







目录
第二章 object_detection开源框架使用案例入门
第四章 基于tensorflow-cpu的object_detection开源框架模型训练
第五章 基于GPU服务器的object_detection开源框架模型训练
第四章 基于tensorflow-cpu的object_detection开源框架模型训练
本节主要搭建的tensorflow环境是CPU版本(tensorflow-cpu)的,所有操作均在服务器192.168.6.175上运行,并使用自己的训练集进行模型训练操作。
4.1 ssd模型
本节采用ssd模型进行物体检测。
4.1.1 数据集处理及相关文件准备
- 数据集准备
此时利用第三章的工具已标注了三个标签的批量数据集(car、bike、person),数据存放参照Pascal VOC2007数据目录(数据存放在VOCdevkit/VOC2007目录下)
–VOCdevkit
–VOC2007
–JPEGImages
–存储批量.jpg图片
–ImageSets
–Main
–train.txt,训练集图片名称(不带后缀.jpg,一行一个)
–val.txt,测试集图片名称(不带后缀.jpg,一行一个)
–Annotations
–存储批量标注.xml文件
数据集存储目录情况如上所示,其中JPEGImages文件夹存放所有图片, ImageSets文件夹下有一个Main文件夹,Main下面存放train.txt和val.txt,分别为训练、测试集的图片名称(不带后缀.jpg,一行一个),txt文件需提前准备,Annotations文件夹存放图片标注xml文件。
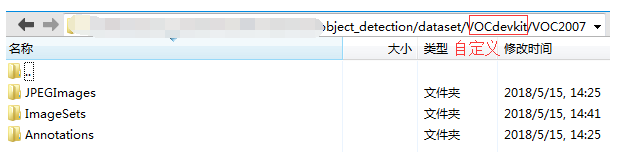
- 创建dataset文件夹
# cd /home/users/py3_project/models/research/object_detection # 程序全部在此目录下运行,root用户
# mkdir dataset
- 将准备好的VOCdevkit\VOC2007数据集,放到dataset目录下,如上图
- 复制models\research\object_detection\dataset_tools\create_pascal_tf_record.py文件到dataset目录下
- 复制models\research\object_detection\data\pascal_label_map.pbtxt文件到dataset目录下
- 复制models\research\object_detection\samples\configs\ssd_mobilenet_v1_pets.config到dataset目录下
4.1.2 转换数据集为tf_record格式
- 将dataset/pascal_label_map.pbtxt改为自己的标签,如下所示

- 修改dataset/create_pascal_tf_record.py第160行,主要是路径问题:

在当前目录/home/users/py3_project/models/research/object_detection下,
执行以下命令:
# mkdir dataset/image_tfrecord
# python3 dataset/create_pascal_tf_record.py \
--data_dir=dataset/VOCdevkit \
--label_map_path=dataset/pascal_label_map.pbtxt \
--year=VOC2007 \
--set=train \
--output_path=dataset/image_tfrecord/pascal_train.record
# python3 dataset/create_pascal_tf_record.py \
--data_dir=dataset/VOCdevkit \
--label_map_path=dataset/pascal_label_map.pbtxt \
--year=VOC2007 \
--set=val \
--output_path=dataset/image_tfrecord/pascal_val.record
4.1.3 下载预训练模型
# wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_11_06_2017.tar.gz
# tar -xvf ssd_mobilenet_v1_coco_11_06_2017.tar.gz
将解压好的预训练模型目录重命名为model_ssd,存入dataset目录下。
4.1.4 修改相关配置文件
1 修改配置文件:dataset目录下的ssd_mobilenet_v1_pets.config重命名为ssd_mobilenet_v1_pascal.config
- 修改类别数
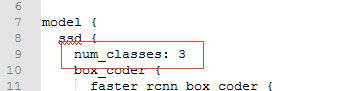
- 修改预训练模型路径
fine_tune_checkpoint: “/home/users/py3_project/models/research/object_detection/dataset/model_ssd/model.ckpt” - 修改输入训练数据配置信息
train_input_reader: {
tf_record_input_reader {
input_path: “/home/users/py3_project/models/research/object_detection/dataset/image_tfrecord/pascal_train.record”
}
label_map_path: “/home/users/py3_project/models/research/object_detection/dataset/pascal_label_map.pbtxt”
} - 修改预测数据配置信息
eval_input_reader: {
tf_record_input_reader {
input_path: “/home/users/py3_project/models/research/object_detection/dataset/image_tfrecord/pascal_val.record”
}
label_map_path: “/home/users/py3_project/models/research/object_detection/dataset/pascal_label_map.pbtxt”
shuffle: false
num_readers: 1
} - 修改eval_config的num_examples,并添加coco评估指标(后两行)
eval_config: {
num_examples: 93
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
eval_interval_secs: 10
metrics_set: “coco_detection_metrics”}
4.1.5 进行模型训练
# python3 train.py \
--logtostderr \
--pipeline_config_path=dataset/ssd_mobilenet_v1_pascal.config \
--train_dir=dataset/train_dir
可视化训练loss,运行
# tensorboard --logdir= path to/train_dir

4.1.6 模型预测与评估
# mkdir dataset/eval_result
# python3 eval.py \
--logtostderr \
--pipeline_config_path=dataset/ssd_mobilenet_v1_pascal.config \
--checkpoint_dir=dataset/train_dir \
--eval_dir=dataset/eval_result
可视化测试图片结果及评估指标,运行
# tensorboard --logdir= path to/ eval_result
4.1.7 转换为图文件
将model.chk文件转换为graph
# python3 export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path=dataset/ssd_mobilenet_v1_pascal.config \
--trained_checkpoint_prefix=dataset/train_dir/model.ckpt-21883 \
--output_directory=dataset/inference_graph
4.1.8 测试图片
(1)单张图片测试
当前目录/home/users/py3_project/models/research/object_detection下test.py文件两个路径修改为自己的路径及修改NUM_CLASS:

使用 VNC-Viewer 客户端
执行
# python3 test.py test_images/image3.jpg


(2)批量图片测试
修改test.py代码,将其修改为批量图片测试代码,命名为testimages.py,其中结果保存为.json文件形式。
运行下列代码:
# python3 testimages.py \
datasetvoc/inference_graph/frozen_inference_graph.pb \
datasetvoc/pascal_label_map.pbtxt \
test_images/ \
datasetvoc/inference_graph/result_annos.json
打开生成的result_annos.json,部分截图如下:

4.1.9 测试视频
此时用的是Pascal VOC2007训练的模型进行测试,因为类别较多。
方法一:采用VideoCapture对视频进行处理的方法(边播放识别,某些模型有点卡)
-
当前目录/home/users/py3_project/models/research/object_detection下testvideo1.py文件两个路径修改为自己的路径及修改NUM_CLASS
-
并加入读取视频代码(视频为一帧帧图像),其中cv2.VideoCapture(0)时为摄像头实时摄像,下面是读取视频文件方式:
使用 VNC-Viewer 客户端,执行
# python3 testvideo1.py test_images/test.mp4
方法二:基于moviepy中的VideoFileClip进行的识别(处理等待过程慢,10s的视频需处理几分钟,最后结果生成视频文件)
-
开头加入需要的依赖包
-
当前目录/home/users/py3_project/models/research/object_detection下testvideo2.py文件两个路径修改为自己的路径及修改NUM_CLASS
-
使用 VideoFileClip 函数从视频中抓取图片,用fl_image函数将原图片替换为标注修改后的图片,所有修改的剪辑图像被组合成为一个新的视频。物体标注过程调用函数detect_objects,与原代码相同。

-
还可以将mp4文件转化为gif格式
from moviepy.editor import *
clip1 = VideoFileClip("test-out.mp4")
clip1.write_gif("test-out.gif")
执行
# python3 testvideo2.py test_images/test.mp4
4.2 faster-rcnn模型
本节采用faster-rcnn模型进行物体检测,在依次执行4.1.1-4.1.9步骤时修改以下几步,其他步骤不变:
- 修改4.1.3步
下载预训练模型(faster-rcnn)
# wget http://download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
# tar -zxvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
将解压好的预训练模型目录重命名为model_fastercnn,存入dataset目录下
- 修改4.1.4步
将dataset中使用的配置文件ssd_mobilenet_v1_pets.config改为使用配置文件models/research/object_detection/samples/configs/faster_rcnn_resnet101_coco.config,并进行修改相同位置的相应配置 - 将配置文件model_ssd相应位置修改为model_fastercnn;将运行的命令行中ssd_mobilenet_v1_pets.config修改为faster_rcnn_resnet101_coco.config
- Python3兼容问题,需修改
models/research/object_detection/utils/learning_schedules.py第167-169行:
rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
range(num_boundaries),
[0] * num_boundaries))
改为:
rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
list(range(num_boundaries)),
[0] * num_boundaries))
4.3 rfcn模型
本节采用rfcn模型进行物体检测,在依次执行4.1.1-4.1.9步骤时修改以下三步,其他步骤不变:
- 修改4.1.3步
下载预训练模型(rfcn)
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
进入上面提供的官网开源框架网址后,点击COCO-trained models中的rfcn_resnet101_coco预训练模型进行下载。
将解压好的预训练模型目录重命名为model_rfcn,存入dataset目录下 - 修改4.1.4步
将dataset中使用的配置文件ssd_mobilenet_v1_pets.config改为使用配置文件models/research/object_detection/samples/configs/ rfcn_resnet101_coco.config,并进行修改相同位置的相应配置 - 将配置文件model_ssd相应位置修改为model_rfcn;将运行的命令行中ssd_mobilenet_v1_pets.config修改为rfcn_resnet101_coco.config















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









