




 本文介绍了中文分词工具Jieba的使用方法,包括分词模式、词性标注、关键词提取等内容,并通过实例展示了如何调整分词效果及生成词云。
本文介绍了中文分词工具Jieba的使用方法,包括分词模式、词性标注、关键词提取等内容,并通过实例展示了如何调整分词效果及生成词云。
在自然语言处理中,分词是一项最基本的技术。中文分词与英文分词有很大的不同,对英文而言,一个单词就是一个词,而汉语以字为基本书写单位,词语之间没有明显的区分标记,需要人为切分。现在开源的中文分词工具有 SnowNLP、THULAC、Jieba 和 HanLP 等,这里梳理下 Jieba 组件的内容。
一、Jieba 组件介绍
中文分词技术是中文信息处理的基础,有着极其广泛的实际应用,比如:汉语语言理解、机器翻译、语音合成、自动分类、自动摘要、数据挖掘和搜索引擎等,都需要对中文信息进行分词处理。因此,一个中文分词算法的好坏,会对其后续的应用产生极大的影响。
1、算法
Jieba 是一个立志于做最好的 Python 中文分词组件,主要涉及的算法有:
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
- 对于未登录词,采用基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
2、分词模式
Jieba 支持4种模式的分词:精准模式、全模式、搜索引擎模式及 paddle 模式,特点如下:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式:利用 PaddlePaddle 深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。
请注意,paddle 模式使用需安装 paddlepaddle-tiny。目前 paddle 模式支持 jieba v0.40 及以上版本,如果是 jieba v0.40 以下版本,需要升级 jieba,命令如下:
# 安装paddlepaddle-tiny
pip install paddlepaddle-tiny==1.6.1
# 升级jieba
pip install jieba --upgrade此外,Jieba 还支持中文繁体分词、自定义词典、关键词提取、词性标注、并行分词、ChineseAnalyzer for Whoosh搜索引擎等功能。
二、Jieba 安装与使用
1、安装
jieba 给出了多种的安装方式及说明,参考如下:

我采用的是 pip 命令下载,安装的最新版本是 v-0.42.1:
pip install jieba2、分词模式的使用
jieba 分词常用的函数,如下:
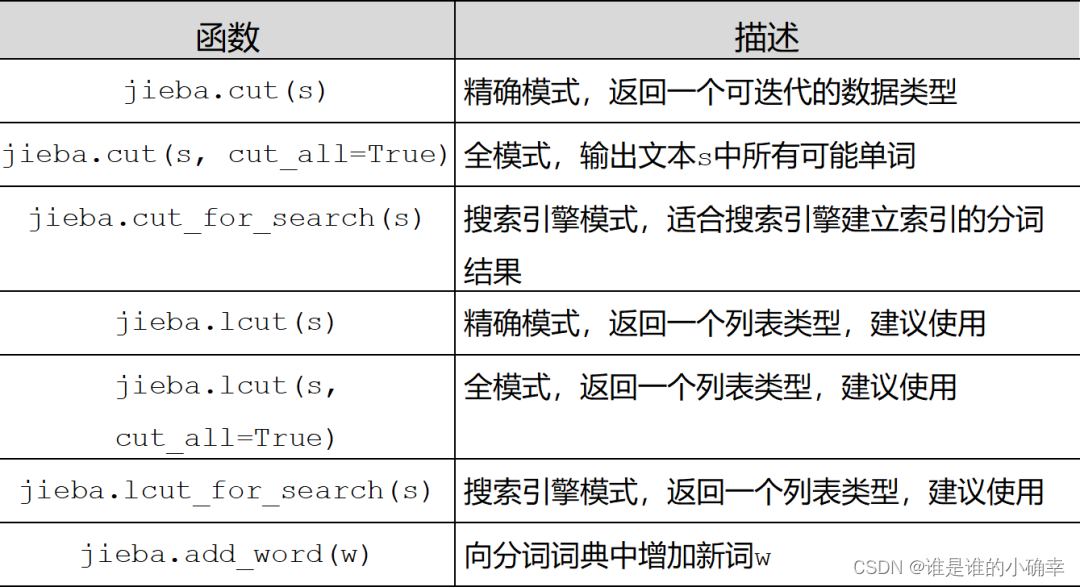
jieba.Tokenizer(dictionary=DEFAULT_DICT) 是新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射,通过源码可以看到:
# default Tokenizer instance
dt = Tokenizer()
# global functions
get_FREQ = lambda k, d=None: dt.FREQ.get(k, d)
add_word = dt.add_word
calc = dt.calc
cut = dt.cut
lcut = dt.lcut
cut_for_search = dt.cut_for_search
lcut_for_search = dt.lcut_for_search
del_word = dt.del_word
get_DAG = dt.get_DAG
get_dict_file = dt.get_dict_file
initialize = dt.initialize
load_userdict = dt.load_userdict
set_dictionary = dt.set_dictionary
suggest_freq = dt.suggest_freq
tokenize = dt.tokenize
user_word_tag_tab = dt.user_word_tag_tab下面,用前3种的分词模式为例,演示如下:
import jieba as jieba
def choice_mode(num):
list_mode = []
text = '灰树叶飘转在池塘,看飞机轰的一声去远乡'
if num == "1":
# 精准模式,cut_all默认False
list_mode = jieba.lcut(text)
elif num == "2":
# 全模式
list_mode = jieba.lcut(text, cut_all=True)
elif num == "3":
# 搜索引擎模式
list_mode = jieba.lcut_for_search(text)
return list_mode测试1:精准模式
if __name__ == '__main__':
# 灰/树叶/飘转/在/池塘/,/看/飞机/轰的一声/去/远乡/
list_mode = choice_mode("1")
for i in list_mode:
print(i, end="/")测试2:全模式
if __name__ == '__main__':
# 灰/树叶/飘/转在/池塘/,/看/飞机/轰的一声/一声/去/远/乡/
list_mode = choice_mode("2")
for i in list_mode:
print(i, end="/")测试3:搜索引擎模式
if __name__ == '__main__':
# 灰/树叶/飘转/在/池塘/,/看/飞机/一声/轰的一声/去/远乡/
list_mode = choice_mode("3")
for i in list_mode:
print(i, end="/")从上面的结果可以看出,对于文本类型,精准模式分词是最准确的。
3、调整分词
有时候,我们更需要把文本里的"灰树叶"当成一个词语看待,jieba 提供了 add_word() 方法,可以实现分词的调整。新增如下代码:
jieba.add_word("灰树叶") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









