






伴随着不断扩张的业务量,在数据库层面一般会经历数据拆分。解决问题的第一步,就是重新评估DB表结构设计的合理性。我们开发者会对表结构和业务代码进行重构,在之前的文章《业务系统重构》我有提到过。
大表问题
我实际遇到的是怎么样的情况呢?下面我简单介绍下(做了脱敏处理):
过去对表结构设计时,研发由于忽略了业务原子性,使用了一个大字段(TEXT/LONGTEXT/JSON等)存储了耦合业务的大数据字段,如今表行数已经超过1亿了,总使用空间超过100G;虽然碎片率不高,但仍有1.97GB的碎片空间。
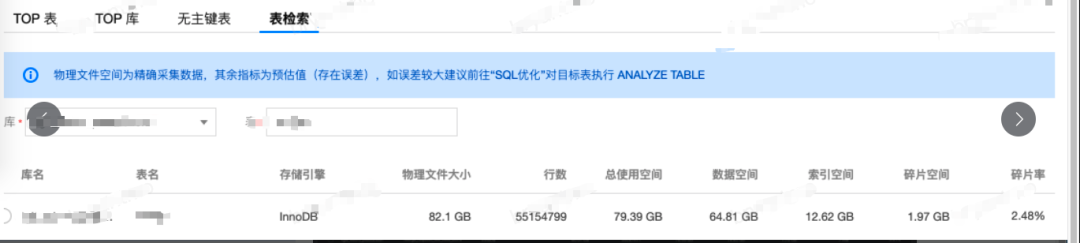
DB大表的存在导致了诸多问题:
1、读查询:每次带大字段的SQL被执行了,都会引起从 DB-Server 到 应用服务 之间的一次大数据量传输;如果SQL执行并发量大,吃机器内存的情况,将发生在Mysql-Server和应用容器中,甚至OOM;
2、业务拓展:业务是不断往前迭代的,意味着针对这个表,将不断有DDL和DML的SQL被执行;这也注定了,如果不对大表进行瘦身,第1点提到的问题,将是一颗定时炸弹,埋在不断被堆积的业务里;
3、DB运维:在追求平滑升级的背景下,我们对表结构变更时,一般选择是在业务低峰期,对临时表进行拷贝,然后执行DDL变更(增删字段和索引),最后通过rename完成业务切换;大表的临时表将具有跟原表同样大小体积,这对运维来说,每次备份大表都是一个巨大的资源和时间开销。
4、业务隐患:为了完成DB高可用部署,我们的业务上云之后,采取了一主多从的部署架构。因此DDL变更期间,由于强同步配置,难免造成从库的数据延迟问题。
大表的垂直拆分
数据库拆分原则:就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
数据库拆分,分为水平和垂直拆分两种;
- 水平拆分的典型场景就是大家熟知的分库分表;
- 垂直拆分则倾向于表重构,按照业务维度进行数据切割。
winter
上文讲了大表背景下导致的种种问题,基于上述原因,我们团队决定趁着重构的机会,进行一次大表垂直拆分:大字段迁移。
经过和DBA的一起分析,发现该表存在一个LONGTEXT的字段,它占用了几乎整个表体积空间的60%以上。
在处理这个大表的问题上,我们有考虑过水平拆分的手段。

按照某种策略(基于项目id,基于用户id,基于冷热项目等),但始终不能较好的将数据均匀平摊到每个分表,甚至会因为热点项目再次带来大表问题,因此并不采纳这个方案。
我们最终选择垂直拆分的方案。

原因是这个大字段,本身就是一个结构化的对象数据,结构化对象最终可以抽象成一张表。通过将这个大字段拆分到一个新表,随后完成旧表的数据迁移和清理。

解决方案
制定了DB变更方案之后,我们要按照真实环境部署来完善方案细节。
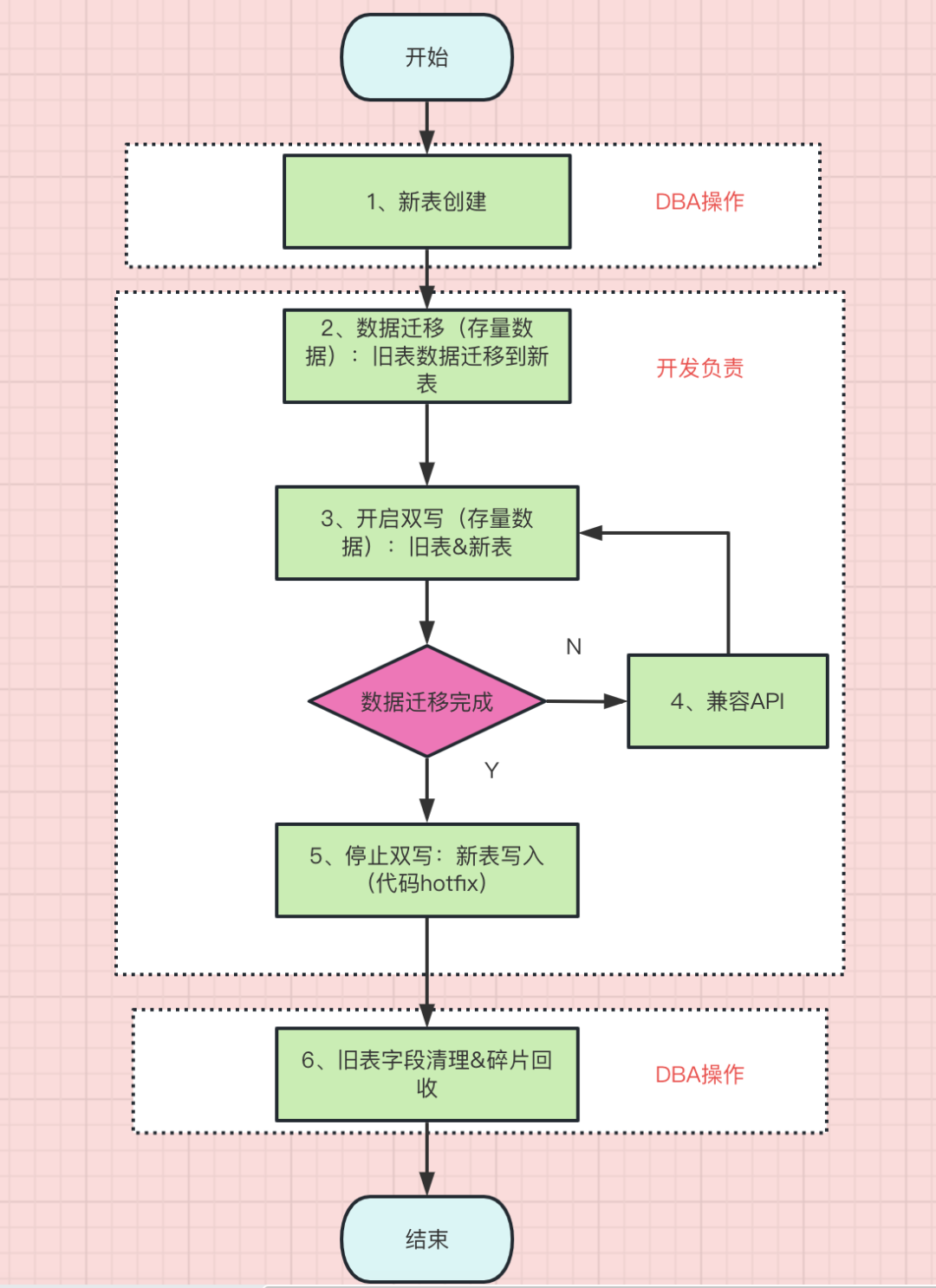
1、新表创建:这类SQL操作,我们都会提单给DBA评估执行。
2、数据迁移(存量数据):这里我们用定时任务来完成。
如果简单使用UPDATE务,会带来表锁的开销,这会直接影响线上业务;我们是不停服变更,因此绝对不能影响正常业务。
定时任务逻辑很简单:查出一条老数据,插入一条新数据。这里建议直接设定一个区间,按照主键ID来遍历;否则通过任何索引+分页的手段,最后都会面临深度分页带来的性能问题,属于是本末倒置了。
3、开启双写(增量数据):正常业务是会源源不断产生增量数据的,此时要确保数据在新旧表都有一份,这样才能完全兼容业务。
4、兼容API:数据迁移是需要切换时间的,这个缓冲期需要保持对API的兼容,包括对新表or旧表的读操作,其他依赖业务的读操作等。
5、关闭双写:数据迁移完成后,老表的字段不需要再写入数据,因此可以修改Insert的SQL,停止该字段写入。
6、清理旧表:确认线上业务不依赖旧表之后,DBA可以进行磁盘碎片回收。
往期推荐
《源码系列》
《互联网技术峰会》
《经典书籍》
《Java并发编程实战:第2章 影响线程安全性的原子性和加锁机制》
《Java并发编程实战:第3章 助于线程安全的三剑客:final & volatile & 线程封闭》
《服务端技术栈》
《算法系列》
《设计模式》















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









