







中文译名:hawkeye: 需求导向的灰盒模糊测试
作者:Hongxu Chen
单位:南洋理工大学
国家: #新加坡
年份: #2018年
来源: #ccs
关键字: #定向fuzzing #fuzzing #灰盒
代码地址: https://github.com/hongxuchen/Hawkeye
介绍网站:Hawkeye (google.com)
笔记建立时间: 2023-02-28 09:30
摘要
目的:提高灰盒模糊器的指向性
方法:静态分析收集信息(调用图、函数和基本块级别的目标距离);基于静态信息和执行跟踪评估执行的种子,生成动态指标,用于种子优先级、能量分配和自适应变异
创新:新颖的静态分析、动态指标生成
效果:相比于 AFL 和 AFLGo 等最先进的灰盒模糊测试器,Hawkeye 可以更快地到达目标站点并重现崩溃。特别是,Hawkeye 可以将暴露某些漏洞的时间从约 3.5 小时缩短至 0.5 小时。
1引言
在静态分析提取信息后,动态分析中有几个挑战——如何动态调整不同策略,以便尽快到达目标站点。第一个挑战是如何正确分配能量给不同距离的输入,以及如何优先考虑离目标更近的输入。这推导出第三个期望属性P3。第二个挑战是如何适应性地改变变异策略,因为GFs可能在粗粒度(例如批量删除)和细粒度(例如按位翻转)两个层次上拥有各种变异操作符。这推导出第四个期望属性P4。因此,第二个问题是对DGF中使用的动态策略进行适当调整。
- 背景:
- 在一些测试场景下需要定向 fuzzing
- 漏洞重现
- 在一个平台上发现了漏洞,那么在其他类似平台是否有相似漏洞
- 测试补丁
- 漏洞重现
- 最先进(2018 年前)的定向灰盒 fuzzer 是 AFLGO
- AFLGo 将到达目标站点的可达性视为一种优化问题,并采用元启发式方法来促进具有更短距离的测试种子。这里,距离是根据输入种子的执行跟踪中到目标基本块的平均基本块权重计算的,其中权重由程序的调用图和控制流图中的边决定,元启发式方法为模拟退火。
- 挑战:
- 拥有一个合适的静态分析来收集 DGF 所需信息。
- 如何有效的计算到 target sites 的有效距离而不损害有些期望特征,特别地,它应该有助于保留种子多样性
- AFLGO 优先分配能量给距离 target sites 最短的种子,但是这样反而会导致饿死那些更快触发漏洞的种子。(因为计算方法的问题,可能算出来的最短距离并不是直观上的最短距离)(这个貌似在 MC2 中有提及,等我去翻翻)
- LibFuzzer 认为不考虑所有的路径可能会漏掉隐藏在较长路径深处的错误
- 如何减小静态分析的开销
- 如何有效的计算到 target sites 的有效距离而不损害有些期望特征,特别地,它应该有助于保留种子多样性
- 对 DGF 中使用的动态策略进行适当调整
- 如何分配能量
- 如何适应性(动态)的调整变异策略
- 拥有一个合适的静态分析来收集 DGF 所需信息。
- 在一些测试场景下需要定向 fuzzing
- 目的:
- 基于以上的挑战,作者总结了 DGF 应该有的四个属性(摘要里提到的那个 feature)
- P1 DGF 应该具有一个基于距离的强大机制,能够通过考虑所有到目标的轨迹并避免对某些轨迹的偏见来指导定向模糊测试。
- P2 DGF 应该在静态分析中平衡开销和效用。
- P3 DGF 应该优先安排种子以快速到达目标站点。
- P4 当种子覆盖不同程序状态时,DGF 应采用自适应变异策略。
- 基于以上的挑战,作者总结了 DGF 应该有的四个属性(摘要里提到的那个 feature)
- 方法:
- 对于 P1,使用基于增强的相邻函数距离来计算函数级距离和基本块距离,同时在模糊测试中将静态分析结果和运行时执行信息结合,计算执行轨迹和 target sites 基本块轨迹距离和覆盖函数相似度。(说白了就是动静结合)
- 对于 P2,应用基于调用图(CG)和控制流图(CFG)的分析,即函数级可达性分析、函数指针(间接调用)的指向分析和基本块度量(§4.1)。(这怎么平衡开销?)
- 对于 P3,我们建议将基本块轨迹距离和覆盖函数相似度结合起来解决功率调度问题(§4.4)和种子优先级问题(§4.6)。
- 对于 P4,我们建议根据可达性分析和覆盖函数相似度应用自适应变异策略(§4.5)。
- 创新:
- 增强的相邻函数距离
- 基本块轨迹距离和覆盖函数相似度相结合指导能量调度
- 可达性分析和覆盖函数相似度指导变异策略
- 效果:
2期望的 DGF 特性
2.1Motivating Example
作者举了一个例子来展示最短路径的弊端:

如图所示,这个错误是在 GNU binutils 中的 nm 中触发的,崩溃函数是 T,图二展示了触发漏洞的路径要长于其他路径,所以该漏洞对于一般的灰盒模糊很难发现。在我们进行的 10 次不同运行中,AFL [48]都无法在 24 小时内检测到这个漏洞。
- 现有 DGF 的挑战根源于以下几个方面:
- 1)目标函数可能出现在 PUT 的多个位置,多条不同的轨迹可能通向目标。
- 2)由于调用图主要影响轨迹距离(与目标站点的不相似性)的计算,因此需要准确建立;特别是,函数之间的间接调用不应被忽略。
2.2 定向模糊的期望性质
- P1:DGF 应定义一种强大的基于距离的机制,可以通过避免对某些路径的偏见并考虑所有路径到目标来指导有向模糊测试。
- 指导机制可以提供所有可能通往目标的路径的知识,并通过逐渐减少距离来引导突变朝着它。并且所有路径到达目标的距离都应正确计算,以便与其他路径相比分配更多能量给所有可达到目标的路径。
- 重点在于距离的正确(有效)计算
- P2:DGF 应在静态分析中平衡开销和效用。
- 对于难以分析的信息(C/C++程序中的间接函数调用无法直接从源代码或二进制指令观察 call site),权衡分析的开销和效用
- 并非所有调用关系都应被平等对待。某些函数在其调用函数中出现多次,那么对于出现频率小的函数而言,该类函数应该离其调用函数“更近”
- 然而,在静态短语中建模实际分支条件是不切实际的,因为静态分析固有的局限性。例如,对于一个非平凡的代码段,在运行时很难预测谓词的真分支是否比其假分支执行得更频繁。另一方面,在灰盒模糊测试设置中动态跟踪符号条件将太耗时。
- P3:DGF 应选择并安排种子以快速到达目标站点。
- 在有向模糊测试中,模糊测试的目标不是尽快达到覆盖率的上限,而是尽快到达特定目标。所以能量调度和种子优先级都应该以尽快达到 target sites 为标准
- 它们都可以通过基于距离的机制来指导
- P4:当种子覆盖不同的程序状态时,DGF 应采用自适应突变策略。
- 通常,突变器可以分为两个级别:细粒度突变(例如位翻转)和粗粒度突变(例如块替换)。尽管没有直接证据表明细粒度突变很可能保留执行跟踪,但人们普遍认为粗粒度随机突变很可能大大改变执行跟踪。
- 因此,期望的设计是当一个种子已经到达目标站点(包括目标行、基本块或函数)时,它应该给予较少的粗粒度突变机会。(意思就是当种子已经达到 target site,就让它细粒度突变,就是变化不要那么大,这样就更可能突变到另一条可以到达 target site 的路径)
2.3 AFLGO 的解决方法
- 对于 P1。对于图 2,基于 AFLGo 定义的距离公式,分配给图 2的能量将是⟨a, e, T, Z⟩>⟨a, e, f, Z⟩>⟨a, b, c, d, T, Z⟩。这是有问题的:正常轨迹⟨a, e, T, Z⟩被过分强调;崩溃轨迹⟨a, b, c, d, T, Z⟩却被认为是最不重要的,甚至比未达到目标 T 的轨迹⟨a, e, f, Z⟩还要不重要。
- P2。AFLGo 只考虑显式调用图信息。这将会忽略函数指针的调用,任何通过函数指针进行调用的函数在 AFLGO 看来都是不可达。所以 AFLGO 静态分析得到的信息是不完整的。
- 此外作者指出 AFLGO 调用方和被调用方的距离的计算方式比较简单,忽略了不同的调用方式和调用次数。
- (这几个缺点不都是针对 P1 的吗,怎么就挪到 P2 了)
- P3。AFLGO 采用模拟退火的算法,倾向于给更接近目标的种子更多的能量,同时也有措施来促进更好的变异(这里要回看一下 aflgo,有点忘了)
- P4。AFLGo 的突变算子来自于 AFL 的两种非确定性策略:1) havoc,即纯粹随机的突变,如位翻转、块替换等; 2) splice,它从两个现有种子的一些随机字节部分生成种子。这种非确定性策略太随意,可能会破坏或忽略更好的种子。AFLGo 缺乏自适应突变策略。
- 总结。以 AFLGo 为例,我们可以总结以下几点改进 dgf 的建议:
- (1) 对于 P1,需要更准确的距离定义,以保留迹的多样性,避免对短迹的关注。
- (2) 对于 P2,直接调用和间接调用都需要分析; 在静态距离计算过程中,需要区分不同的呼叫模式。
- (3) 对于 P3,需要对当前的功率调度进行调节。距离引导的种子优先级也是必要的。
- (4) 对于 P4, DGF 需要一种自适应突变策略,当种子与目标距离不同时,最优地应用细粒和粗粒突变。
3 方法概述

3.1 静态分析
- 输入为程序源码和 target sites(以所在基本块和函数的形式)
- 静态分析阶段输出带有基本块级距离信息的程序二进制文件
- 包含式指针分析精确构建仪表化目标程序的调用图,对于每个函数构建控制流图
- 根据 CG 和 CFG 计算几个实用程序,用于促进 Hawkeye 中的定向性,实用程序如下:
- (1)函数级距离是基于 CG 计算增强的相邻函数距离(§4.2)。这个距离被用来计算基本块级别的距离。它也在模糊循环中用于计算覆盖函数相似度(§4.4)。
- (2)基本块级别的距离是根据函数级别的距离、CG 和函数的 CFGs 计算出来的。这个距离被静态地仪表化,用于每个被认为能够到达目标站点之一的基本块。在模糊循环中,它也被用来计算基本块追踪距离(§4.4)。
- (3)目标函数追踪闭包是根据 CG 为每个目标站点计算出来的,以获得能够到达目标站点的函数。它在模糊循环中用于计算覆盖函数相似度(§4.4)。
- 最后将基本块级别的距离仪表化源代码,重新编译,得到用于模糊的二进制程序
3.2 模糊循环
-
模糊器从优先级种子队列中选择一个种子,利用能量分配函数进行能量调度
- 能量分配函数是覆盖函数相似性和基本块跟踪距离的组合,对于每个在变异过程中新生成的测试种子,在捕获其执行跟踪后,模糊器将根据实用程序(§3.1)计算覆盖函数相似性和基本块跟踪距离。
- 对于每个输入执行跟踪,其基本块跟踪距离计算为累积基本块级别距离除以执行基本块总数;其覆盖函数相似性根据当前执行函数与目标函数跟踪闭包的重叠以及函数级别距离计算。
- 能量分配函数是覆盖函数相似性和基本块跟踪距离的组合,对于每个在变异过程中新生成的测试种子,在捕获其执行跟踪后,模糊器将根据实用程序(§3.1)计算覆盖函数相似性和基本块跟踪距离。
-
在能量确定后,模糊器根据变异器对种子的粒度自适应地分配两种不同类别的变异预算(§4.5)。然后,模糊器评估新生成的种子,优先考虑那些具有更多能量或已达到目标函数的种子(§4.6)。
4方法
4.1 图的构建
- 对整个程序的函数指针应用基于包含的指针分析来生成 CG
- 目的:识别程序的间接调用
- 方法:这种算法的核心思想是将输入程序中形如 p := q 的语句转换为形如“q 的 points-to 集合是 p 的 points-to 集合的子集”的约束。计算了整个程序内函数指针的 points-to 集合,从而得到一个包含所有可能直接和间接调用的相对精确调用图。(这种方法是上下文不敏感和流不敏感的)
- 调用图用户计算函数级距离
- 基于 LLVM 的 IR 生成每个函数的 CFG
- CG 计算函数级距离
- CFG+CG 计算基本块距离
4.2 增强的相邻函数距离
作者认为在计算距离的时候应该考虑被调函数的调用模式(概率),概率越大,距离应当越近。如下图所示,a 中的 fb 肯定会被调用,而 b 中的 fb 和 fc 的调用概率相同。所以 a 中 fa 到 fb 的距离要近于 fc,b 中 fa 到 fb 和 fc 的距离相同。

作者提出两个指标来增强直接调用的距离
- Φ ( C N ) = ϕ ∗ C N + 1 ϕ ∗ C N \Phi(C_N)=\frac{\phi*C_N+1}{\phi*C_N} Φ(CN)=ϕ∗CNϕ∗CN+1 C N C_N CN 是某个被调用函数的调用点出现次数,次数越大距离越小( Φ ( C N ) \Phi(C_N) Φ(CN) 用来表示这种效应),其中φ是一个常数值(通常φ= 2)
- Ψ ( C B ) = ψ ∗ C B + 1 ψ ∗ C B \Psi (C_B)=\frac{\psi*C_B+1}{\psi*C_B} Ψ(CB)=ψ∗CBψ∗CB+1 C B C_B CB 是调用函数包含至少一个调用点的基本块的数量,当拥有调用点的分支越多,包括被调函数的执行跟踪也越多 ( Ψ ( C B ) \Psi(C_B) Ψ(CB) 来表示这种效应),ψ是一个常数值(通常ψ= 2)。
- 这两个因子都是单调递减函数,随着 C B 、 C N C_B、C_N CB、CN 增大逐渐收敛到 1
- 给定一个直接函数调用对(f1,f2),其中 f1 是调用者,f2 是被调用者,则 f1 和 f2 之间的原始距离为 1,首先计算因子 Φ 和 Ψ \Phi 和\Psi Φ和Ψ,然后相乘得到我们的调整因子,调整因子乘上 AFL 计算的距离就是最终结果 d ′ f ( f 1 , f 2 ) = Ψ ( f 1 , f 2 ) ⋅ Φ ( f 1 , f 2 ) ( 1 ) {d}' f (f1, f2) = Ψ(f1, f2) · Φ(f1, f2) (1) d′f(f1,f2)=Ψ(f1,f2)⋅Φ(f1,f2)(1)
4.3 指向性效用计算
函数级距离
给定一个函数 n,它到目标函数集合
T
f
T_f
Tf 的距离为:

R
(
n
,
T
f
)
=
{
t
f
∣
r
e
a
c
h
a
b
l
e
(
n
,
t
f
)
}
R(n,T_f)=\{t_f|reachable(n,t_f)\}
R(n,Tf)={tf∣reachable(n,tf)},表示在 CG 中 n 能到达的 tf 的集合,并且 df 是基于增强距离的迪杰特斯拉最短路径
基本块级距离
给定一个基本块 m,它到目标基本块 Tb 的距离定义为:
- 如果基本块 m 属于目标基本块 Tb,距离为零
- 如果基本块 m 属于 Transb,距离为属于
C
f
T
(
m
)
C_f^T(m)
CfT(m) 的函数到目标函数的最小值与 c 的乘积
- 在基本块 m 内调用的函数集合表示为 Cf (m), C f T ( m ) = { n ∣ R ( n , T f ) ≠ ∅ , n ∈ C f ( m ) } C_f^T(m)=\{n|R(n, Tf)\ne∅,n∈C_f(m)\} CfT(m)={n∣R(n,Tf)=∅,n∈Cf(m)}, C f T ( m ) C_f^T(m) CfT(m) 是基本块 m 中的可达目标函数的函数的集合
- T r a n s b = { m ∣ ∃ G ( n ) , m ∈ G ( n ) , n ∈ F , C f T ( m ) ≠ ∅ } Trans_b=\{m|∃G(n),m∈G(n),n∈F,C_f^T(m)\ne∅\} Transb={m∣∃G(n),m∈G(n),n∈F,CfT(m)=∅} Transb 和 CTf 互为“倒数”吧,Transb 表示含有可达目标函数的函数的基本块的集合
- 否则距离需要通过一个中间基本块 t 来间接到达
- d b o ( m 1 , m 2 ) d_{b}^{o}(m1,m2) dbo(m1,m2) 定义为在 CFG G (n) 中从 m1 到 m2 的最小边数
请注意,方程 2 和 3 本身与 AFLGo [6]中的相同。区别在于 df 的计算是增强的。
目标函数跟踪闭合
实用程序ξf(Tf)表示目标函数 Tf 的所有前任,由于静态分析的局限性,我们选择不排除那些被认为无法从入口函数到达的前任。
4.4 能量调度
基本块跟踪距离
种子 s 到目标基本块 Tb 的距离定义为: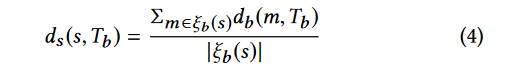
其中ξb (s) 是种子 s 的执行跟踪,包含所有执行的基本块。
方程 4 的基本思想是:对于 s 的执行跟踪中的所有基本块,我们计算到目标基本块 Tb 的平均基本块级距离。请注意,方程 4 也与 AFLGo [6]中的相同。
然后应用特征缩放归一化来获得最终距离: ,其中 minD(或 maxD)是曾经遇到的最小(或最大)距离。
,其中 minD(或 maxD)是曾经遇到的最小(或最大)距离。
覆盖函数相似度。
度量衡量种子的执行跟踪与目标执行跟踪在函数级别上的相似性。
我们不跟踪基本块级别的跟踪相似性,因为这会引入相当大的开销。
根据直觉计算相似性,即覆盖“预期跟踪”中更多函数的种子将有更多机会被突变以到达目标。通过跟踪当前种子覆盖的函数集(记为ξf (s))并将其与目标函数跟踪闭包ξf (Tf) 进行比较来计算此相似性。在图 2 中,ξf (abcdTZ)={a, b, c, d, T},ξf (aeTZ)={a, e, T}和ξf (aefZ)={a, e}。
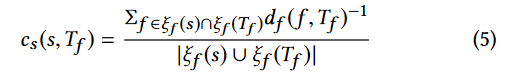
df (f , Tf ) 是使用方程 2 计算的函数级距离。与 ds 类似,也应用了特征缩放归一化,并且最终相似度表示为 cs 。请注意,这种相似度度量是我们方法中独特提出的。
调度
调度处理的问题是给定种子将被分配多少变异机会。
如果当前种子的执行轨迹和达到目标点的任何轨迹越相似,则会被分配到的能量越多。
但是,纯粹基于跟踪距离的调度可能会偏爱某些跟踪模式。对于 AFLGo,如§2.2.2 所述,较短路径将被分配更多能量,这可能会使仍然可到达目标站点的较长路径饥饿。
为了缓解这种情况,作者提出了一种考虑了跟踪距离(基于基本块级别距离)和跟踪相似性(基于覆盖函数相似性)的幂函数:
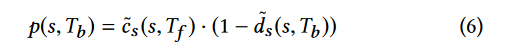
与 AFLGO 的方法相比,该函数平衡了可以到达目标的较短路径和较长路径的影响
- ds 由 CG 和 CFG 计算,但是主要受 CG 影响,因为有放大洗漱 c;cs 仅由 CG 计算
- ds 不惩罚不会导致目标的跟踪,而 cs 通过 ξf (s)(通过跟踪函数级别跟踪)和 ξf (Tf ) 的并集来惩罚它们
- 给定多个可以到达目标的跟踪,ds 偏爱长度短的那些,但 cs 偏爱预期跟踪中公共函数长度较长的那些。
作者指出该函数也存在偏向某些路径的问题,该函数会对与到达目标函数的执行轨迹更相似的种子,即使无法到达目标函数,分配更多能量,但是作者认为这不是问题,因为此类种子即使不会到达目标,但是更容易变异为可以到达目标函数的种子。
4.5 适应性突变
上一节计算得到的能量(也称为应用突变的次数)将会作为变异策略的输入。但是每种类型的突变器的突变次数分配仍是问题(两种类型突变器,粗粒度和细粒度)
-
对于粗粒度:
- 混合变异:以下操作的组合
- 删除一块字节,用缓冲区中其他字节覆盖给定块
- 删除某些行
- 多次复制某些行
- 语义突变:当目标程序已知处理语义相关输入文件(如 javascript、xml、css 等)时使用。其中包括三种元突变,在随机 AST 位置插入另一个子树、删除给定 AST 和用另一个 AST 替换给定位置。
- 拼接:队列中两个种子的交叉和后续的混合变异

- 混合变异:以下操作的组合
算法大意是判断函数是否可以到达目标函数,如果不能,则粗粒度变异的比重要大一点,如果可以细粒度变异的比重大一点。不过无论是否可以到达目标函数,种子都需要进行粗细粒度的变异。Getscore 函数就是方程 6

算法 2 描述了粗粒度变异的算法,给定种子 s 和变异迭代次数 i,对种子进行混合变异和拼接,在必要的情况下进行语义突变,并且降低另外两种编译的比例。作者给出了进行语义突变的条件:
- 检测到输入文件是语义相关的输入文件,如 javascript、xml、css 等
- 先前的语义变异没有失败
在实践中,常数分配经验值:γ = 0.1,δ = 0.4,σ = 0.2,ζ = 0.8。
(对于细粒度的变异,作者采用了一般的方法)
4.6 种子优先级
作者认为因为静态分析的局限性,种子的优先等级可能会有偏差,并且队列的插入算法代价昂贵,实践中并不实用。因此作者建立了三个队列,优先级依次降低,队列中没有优先级。

- 当新种子可以覆盖新的轨迹或者与目标种子具有更大的相似性值(即功率函数值)或者可以到达目标函数式,放到第一队列,具有最高优先级
- 否则新种子放到第二队列
- 不是新种子的种子放到第三队列
- 在实践中,Hawkeye 还应用 AFL 的循环桶方法(见[49])来过滤掉大量在循环迭代方面不带来新覆盖率的“等效”种子。
5 评估
- 静态检测基于 AFL 的 LLVM 模式
- 指针分析基于 SVF 的过程间静态值流分析工具
- 动态模糊器基于我们的 Rust 实现的 AFL。基础框架,称为 Fuzzing Orchestration Toolkit
- Hawkeye 的检测包括三个部分:1)跟踪执行轨迹的基本块 ID 2)确定基本块轨迹距离的基本块距离信息 3)跟踪已覆盖函数的函数 ID。
5.1 评估设置
静态分析真的值得付出努力吗?
鹰眼在重现目标崩溃方面的表现有多好?
在 Hawkeye 中动态策略的效果如何?
鹰眼到达特定目标地点的能力如何?
数据集
(1) GNU Binutils[5]是 GNU/Linux 平台上使用的二进制分析工具的集合。该基准测试也用于其他一些作品,如[6, 7, 24]。
(2) MJS[39]是一个用于 C/ c++的嵌入式 JavaScript 引擎,用于物联网开发。由于 AFLGo 在实现上的局限性,它被用来直接比较 Hawkeye 和 AFLGo。
(3) Oniguruma[23]是一个通用的正则表达式库,被多个世界著名的项目使用,如 PHP[33]。
(4) Fuzzer Test Suite[18]是一套用于模糊引擎的基准测试。它包含了几个具有代表性的实际项目。
评估工具
(1) AFL 是目前最先进的 GF。它忽略 PUT 的所有目标信息,只执行“基本块转换”插装。
(2) AFLGo 是基于 AFL 的最先进的 DGF。与 AFL 相比,它还能显示基本的块距信息。
(3) HE-Go 是我们的静态分析程序生成基本块级距离的模糊器 (图 3),但动态模糊是由 AFLGo 进行的。
5.2 静态分析统计

- Size 表示程序 LLVM bitcode 形式的大小
- Ics 表示二进制文件中间接调用 call sites 的数量,通过计算没有明确已知被调用者的调用站点来计算
- Cs 表示 call sites 的数量
- ics/cs 表示所有调用站点中间接调用的百分比
- 最后一列表示生成调用图所需的时间,这占据了大部分时间。
从表中可以看出,间接调用的占比还是相对比较大的,所以建立精确的调用图还是很有必要的
CN > 1 和 CB > 1 出现次数也很多,这显示了考虑不同模式呼叫关系的重要性
5.3 崩溃暴露能力
在这个实验中,我们直接比较了Hawkeye与其他模糊器在一些已知崩溃上的崩溃暴露能力。
针对 Binutils 的崩溃再现。
起初,我们打算在实验中直接将 GNU Binutils 与 AFLGo 进行比较,因为它是[6]中证明 AFLGo 定向性的重要基准。然而,我们发现 AFLGo 在生成静态距离方面存在一些问题[2]。最重要的是,计算距离需要太长时间。结果,在我们对 GNU Binutils 2.26 进行 AFLGo 静态分析时,它未能在 12 小时内生成包含仪器距离信息的“distance. cfg. txt”5。尽管 AFLGo 仍然可以在没有距离信息仪器的情况下进行模糊测试,但如果没有任何距离输入,模糊测试过程就不再是定向的。因此,我们收回了[6]中关于 GNU Binutils 基准测试 6 的结果与我们的比较。我们完全按照[6]中的评估设置进行每个实验 20 次,时间预算设为 8 小时;初始输入种子文件只包含一个换行符(由 echo “” > in/file 生成)。我们指定的目标站点基于它们的 CVE 描述和崩溃的回溯。我们将 Hawkeye 与 AFLGo 和 AFL 进行比较;结果如表 2 所示。在 AFLGo 论文中,使用了 A12 度量[42]来显示根据所有运行情况一个模糊器优于另一个模糊器的可能性。由于我们无法获得他们实验中每次运行的结果,在表 2 中忽略了这一点。(懒得总结,直接翻译)

(在实验中,TTE 通常指的是“时间到事件”(Time-To-Event),它表示从实验开始到某个特定事件发生所经过的时间。在模糊测试中,TTE 可以指从模糊测试开始到发现崩溃所经过的时间。μTTE 是“平均时间到事件”(Mean Time-To-Event)的缩写,它表示在多次实验中,从实验开始到某个特定事件发生所经过的平均时间。在模糊测试中,μTTE 可以指从模糊测试开始到发现崩溃所经过的平均时间。)
Run 是命中漏洞的轮数
针对 MJS 的崩溃重现
为了直接比较Hawkeye和AFLGo的性能,我们选择了一个名为MJS的项目,它包含一个源文件,结果在表3中。我们使用这个项目与AFLGo进行直接比较,因为AFLGo花费太多时间或无法为其他项目(如Oniguruma、libpng等)生成距离信息。在MJS上,AFLGo平均花费13分钟生成不同目标的基本块距离。在实验过程中,初始输入种子文件都来自项目的测试目录。目标是从项目的GitHub页面报告的崩溃中选择的,它们对应四类漏洞,分别是整数溢出(#1)、无效读取(#2)、堆缓冲区溢出(#3)和使用后释放(#4)。我们可以观察到以下事实:1)在#1和#2上,Hawkeye取得了最好的结果,在两种情况下都有最多的命中轮数和最短的μTTE。就命中轮数而言,Hawkeye在5次运行中发现了#1的错误,在7次运行中发现了#2的错误,而对于另外两个工具,它们只在2次运行中检测到两次崩溃。值得注意的是,这种情况并非易事,并且Hawkeye将μTTE从约3.5小时减少到0.5小时。2)对于所有工具都在8轮内重现崩溃的#3来说,Hawkeye仍然在μTTE方面取得了极大改进,并且使用不到其他工具四分之一μTTE。3)对于所有工具都在所有轮次内重现崩溃并且它们之间μTTE差异不显著的#4来说。至于A12,我们可以看到Hawkeye表现出非常好的结果,例如,在#2中值都是0.95 ,这意味着Hawkeye有95% 的把握比其他两个工具表现更好。

(后续基本都是对实验结果的展示,没有什么总结的必要)
5.6 有效性威胁
内部威胁(缺陷):
- 内部算法存在几个预定义的阈值因子,这些因子的值都是经验值,需要进行实验找出最佳配置
- 静态分析依赖的 LLVM 和 SVF 可能会造成影响,或许可以找到更好的工具来集成
外部威胁:
- 实验数据集还是不够丰富
6 相关工作
- SeededFuzz [45] 使用各种程序分析技术来促进初始种子的生成和选择,从而帮助实现有向模糊测试的目标。配备了改进后的种子选择和生成技术,SeededFuzz 可以到达更多关键站点并发现更多漏洞。
- Directed Symbolic Execution (DSE) 是一种与 DGF 相关的技术,它也旨在执行 PUT 的目标站点。已经提出了几项 DSE 工作 [17、19、21、28、29]。这些 DSE 技术依赖于重量级程序分析和约束求解来系统地到达目标站点。
- 但是 DES 技术存在路径爆炸问题
- 污点分析也被广泛用于促进有向白盒测试 [12、16、24、34、44]。在模糊测试中使用污点分析的关键直觉是确定输入的某些部分应该优先变异。这样,模糊测试器可以大大减少到达某些期望位置的搜索空间。
- Fairfuzz [24] 中的罕见分支或 TaintScope [44] 中与校验和相关的代码。
- 但是,目标明确的场景下,如补丁测试和崩溃复现,这些技术没有优势。















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









