







DQL
目录

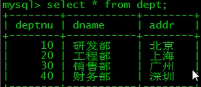
简单查询
select * from employee;
select empno,ename,job as ename_job from employee;

精确条件查询
select * from employee where ename='后裔';
select * from employee where sal != 50000;
select * from employee where sal <> 50000; 不等于
select * from employee where sal > 10000;
模糊查询
show variables like '%aracter%';
select * from employee where ename like '林%';
范围查询
select * from employee where sal between 10000 and 30000;
select * from employee where hiredate between '2011-01-01' and '2017-12-1';
离散查询
select * from employee where ename in ('猴子','林俊杰','小红','小胡');
消除重复值
select distinct(job) from employee;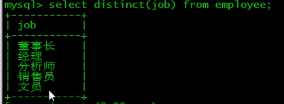
统计查询
count(code)或者count(*)
select count(*) from employee;
select count(ename) from employee; 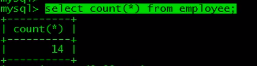

sum() 计算总和
select sum(sal) from employee;
max() 计算最大值
select * from employee where sal= (select max(sal) from employee);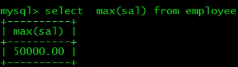

avg() 计算平均值
select avg(sal) from employee;
min() 计算最低值
select * from employee where sal= (select min(sal) from employee);
concat函数: 起到连接作用
select concat(ename,' 是 ',job) as aaaa from employee;
分组查询 group by
作用:把行 按 字段 分组
语法:group by 列1,列2....列N
适用场合:常用于统计场合,一般和聚合函数连用
select deptnu,count(*) from employee group by deptnu;
select deptnu,job,count(*) from employee group by deptnu,job;
select job,count(*) from employee group by job;

筛选 having条件查询
作用:对查询的结果进行筛选操作
语法:having 条件 或者 having 聚合函数 条件
适用场合:一般跟在group by之后
select job,count(*) from employee group by job having job ='文员';
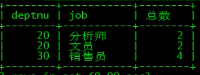
select deptnu,job,count(*) from employee group by deptnu,job having count(*)>=2;
select deptnu,job,count(*) as 总数 from employee group by deptnu,job having 总数>=2;

排序 order by排序查询
作用:对查询的结果进行排序操作
语法:order by 字段1,字段2 .....
适用场合:一般用在查询结果的排序
asc顺序
desc逆序
select * from employee order by sal;
select * from employee order by hiredate;
select deptnu,job,count(*) as 总数 from employee group by deptnu,job having 总数>=2
order by deptnu desc;
select deptnu,job,count(*) as 总数 from employee group by deptnu,job having 总数>=2
order by deptnu asc;
select deptnu,job,count(*) as 总数 from employee group by deptnu,job having 总数>=2
order by deptnu;
顺序:where ---- group by ----- having ------ order by
Limit 限制查询
作用:对查询结果起到限制条数的作用
语法:limit n,m n:代表起始条数值,不写默认为0;m代表:取出的条数
适用场合:数据量过多时,可以起到限制作用
select * from XD.employee limit 5,5;


exists型子查询
exists型子查询后面是一个受限的select查询语句
exists子查询,如果exists后的内层查询能查出数据,则返回 TRUE 表示存在;为空则返回 FLASE则不存在。
分为俩种:exists跟 not exists
select 1 from employee where 1=1;
select * from 表名 a where exists (select 1 from 表名2 where 条件);
![]()
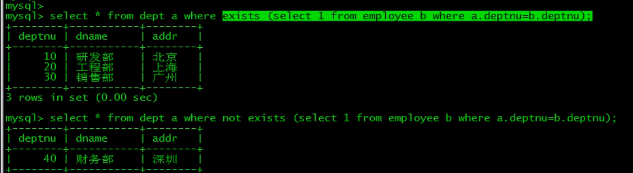
eg:查询出公司有员工的部门的详细信息
select * from dept a where exists (select 1 from employee b where a.deptnu=b.deptnu);
select * from dept a where not exists (select 1 from employee b where a.deptnu=b.deptnu);
(1代表*)
查出没有员工的部门



左连接查询与右连接查询
左连接称之为左外连接 右连接称之为右外连接 这俩个连接都是属于外连接
左连接关键字:left join 表名 on 条件 (简写) / left outer join 表名 on 条件
右连接关键字:right join 表名 on 条件 (简写)/ right outer join 表名 on 条件
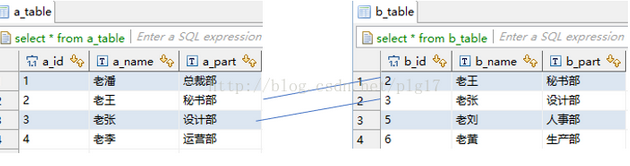
左连接说明: left join 是left outer join 的简写,左(外)连接,左表(a_table)的记录将会全部表示出来, 而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
右连接说明:right join是right outer join的简写,与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
列出部门名称和这些部门的员工信息,同时列出那些没有的员工的部门(没有员工 的部门信息用null填充)
dept,employee
select a.dname,b.* from dept a left join employee b on a.deptnu=b.deptnu;
select b.dname,a.* from employee a right join dept b on b.deptnu=a.deptnu;
select a.dname,a.address ,b.* from dept a left join employee b on a.deptnu=b.deptnu;


左外
左边的a全部显示 右边的吧只显示符合条件的

内连接:获取两个表中字段匹配关系的记录
主要语法:INNER JOIN 表名 ON 条件;
想查出员工张飞的所在部门的地址
select a.addr from dept a inner join employee b on a.deptnu=b.deptnu and b.ename='张飞';
select a.addr from dept a,employee b where a.deptnu=b.deptnu and b.ename='张飞';(另一种形式)
左连接左边的内容都查出来,右边的and b.ename='张飞' 就没用了
联合查询:就是把多个查询语句的查询结果结合在一起
主要语法1:... UNION ... (去除重复)
主要语法2:... UNION ALL ...(不去重复)
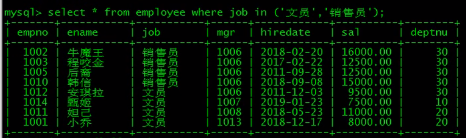
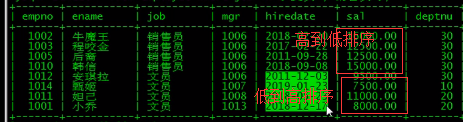
加上条件就好了


![]()
将查询的结果创建一个新的表;
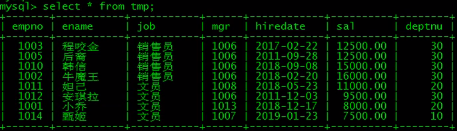
union查询的注意事项:
(1)两个select语句的查询结果的“字段数”必须一致;


(2)通常,也应该让两个查询语句的字段类型具有一致性;
(3)也可以联合更多的查询结果;
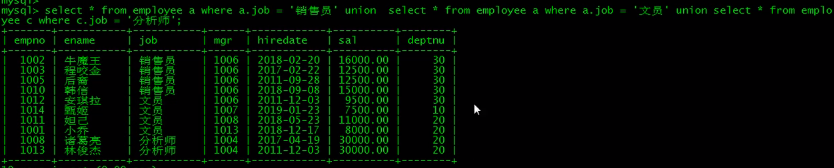
(4)用到order by排序时,需要加上limit(加上最大条数就行),需要对子句用括号括起来
eg:对销售员的工资从低到高排序,而文员的工资从高到低排序
(select * from employee a where a.job = '销售员' order by a.sal limit 999999 )
union (select * from employee b where b.job = '文员' order by b.sal desc limit 999999);
左右连接练习题:
根据给出的表结构按要求写出SQL语句。t 表(即Team表)和 m 表(即Match表) 的结构如下:
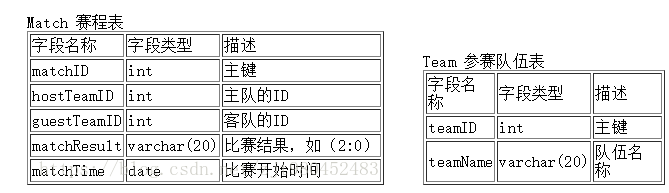
t 表(即Team表)和 m 表(即Match表) 的内容如下:

t 表和 m 表下载地址
m 表(即Match表) 的 hostTeamID 与 guestTeamID 都与 t 表(即Team表) 中的 teamID 关联。请查出 2006-6-1 到2006-7-1之间举行的所有比赛,并且用以下形式列出: 拜仁 2:0 不来梅 2006-6-21
===============================================================================
解决方案:
第一步:先以 m 表左连接 t 表,查出 m 表中 hid 这列对应的比赛信息:
SELECT m.mid,t.tname,m.mres,m.matime as time FROM m LEFT JOIN t ON t.tid = m.hid;
查询结果记为结果集 t1 ,t1 表如下:

第二步:先以 m 表左连接 t 表,查出 m 表中 gid 这列对应的比赛信息:
SELECT m.mid,t.tname,m.mres,m.matime FROM m LEFT JOIN t ON t.tid = m.gid;
查询结果记为结果集 t2 ,t2 表如下:

第三步:以结果集 t1 为基础左连接查询结果集 t2,查询条件为两者比赛序号(mid)相同。
SELECT t1.tname,t1.mres,t2.tname,t1.time FROM
(SELECT m.mid,t.tname,m.mres,m.matime as time FROM m LEFT JOIN t ON t.tid = m.hid)
as t1
LEFT JOIN
(SELECT m.mid,t.tname,m.mres,m.matime as time FROM m LEFT JOIN t ON t.tid = m.gid)
as t2
ON t1.mid = t2.mid WHERE t1.time BETWEEN '2006-06-01' AND '2006-07-01';
查询结果如下:

全连接练习题:
A表和B表结构如下,请将两表合并:


合并要求:A表中a:5,B表中a:5,因此合并后表中a对应的值为10;要求查出的结果样本如下:
采用 union all 全连接,然后使用from 子查询:
SELECT id,SUM(num) as num FROM ((SELECT id,num FROM a) UNION ALL(SELECT id,num FROM b)) as tb GROUP BY id;

















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











