







我们知道通过 Elasticsearch 实现全文搜索,在文档被导入到 ES 后,文档的每个字段都需要被分析,而这个分析阶段就会涉及到分词。上篇介绍了分词器的概念和常见分词器的使用,然而有些特定场景中,之前的分词器并不能满足我们的实际需求,那么就要进行定制分析器了。
ES 已经提供了丰富多样的开箱即用的分词 plugin,通过这些 plugin 可以创建自己的 token Analyzer,甚至可以利用已经有的 Char Filter,Tokenizer 及 Token Filter 来重新组合成一个新的 Analyzer,并对文档中的每个字段分别定义自己的 Analyzer。基于这些思路,我们则可以实现一个定制的分析器。
举个例子:
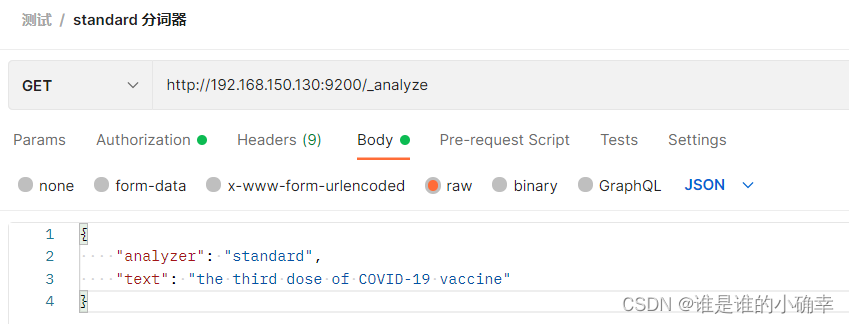
使用 standard 分词器对该文本字符串进行分词,得结果如下:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "third",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "dose",
"start_offset": 10,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "of",
"start_offset": 15,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "covid",
"start_offset": 18,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "19",
"start_offset": 24,
"end_offset": 26,
"type": "<NUM>",
"position": 5
},
{
"token": "vaccine",
"start_offset": 27,
"end_offset": 34,
"type": "<ALPHANUM>",
"position": 6
}
]
}这段文本字符串中的"COVID-19",经过 standard 分词器处理后,却拆分成了"covid"和"19",明显不是我想要的结果,我预期得到的结果是"COVID19"或者"covid19"。那么,该如何实现我预期的分词结果呢?
这里有必要先普及下,我们平时创建某个索引的几个操作姿势:
方式一、简单不做作,直接 PUT
PUT 192.168.150.130:9200/mytest_index方式二、创建索引同时指定"settings"
PUT 192.168.150.130:9200/mytest_index
{
"settings":{
"index":{
// 创建索引的同时设置分片数、副本数
"number_of_shards":"3",
"number_of_replicas":"1"
}
}
}方式三、创建索引同时指定"mappings"
PUT 192.168.150.130:9200/mytest_index
{
"mappings":{
"_doc":{
"properties":{
"city":{
"type":"keyword"
},
"date":{
"type":"keyword"
},
"quantity":{
"type":"integer"
},
"description":{
"type":"text"
}
}
}
}
}其他方式:创建索引同时指定"settings"、"mappings"、"aliases"等(看实际需求)
PUT 192.168.150.130:9200/mytest_index
{
"mappings":{
........
},
"aliases": {
........
},
"settings": {
........
}
}有了这些知识点储备之后,实现预期的分词结果就简单了,基本思路是:创建索引的同时,通过 "mappings" 设置该字段的属性并为该字段自定义一个分析器,然后通过 "settings" 设置 Char Filter、Tokenizer 及 Token Filter 来重新组合成一个新的 Analyzer。具体实现如下:
PUT 192.168.150.130:9200/mytest_index
{
"mappings": {
"_doc": {
"properties": {
"city": {
"type": "keyword"
},
"date": {
"type": "keyword"
},
"quantity": {
"type": "integer"
},
"description": {
"type": "text",
"analyzer": "my_description_analyzer"
}
}
}
},
"settings": {
"analysis": {
"char_filter": {
"covid19_filter": {
"type": "mapping",
"mappings": [
"COVID-19 => COVID19"
]
}
},
"analyzer": {
"my_description_analyzer": {
"type": "custom",
"char_filter": [
"covid19_filter"
],
"tokenizer": "standard",
"filter": [
// 转小写输出covid19,如果注释掉的话则会输出COVID19
"lowercase"
]
}
}
}
}
}请注意,由于我使用的 ES 版本是6.8.6,通过"mappings"设置字段属性时,需要加上文档类型"_doc",不然会报错的,而在高版本的 ES 中创建索引时,则不会再加上"_doc"(高版本 ES 的文档 type 已被抛弃)。
测试效果如下:
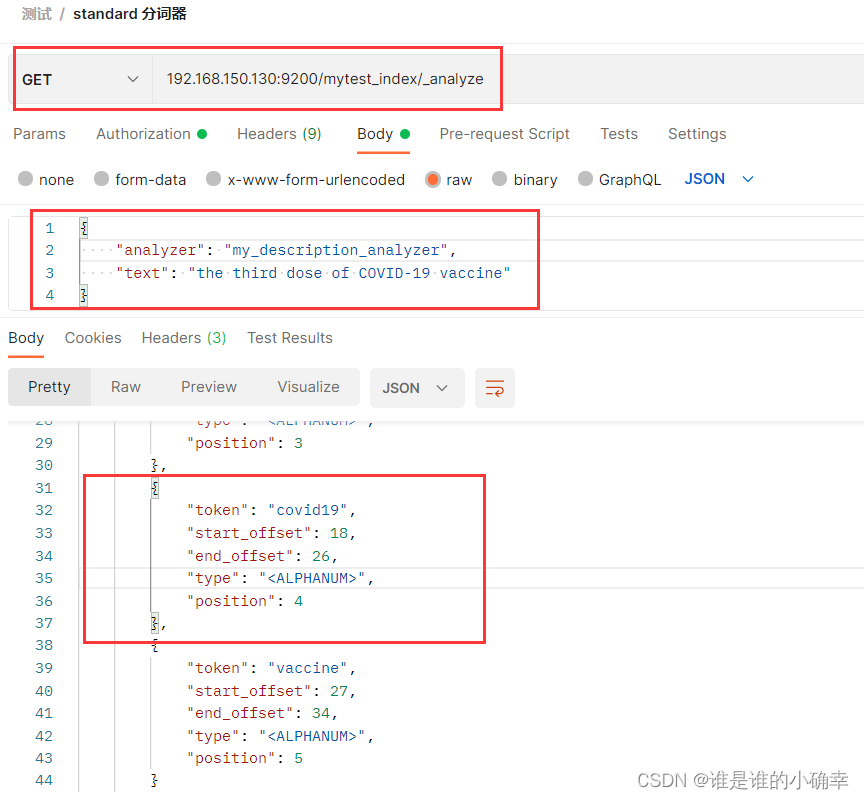
这样就实现了预期的分词结果。另外,像 "the"、"of" 这些停用词,standard 分词器是不会过滤掉的,如果我就要过滤掉这些停用词,或者加入我认为要过滤掉的单词,这个该如何实现呢?
在上篇文章分词器概念中,介绍说明过分词器的分析阶段(Analysis Phase),剔除已拆分的单词可在 Token Filter 实现。还是以 mytest_index 索引创建为例,在原来基础上加入以下内容(原设置已省略,重点在"filter"、"my_stop"):
PUT 192.168.150.130:9200/mytest_index1
{
"mappings": {
......
},
"settings": {
"analysis": {
"char_filter": {
......
},
"analyzer": {
"my_description_analyzer": {
"type": "custom",
"char_filter": [
"covid19_filter"
],
"tokenizer": "standard",
"filter": [
// 转小写输出covid19,如果注释掉的话则会输出COVID19
//"lowercase",
"my_stop"
]
}
},
"filter":{
"my_stop":{
"type":"stop",
"stopwords": ["the", "a", "of", "is"]
}
}
}
}
}
去掉停用词后,测试效果如下:
{
"tokens": [
{
"token": "third",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "dose",
"start_offset": 10,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "COVID19",
"start_offset": 18,
"end_offset": 26,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "vaccine",
"start_offset": 27,
"end_offset": 34,
"type": "<ALPHANUM>",
"position": 5
}
]
}最后,请注意 Token Filter 过滤顺序的问题,假如我把文本字符串修改为"The third dose of COVID-19 vaccine",并把"lowercase" 和 "my_stop"调换下顺序,如下:
"analyzer": {
"my_description_analyzer": {
"type": "custom",
"char_filter": [
"covid19_filter"
],
"tokenizer": "standard",
"filter": [
"my_stop",
"lowercase"
]
}
}那么得到的分词结果为:["the" "third" "dose" "covid19" "vaccine"],看出问题了吧?"the" 是被定义成停用词的,但分词结果却有这个单词。经过分析不难看出:这是由于执行"my_stop"时并没有把"The"看作是停止词,接着经过"lowercase"处理时输出了"the"。这就提示我们过滤顺序的重要性啊!!
在上篇文章提及过,Analyzer 将文本字符分解为 token 的过程,通常会发生在以下两种场景:一是索引建立的时候,二是进行文本搜索的时候。
第一种场景刚刚已经演示过了,在索引建立后,如果要录入一个文档的话,该文档在被写入索引之前,会将文档中的文本字符串分解成一个个 token,这些 token 是存放到数据库的;
第二种场景则是进行文本搜索,文本搜索的时候也会对该字符串进行分词,也会建立 token,但不会存放到数据库。默认情况下,我们查询搜索时会使用到第一种场景定制的分析器,很明显会导致某些查询问题,比如查询 "of" 是查不到结果的,因此有必要区分第一种场景的分析器。我们可以通过 search_analyzer 实现:
PUT 192.168.150.130:9200/mytest_index
{
"mappings": {
"_doc": {
"properties": {
"city": {
"type": "keyword"
},
"date": {
"type": "keyword"
},
"quantity": {
"type": "integer"
},
"description": {
"type": "text",
"analyzer": "my_description_analyzer",
"search_analyzer": "standard"
// 也可以使用自定义的分词器 "search_analyzer": "my_search_analyzer"
}
}
}
},
"settings": {
......
}
}最后
本文重点在介绍说明如何实现自定义的分析器,以满足特定场景的需求,并通过演示说明了实现的思路。然而,实际需求总是五花八门多种多样的,掌握实现的思路和原理才是最重要的。比如,如何实现多个不同的分析器搜索查询相同的文本内容(思路是使用 multi-field 实现,即 fields 设置多字段),建议参考学习【Elasticsearch:将精确搜索与词干混合】这篇博文;又比如,在定制分析器时考虑定制相关性(通过 function_score 实现定制相关性),建议参考学习【Elasticsearch:定制分词器(analyzer)及相关性】这篇博文。
下篇将开始介绍说明 ES 索引及索引文档的 CRUD 操作,属于基础内容,但也是平时工作必备的知识点。















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









