prev = null;
}
}
private void addNode(ListNode node) {
if (head == null)
head = tail = node;
else
addNodeToTail(node);
}
private void addNodeToTail(ListNode node) {
node.prev = tail;
tail.next = node;
tail = node;
}
//移动数据到链表尾部 分类讨论:第一种要移动的结点是头结点;第二种直接为尾节点,无需处理;第三种为链表中的结点
private void moveNode(ListNode node){
if (head == node && node != tail){
head = node.next;
head.prev = null;
node.next = null;
addNodeToTail(node);
} else if (tail == node){
} else {
node.prev.next = node.next;
node.next.prev = node.prev;
node.next = null;
addNodeToTail(node);
}
}
}
java中有现成的工具可以使用
- LinkedHashMap维护了插入的先后顺序【FIFO】,适合LRU算法做缓存(最近最少使用)(在项目中被用到过)
LinkedHashMap<Long, String> unchecked = new LinkedHashMap<Long, String >(20, .75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Long, String> eldest){
//什么时候执行LRU操作
return this.size() > 20;
}
};
















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











