







最近遇到一个需求,大致内容是:要通过 Elasticsearch 存储 A、B 两部分数据,A 是存在重复数据的,需要与 B 进行比较,从而把 A 的重复数据找到并输出到结果文件。
目标很明确,重点就在于设计 Elasticsearch 文档的数据结构了,最初的设计结构是这样的:
{
"_index":"filter_a_index",
"_type":"_doc",
"_id":"xxxxxxxxxxx_yyyyyy_202207",
"_score":1,
"_source":{
"aFlag":1,
"bFlag":1,
"comparKey":"xxxxxxxx_yyyyyy_202207",
"aObj":{
"aList":{
"唯一订单号1":"唯一订单号1|xxxxxxxxxxx|yyyyyy|20220701032432|2|4|1000",
"唯一订单号2":"唯一订单号2|xxxxxxxxxxx|yyyyyy|20220702235959|1|9|1000"
},
"update_date":"20220706"
},
"bObj":{
"bList":{
"唯一订单号1":"唯一订单号1|xxxxxxxxxxx|yyyyyy|20220701032432|2|4|1000"
},
"update_date":"20220706"
}
}
}为了方便描述和梳理,我把实际的 pkey、xxxObj、xxxFlag 等这类字段都替换成了 comparKey、aObj、aFlag 说明。
这里,我把"唯一订单号"字段作为 key,其他字段用 | 拼接作为 value,这样就组装成一个 map,如果遇到相同的 comparKey 则会把新的 map 加入到 aList,这样是符合在 ES 存储重复数据的要求,看上去没什么问题。
在执行 Job 任务测试时发现,过段时间日志会一直报 60s 超时,无法写入 ES,如下:

接着,就是漫长的问题排查过程了,从代码是否存在 bug ,到怀疑 ES 集群环境问题,经过反复测试,最终找到了原因,真的是一波三折啊。原因在于,ES 文档的 key 的数量超过了预设值 5W 个,超过这个数量就无法写入ES了,可通过这个语句查看该索引的 mappings:
GET filter_a_index如图:
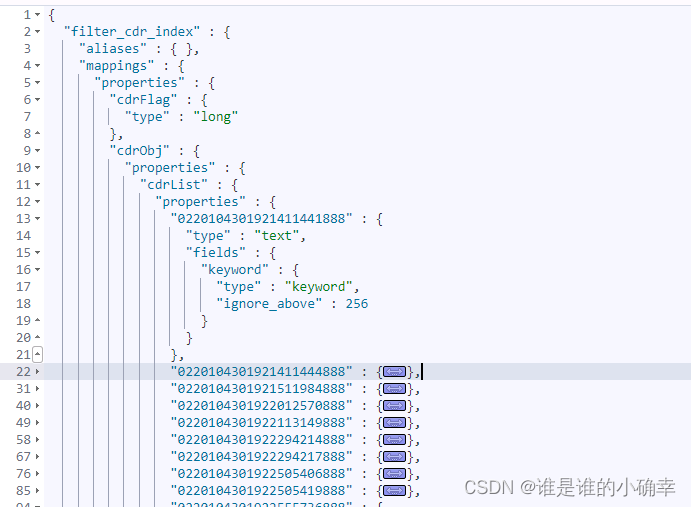
使用"唯一订单号"字段当做 key,当 key 的数量一旦超过 5W 限制就无法写入 ES,这就是原因所在了。然后,经过一番分析,本着越简单越好的原则,又把数据结构调整成了这样:
{
"_index":"filter_a_index",
"_type":"_doc",
"_id":"xxxxxxxxxxx_yyyyyy_202207",
"_score":1,
"_source":{
"aFlag":1,
"bFlag":1,
"comparKey":"xxxxxxxx_yyyyyy_202207",
"aObj":[
"唯一订单号1|xxxxxxxxxxx|yyyyyy|20220701032432|2|4|1000",
"唯一订单号2|xxxxxxxxxxx|yyyyyy|20220702235959|1|9|1000"
],
"bObj":[
"唯一订单号1|xxxxxxxxxxx|yyyyyy|20220701032432|2|4|1000"
]
}
}到这儿,又遇到了如何定义 aObj 和 bObj 的数据类型问题了。我想要的 aObj 和 bObj 是数组类型,而 ES 支持的数组是数组对象(Nested),而不是数组字符串,也就是说 Nested 类型支持的是这样存储数据:
"aObj":[
{
"orderId":"唯一订单号1",
"mobile":"xxxxxxxxxxx",
......
"payAmount":1000
},
{
"orderId":"唯一订单号2",
"mobile":"xxxxxxxxxxx",
......
"payAmount":1000
}
]于是,我在创建索引时,只能把 aObj 和 bObj 设置成文本类型了,索引创建语句如下:
PUT filter_a_index
{
"settings": {
"index": {
"number_of_shards": "9",
"number_of_replicas": "0",
"refresh_interval": "3s",
"translog": {
"durability": "async",
"flush_threshold_size": "1024mb",
"sync_interval": "120s"
},
"merge": {
"scheduler": {
"max_thread_count": "2"
}
},
"mapping": {
"total_fields": {
"limit": 50000
}
}
}
},
"mappings": {
"properties": {
"comparKey": { "type": "keyword" },
"aObj": { "type": "text" },
"aFlag": { "type": "long" },
"bObj": { "type": "text" },
"bFlag": { "type": "long" }
}
}
}最后,在代码里使用 ES scripts 实现设置 aObj 、bObj 成数组,并存储重复的数据,核心代码逻辑大致如下:
Script script = new Script(ScriptType.INLINE,
"painless",
"if(!(ctx._source.aObj instanceof List)){ctx._source.aObj = [];}" +
"if(params.aFlag==1){ctx._source.aObj.addAll(params.aObj);}" +
"ctx._source.aFlag = params.aFlag",
params);
UpdateQuery.Builder updateQueryBuilder = UpdateQuery.builder(comparKey)
.withAbortOnVersionConflict(false)
.withRetryOnConflict(100)
.withRefreshPolicy(RefreshPolicy.IMMEDIATE)
.withScript(script.getIdOrCode())
.withScriptedUpsert(true)
.withParams(script.getParams());
restTemplate.update(updateQueryBuilder.build(),
restTemplate.getIndexCoordinatesFor(XxxxxInfo.class));最终存储到 ES 实现的效果如下:
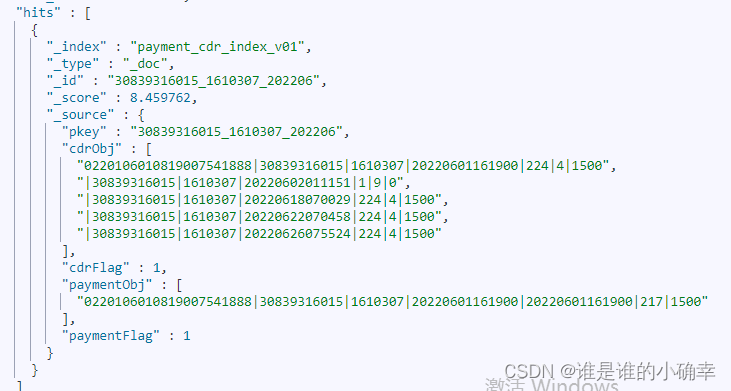
为了实现这个需求,可谓是一波三折啊,通过这次教训也明白了 ES 文档对 key 数量的限制,也学到了如何不用数组对象(Nested)而实现保存字符串到数组的方式。ES 脚本确实很强大,值得深入学习了解。吃一堑长一智,下次应该就不会再出现这样的问题了,哈哈哈~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









