







背景
之前写过关于线程池的源码分析文章:一文读懂JDK源码:ThreadPoolExecutor,但实际上还有很多地方值得思考的。
对ThreadPoolExecutors的思考
业务定制化ThreadPoolExecutors,而不直接复用Executor的5个现成方法去构建线程池,因为原来的API方式有弊端:
1、单线程池,预设资源很可能不够用。
2、无界队列,工作池子出问题,默认的maximumPoolSize=Integer.MAX_VALUE,可能导致工作线程池子无限吃内存,占用大量资源,导致内存溢出
3、固定工作线程池子,任务队列出问题,默认的阻塞队列capacity=Integer.MAX_VALUE,如果生产速度>消费速度,可能导致大量任务滞留内存,导致内存溢出
反思一:如何定制化ThreadPoolExecutors?
工具类示例
public class ThreadPoolUtils {
public static ThreadPoolExecutor newThreadPool(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler
){
if (handler == null) {
handler = new ThreadPoolExecutor.AbortPolicy();
}
if (threadFactory == null) {
threadFactory = Executors.defaultThreadFactory();
}
return new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
threadFactory,
handler
);
}
}代码分析:7个参数如下
核心线程池的线程数量
最大线程池的线程数量
线程存活时间
存活时间单位
线程工厂
任务提交的拒绝策略
| 参数 | 定义 | 作用 | 备注 |
| corePoolSize | 池子的基本容量 | 长期驻留线程池的工作线程数量 | allowCoreThreadTimeOut为true,该值为true,则线程池数量最后销毁到0个。 |
| maximumPoolSize | 池子的最大容量 | 定义池子最大容量 | allowCoreThreadTimeOut为false,会对超出基本容量的线程进行销毁, 销毁机制:超过核心线程数时,而且(超过最大值或者timeout超时),就会销毁。 |
| keepAliveTime | 当线程池线程数量大于corePoolSize时候,多出来的空闲线程,多长时间会被销毁。 | 必须大于0,默认是。0 | |
| unit | 生存时间的单位时间 | 参考枚举类: java.util.concurrent.TimeUnit | |
| workQueue | 工作任务队列 | 用于存放提交但是尚未被执行的任务 | |
| threadFactory | 线程工厂 | 用于创建线程 | |
| handler | 拒绝策略 | 指将任务添加到线程池中时,线程池拒绝该任务所采取的相应策略。 |
反思二:任务阻塞线程池,具体可以用哪种阻塞队列?
观察了一下JDK内置应用案例,大约有以下四种可选方案:
LinkedTransferQueue
SynchronousQueue
LinkedBlockingQueue
ArrayBlockingQueue
先介绍两个几乎不咋用得到的方案:LinkedTransferQueue和SynchronousQueue。
队列 | 特点 | 优点 | 缺点 |
| 无界的阻塞队列 | 它支持一种特殊的操作,即“传输”(transfer),允许生产者线程等待直到消费者线程取走元素。 提供了高效的并发性能,适用于高吞吐量的场景。 | 内存开销不可控 |
| 没有存储空间的队列 | 生产者线程直接将元素传递给消费者线程,而不是先将元素放入队列。 高并发情况下,可以减少内存的使用,并且可以提高系统的吞吐量。 | 不是一个真正的队列,因为它不会在内部存储任何元素。 |
再介绍一下LinkedBlockingQueue 和 ArrayBlockingQueue。
LinkedBlockingQueue 和 ArrayBlockingQueue 都是 Java 并发包 java.util.concurrent 中的阻塞队列实现,它们分别基于链表和数组实现。
队列 | 特点 | 优点 | 缺点 |
| 可以自定义为有界或无界,长度可变(基于链表实现) 提供了基本的阻塞队列功能,如 |
| |
| 必须在创建时指定容量,并且长度不可变(基于数组实现) |
| 要求使用者严格控制内存使用量 |
总结
LinkedTransferQueue:适用于需要传输操作的场景,可以确保生产者线程在放入元素后立即被消费者线程消费。
LinkedBlockingQueue:适用于大多数常规的生产者-消费者场景,提供了基本的阻塞队列功能。
SynchronousQueue:适用于高并发环境,或者需要最小化延迟的场景,因为它不存储任何元素,而是直接在生产者和消费者之间传递。
ArrayBlockingQueue:有界任务队列,跟LinkedBlockingQueue一样提供了基本的阻塞队列功能。
在队列选型时,应根据具体的应用需求和场景来决定。对于他们的源码分析,先挖个坑,后续再补。
反思三:线程池的上下文拷贝复制?
可以参考文章:多线程反思(上):ThreadLocal行不行?TTL也有对线程池进行简单的增强封装。
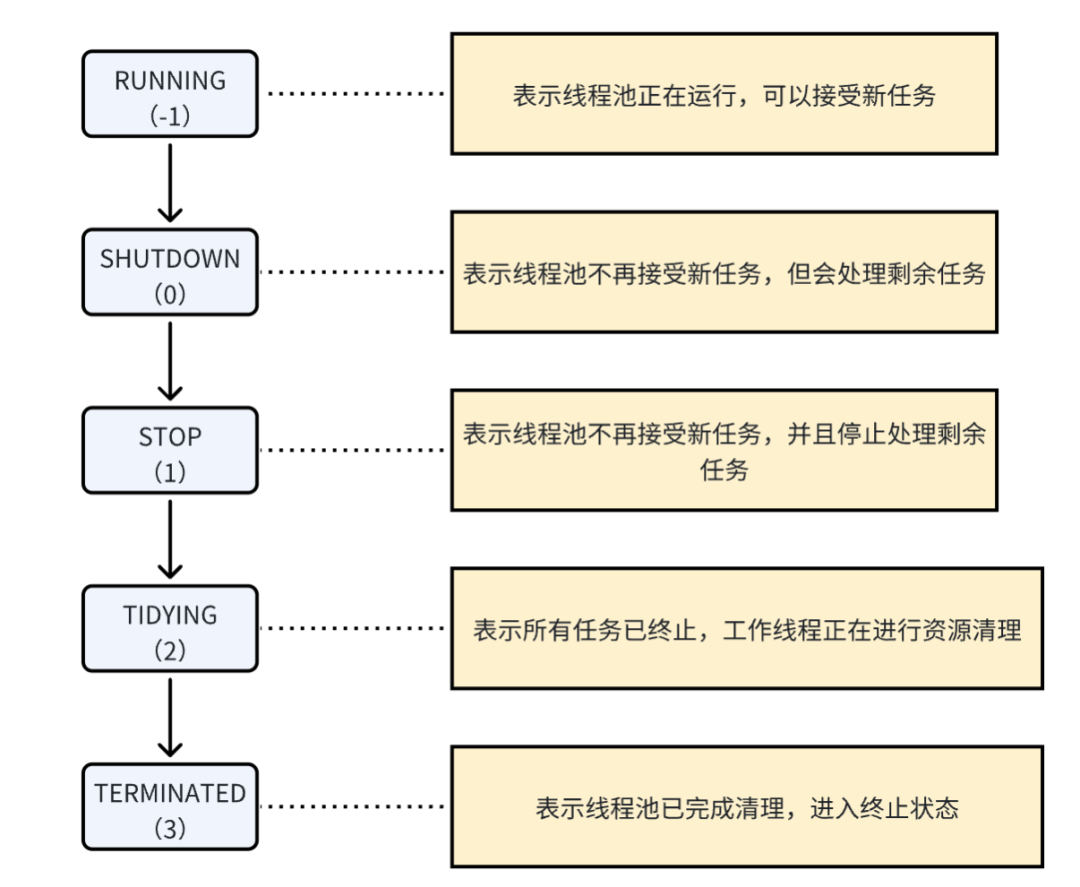
反思四:线程池状态有哪些?
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;下面我们可以总结:
反思五:线程池的生产消费者过程是怎么样的?
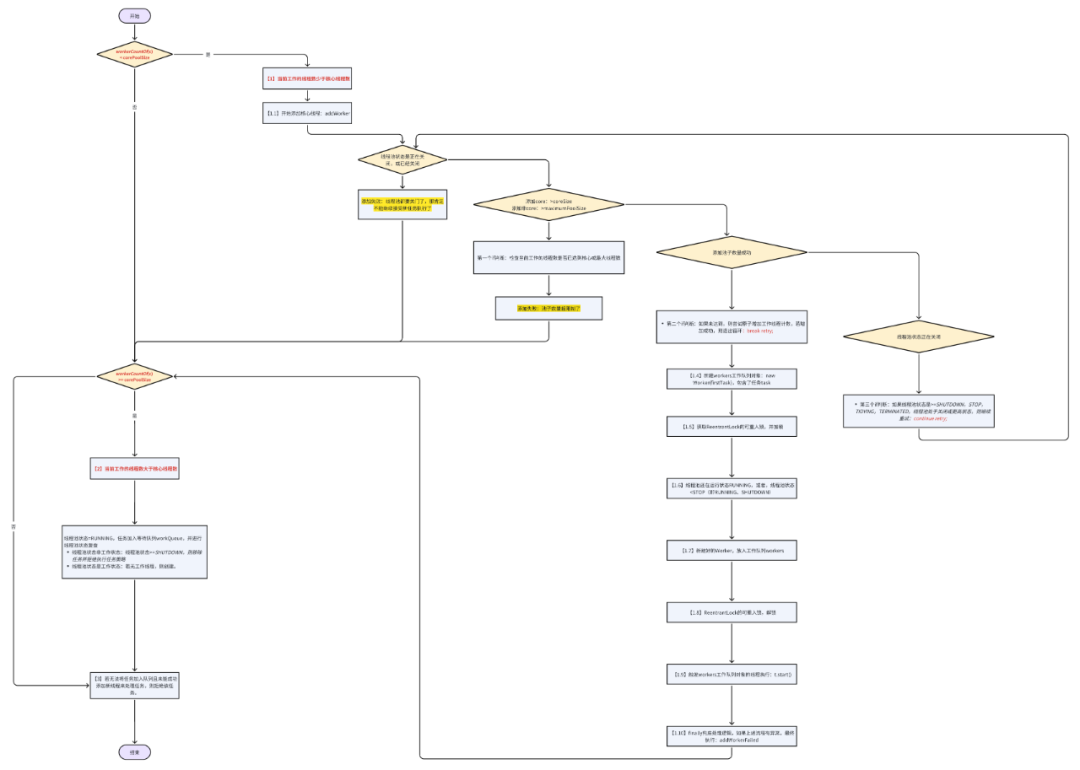
源码分析:ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//【1】
if (workerCountOf(c) < corePoolSize) {
//【1.1】
if (addWorker(command, true))
return;
c = ctl.get();
}
//【2】
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//【3】
else if (!addWorker(command, false))
reject(command);
}
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
// Check if queue empty only if necessary.
//【1.2】
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
//【1.3】
for (;;) {
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//【1.4】
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//【1.5】
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
//【1.6】
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
if (t.getState() != Thread.State.NEW)
throw new IllegalThreadStateException();
//【1.7】
workers.add(w);
workerAdded = true;
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
}
} finally {
//【1.8】
mainLock.unlock();
}
if (workerAdded) {
//【1.9】
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
//【1.10】
addWorkerFailed(w);
}
return workerStarted;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}代码分析:
【1】如果当前工作的线程数是否少于核心线程数:workerCountOf(c) < corePoolSize
重新获取ReentrantLock的可重入锁,并加锁
workers移除工作对象
ReentrantLock解锁
第一个if判断:检查当前工作的线程数是否已达到核心或最大线程数。
第二个if判断:如果未达到,则尝试原子增加工作线程计数,若增加成功,则退出循环:break retry;
第三个if判断:如果线程池状态是>=SHUTDOWN,STOP,TIDYING,TERMINATED,线程池处于关闭或更高状态,则继续重试:continue retry;
说明:线程池都要关门了,那肯定不能继续接受新任务执行了。
【1.1】开始添加核心线程:addWorker
【1.2】添加失败:如果(线程池状态是>=SHUTDOWN,STOP,TIDYING,TERMINATED)并且(如果线程池状态是>=STOP,TIDYING,TERMINATED,workQueue任务队列为空,firstTask不为空),返回false。
【1.3】
【1.4】新建workers工作队列对象:new Worker(firstTask),包含了任务task
【1.5】获取ReentrantLock的可重入锁,并加锁
【1.6】线程池还在运行状态RUNNING,或者,线程池状态<STOP(即RUNNING、SHUTDOWN)
【1.7】新建好的Worker,放入工作队列workers
【1.8】ReentrantLock的可重入锁,解锁
【1.9】触发workers工作队列对象的线程执行:t.start()
【1.10】finally兜底处理逻辑,如果上述流程有异常,最终执行:addWorkerFailed
【2】如果当前工作的线程数大于核心线程数:workerCountOf(c) >= corePoolSize
线程池状态非工作状态:线程池状态>=SHUTDOWN,则移除任务并拒绝执行任务策略
线程池状态是工作状态:若无工作线程,则创建。
线程池状态=RUNNING,任务加入等待队列workQueue,并进行线程池状态复查
【3】若无法将任务加入队列且未能成功添加新线程来处理任务,则拒绝该任务。
梳理得到下面的流程图:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









