






Go学习
- Google支持的开源编程语言。
- go是一种并发、带垃圾回收、快速编译、静态类型、编译型、强类型的语言。
- 主要用途有高并发服务器、区块链、云计算等。
- Go语言简单易学,功能强大,非常适合学习。
基本特性
- 查看go版本
go version,运行go文件go run hello.go; - 语法上,推荐使用驼峰式命名。结尾不要分号,除非一行上有多条语句。变量声明的顺序,不影响执行的。没有类和三元表达式。
- 系统变量设置
GOROOT是go的安装目录,GOPATH是go的外部导入包所在的目录,并且添加到path中; - Go的垃圾回收机制会回收不被使用的内存,但是这不包括操作系统层面的资源,比如打开的文件、网络连接,因此我们必须显式的释放这些资源。
变量和赋值
-
正常赋值
var a int = 1 var b = 1 -
简短变量声明,可用于声明和初始化局部变量, 以
a := 1形式声明变量,变量类型根据表达式来自动推导,如果已经使用:=了,变量第二次使用就是赋值,只能在函数内部使用。a := 1 -
元组赋值允许同时更新多个变量的值。在赋值之前,赋值语句右边的所有表达式将会先进行求值,然后再统一更新左边对应变量的值。
// 交换值 c, d := 2, 3 c, d = d, c fmt.Println(c) fmt.Println(d) -
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明
for a, _ := range(strs) -
注意,如下 b 是 a 的拷贝,地址不一样。
a := [3]int{1, 2, 3} b := a b[0] = 999 -
变量的声明周期
对于在包一级声明的变量来说,它们的生命周期和整个程序的运行周期是一致的。局部变量的生命周期则是动态的,每次从创建一个新变量的声明语句开始,直到该变量不再被引用为止,然后变量的存储空间可能被回收。
那么自动垃圾收集器一个变量是何时可以被回收的呢?从每个包级的变量和每个当前运行函数的每一个局部变量开始,通过指针或引用的访问路径遍历,是否可以找到该变量。
如果不存在这样访问路径那么该变量是不可达的,也就是说它是否存在并不会影响程序后续的计算结果。因为一个变量的有效周期只取决于是否可达,因此一个循环迭代内部的局部变量的生命周期可能超出其局部作用域。
同时,局部变量可能在函数返回之后依然存在。
常量
常量表达式的值在编译期计算,而不是在运行期,每种常量的潜在类型都是基础类型。可以同时声明多个常量。
const A11 = 11
const (
A22 = 22
A33 = 33
)
iota自动生成器,可以按照一定规则重复生成一些数据
type Weekday int
const (
Sunday Weekday = iota // iota常量生成器初始化
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
type Flags uint
const (
FlagUp Flags = 1 << iota // 1
FlagBroadcast // 2
FlagLoopback // 4
FlagPointToPoint // 8
FlagMulticast // 16
)
无类型常量,可以进行超出正常大小的计算,比如ZiB,可以有256bit的运算精度。
只有常量可以是无类型的。当一个无类型的常量被赋值给一个变量的时候,出现在有明确类型的变量声明的右边,无类型的常量将会被隐式转换为对应的类型,如果转换合法的话。
const (
_ = 1 << (10 * iota)
KiB // 1024
MiB // 1048576
GiB // 1073741824
TiB // 1099511627776 (exceeds 1 << 32)
PiB // 1125899906842624
EiB // 1152921504606846976
ZiB // 1180591620717411303424 (exceeds 1 << 64)
YiB // 1208925819614629174706176
)
基础类型
int8、int16、int32、int64和默认的int和uint- 尽管
int是32位的环境,int和int32是不同的数据类型 - 无符号的整数类型
uintptr,没有指定具体的bit大小但是足以容纳指针 - 其中有符号整数采用2的补码形式表示,也就是最高位用来表示符号位。例如,int8类型的值域是
-128到127而uint8类型整数的是0到255 - 取模运算符,只能是整数,小数不行
- 除法
/的结果依赖于操作数是否全为整数,5.0/4.0 = 1.25,5/4 = 1 - 一个算术运算的结果,不管是有符号或者无符号的,如果需要更多的bit位才能正确表示的话,就说明计算结果是溢出了,超出的高位会丢弃。
// byte 和 int8等价的 var i1 int8 = 127 var b1 byte = 123 var i2 int16 = 244 var i3 int32 = 244 var i4 int64 = 244 fmt.Println(i1) fmt.Println(i3) fmt.Println(i2) fmt.Println(i4) var n1 uint8 = 255 fmt.Println(n1) fmt.Println(b1) var n2 int = 333 var n3 uint = 222 fmt.Println(n2) fmt.Println(n3) - 位运算
// & 位运算 AND // | 位运算 OR // ^ 位运算 XOR, 如果是一个数就是取反 // &^ 位清空或者按位置零(AND NOT)x &^ y,就是结果把y的位是1的清掉变成0 // << 左移 // >> 右移 // 最好用无符号运算运算左移和右移 - 使用
uint做遍历会出现死循环,比如var a unit = 11; a >=0; a--,那么a>=永久成立,无符号数往往只有在位运算或其它特殊的运算场景才会使用,就像bit集合、分析二进制文件格式或者是哈希和加密操作等 - 浮点数,一个float32类型可提供大约6个十进制数的精度,而float64则可以提供约15个十进制数的精度,通常应该优先使用float64类型
const e = 2.71828 for x := 0; x < 8; x++ { fmt.Printf("x = %d e^x = %8.3f\n", x, math.Exp(float64(x))) } var z float64 fmt.Println(z, -z, 1/z, -1/z, z/z)//0 -0 +Inf -Inf NaN fmt.Println(math.IsNaN(z/z)) - 复数也支持,暂时忽略,基本用不到
- 布尔值
bool和其它语言一样
条件判断
if 后的条件不用加括号,也可以在中间加变量声明。switch和其它语言基本一致。
if 7%2 == 0 {
fmt.Println("7 is even")
} else {
fmt.Println("7 is odd")
}
if num := 9; num < 0 {
fmt.Println(num, "is negative")
} else if num < 10 {
fmt.Println(num, "has 1 digit")
} else {
fmt.Println(num, "has multiple digits")
}
循环
go语言只有 for 循环关键字。
i := 1
for i <= 3 {
fmt.Println(i)
i = i + 1
}
for j := 7; j <= 9; j++ {
fmt.Println(j)
}
for {
fmt.Println("loop")
break
}
for n := 0; n <= 5; n++ {
if n%2 == 0 {
continue
}
fmt.Println(n)
}
Printf
fmt.Sprintf 方法是把格式化后的字符串返回
// 打印布尔值
fmt.Printf("%t\n", true) //输出结果为 true
// 打印整数
fmt.Printf("%d\n", 123) //输出结果为 123
// 打印二进制
fmt.Printf("%b\n", 33) //输出结果为 100001
// 打印八进制
fmt.Printf("%o\n", 33) //输出结果为 41
// 打印十六进制
fmt.Printf("%x\n", 33) //输出结果为 21
// 打印字符
fmt.Printf("%c\n", 97) //输出结果为a
// 字符串
fmt.Printf("%s\n", "halo") //输出结果为a
// 打印指针
fmt.Printf("%p\n", &a) //输出结果为 0xc000114018
// %v
// %v的方式 = &{david 1}
// %+v的方式 = &{name:david id:1}
// %#v的方式 = &main.student{name:"david", id:1}
字符串
- 字符串是一个不可改变的字节序列,通常认为是用UTF8编码的Unicode码点(rune)序列
- 第i个字节并不一定是字符串的第i个字符,因为对于非ASCII字符的UTF8编码会要两个或多个字节
- 子串切片
s[0:4]索引可省略 - 字符串拼接,就是加号
- 可以比较,是字符串自然编码的顺序
- 因为字符串是不可修改的,所以
s[0] = 'L'是错误的 - Go语言源文件总是用UTF8编码,并且Go语言的文本字符串也以UTF8编码的方式处理
- 原生的字符串面值形式是
...,使用反引号代替双引号。在原生的字符串面值中,没有转义操作。 - Unicode码点对应Go语言中的rune整数类型(译注:rune是int32等价类型),如果一个符文序列表示为一个int32序列,肯定会浪费很多资源,后来UTF8编码是由Go语言之父发明现在已经是Unicode的标准。
- Go语言的range循环在处理字符串的时候,会自动隐式解码UTF8字符串
func demo32() {
s := "halo bang bang"
fmt.Println(len(s)) // "12"
fmt.Println(s[0] == 'h')
// fmt.Println(s[30])
fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
// 字符串s的0-5的子串
fmt.Println(s[0:4])
fmt.Println(s[:4])
fmt.Println(s[5:])
s1 := "你好啊"
fmt.Println(s1[0])
fmt.Println(s + s1)
// 原生的字符串面值中
const GoUsage = `Go is a tool for managing Go source code.
Usage:
go command [arguments]
...`
println(GoUsage)
}
// 判断是否是前缀
func HasPrefix(s, prefix string) bool {
return len(s) >= len(prefix) && s[:len(prefix)] == prefix
}
// 判断是子串
func Contains(s, substr string) bool {
for i := 0; i < len(s); i++ {
if HasPrefix(s[i:], substr) {
return true
}
}
return false
}
s := "Hallo, 世界"
s1 := "你好"
fmt.Println(s)
fmt.Println(len(s)) // 13
fmt.Println(len(s1)) // 6 utf8中每个中文有3位
fmt.Println(utf8.RuneCountInString(s)) // "9"
// 这样才可以完整的打印s中的每个字符
for i := 0; i < len(s); {
r, size := utf8.DecodeRuneInString(s[i:])
fmt.Printf("%d\t%c\n", i, r)
i += size
}
for i, r := range s {
fmt.Printf("%d \t %q \t %d \n", i, r, r)
}
{
// "program" in Japanese katakana
s := "プログラム"
fmt.Printf("% x \n", s) // "e3 83 97 e3 83 ad e3 82 b0 e3 83 a9 e3 83 a0"
r := []rune(s)
fmt.Printf("%x \n", r) // "[30d7 30ed 30b0 30e9 30e0]"
fmt.Println(string(r)) // "プログラム"
fmt.Println(string(0x4eac)) // "京"
}
strings库
str := "a/b/a/c.go"
// 大小写转换
fmt.Println("strings.ToLower",strings.ToLower("ABHHH"))
fmt.Println("strings.ToUpper",strings.ToUpper(str))
// 查找类型的操作
fmt.Println(strings.LastIndex(str, "/"))
fmt.Println(strings.HasPrefix(str, "a"))
fmt.Println(strings.HasSuffix(str, "go"))
fmt.Println(strings.Contains(str, "a/b"))
fmt.Println(strings.Index(str, "a"))
fmt.Println(strings.LastIndex(str, "a"))
fmt.Println(strings.Count("aaaaabb", "a")) // 有几个子串
// 字符串操作
var strs = []string{"hh", "bb"}
fmt.Println(strings.Join(strs, "/"))//字符串数组的join方法
fmt.Println(strings.Fields("ffied"))
fmt.Println(strings.Repeat(str, 3))
// cut和split一样,cut只分两部分
fmt.Println(strings.Cut(str, "/b"))
fmt.Println(strings.Split(str, ""))
fmt.Println(strings.Replace(str, "a", "z", 1))
fmt.Println(strings.ReplaceAll(str, "a", "z"))
// Trim去开头或者结尾某个字符
fmt.Println(strings.Trim(str, "a"))
fmt.Println(strings.Trim(str, "go"))
// 去除前后的空格,不去中间的空格
fmt.Println(strings.TrimSpace(" aaaaabb "))
func addEveryString(r rune) rune { return r + 1 }
// strings.Map对字符串中的每个字符调用addEveryString函数,并将每个addEveryString函数的返回值组成一个新的字符串返回给调用者
fmt.Println(strings.Map(addEveryString, "Admix")) // "Benjy"
fmt.Println(strings.Map(addEveryString, "Hello")) // "Ifmmp"
fmt.Println(strings.Map(addEveryString, "David")) // "Ebwje"
方法 - 整数数组转字符串
func intToString(values []int) string {
var buf bytes.Buffer
buf.WriteRune('[')
for i, v := range values {
if i > 0 {
buf.WriteString(", ")
}
fmt.Fprintf(&buf, "%d", v)
}
buf.WriteRune(']')
return buf.String()
}
字符串转数字
// 字符串转数字,第三位是16表示返回值是int16
var i, e = strconv.ParseInt("1f", 16, 16)
if e == nil {
fmt.Println("parsed success, the result is ", i)
}else {
fmt.Println("parsed failed")
}
// 字符串转数字
var i1, e1 = strconv.Atoi("1f")
fmt.Println(i1)
fmt.Println(e1)
数字转字符串
// 数字转字符串
var str1 string = strconv.Itoa(111)
fmt.Println(str1)
数组
数组是定长的,默认情况下,数组的每个元素都被初始化为元素类型对应的零值。
// 声明a是一个又3个int类型的数组
var a [3]int
fmt.Println(a[0])
fmt.Println(len(a))
var strs = []string{"flower","flow","flight"}
for i, v := range a {
fmt.Printf("%d %d\n", i, v)
}
... 表示,数组的长度取决于初始化的值的数量
q := [...]int{1, 2, 3}
如果一个数组的元素类型是可以相互比较的,那么数组类型也是可以相互比较的
a := [...]int{1,2}
c := [...]int{1,2}
d := [...]int{1,3}
fmt.Println(a == c) // true
fmt.Println(a != d) // true
函数调用的时候,函数的每个调用参数将会被赋值给函数内部的参数变量,所以函数参数变量接收的是一个复制的副本。因为函数参数传递的机制导致传递大的数组类型将是低效的,并且对数组参数的任何的修改都是发生在复制的数组上,并不能直接修改调用时原始的数组变量。
数组依然是僵化的类型,我们一般使用slice来替代数组。
slice
-
slice的语法和数组很像,只是没有固定长度而已。
-
一个slice由三个部分构成:指针、长度和容量。指针指向第一个slice元素对应的底层数组元素的地址,slice第一个元素并不一定是数组的第一个元素。长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
-
多个slice之间可以共享底层的数据,并且引用的数组部分区间可能重叠。
-
切片可以再切片,超出cap(s)的上限将导致一个panic异常,但是超出len(s)则是意味着扩展了slice。
f := []string{"1月", "2月", "3月", "4月", "5月", "6月"} q1 := f[:3] q2 := f[3:] fmt.Println(f) fmt.Println(q1) fmt.Println(q2) fmt.Println(q2[1:4]) -
字符串也可以切片
a:= "healo" fmt.Println(a[1:4]) b:= []byte{'1', '2', '3'} fmt.Println(b[:2]) -
对切片的操作
// 反转切片 func reverse(s []int) { for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 { s[i], s[j] = s[j], s[i] } } arr1 := [...]int{0, 1, 2, 3, 4, 5} reverse(arr1[:]) fmt.Println(arr1) // "[5 4 3 2 1 0]" s := []int{0, 1, 2, 3, 4, 5} reverse(s[:2]) reverse(s[2:]) reverse(s) fmt.Println(s) // "[2 3 4 5 0 1]" -
和数组不同的是,slice之间不能比较。而且slice会隐式地创建一个合适大小的数组,然后slice的指针指向底层的数组。
-
内置的make函数创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度
make([]T, len) make([]T, len, cap) // same as make([]T, cap)[:len] -
copy方法,第一个参数是要复制的目标slice,第二个参数是源slice ,copy函数将返回成功复制的元素的个数
slice := []int{1,2,3,4} num :=copy(slice[1:], slice[2:]) fmt.Println(num) // 2 fmt.Println(slice) // [1 3 4 4] -
内置的append函数用于向slice追加元素,不能确认新的slice和原始的slice是否引用的是相同的底层数组空间,也不能确认在原先的slice上的操作是否会影响到新的slice。所以通常是将append返回的结果直接赋值给输入的slice变量。
func appendInt(x []int, y int) []int {
var z []int
zlen := len(x) + 1
if zlen <= cap(x) {
// There is room to grow. Extend the slice.
z = x[:zlen]
} else {
// There is insufficient space. Allocate a new array.
// Grow by doubling, for amortized linear complexity.
zcap := zlen
if zcap < 2*len(x) {
zcap = 2 * len(x)
}
z = make([]int, zlen, zcap)
// 为了提高内存使用效率,新分配的数组一般略大于保存x和y所需要的最低大小。通过在每次扩展数组时直接将长度翻倍从而避免了多次内存分配,也确保了添加单个元素操作的平均时间是一个常数时间
copy(z, x)
}
z[len(x)] = y
return z
}
// append 方法可以追加多个元素,甚至是一个slice
var x []int
x = append(x, 1)
x = append(x, 2, 3)
x = append(x, 4, 5, 6)
// x... 表示可变的参数的slice
x = append(x, x...)
map
- map中所有的key都有相同的类型,所有的value也有着相同的类型
- 禁止对map元素取址
- map只能和
nil比较 - map没有清空键值对的方法,清空 map 的唯一办法就是重新 make 一个新的 map
func main() {
map1 := map[string]string{
"name": "david",
"age": "22",
}
// 删除属性
delete(map1, "age")
map2 := make(map[string]string)
map2["name"] = "tina"
println(map1["name"])
// 不存在就返回value的0值
println(map2["age"])
// map的遍历
for key,value := range map2 {
fmt.Printf("key=%s,value=%s", key, value)
}
map3 := map[string]string{
"1倍社保": "12183",
"2倍社保": "24366",
"3倍社保": "36549",
}
fmt.Println(map3["1倍社保"])
var ages = map[string]int {
"lily": 12,
}
ages["bs"] = 11
fmt.Println(ages == nil)
fmt.Println(len(ages))
fmt.Println(len(map2))
// 判断属性是否存在
age, ok := ages["lily"]
if ok {
fmt.Println("存在")
fmt.Println(age)
} else {
fmt.Println("不存在")
}
}
struct
- 如果结构体成员名字是以大写字母开头的,那么该成员就是导出的
type Person struct { city, Area string age, salary int position string } func structDemo1() { var david = Person{ city: "shanghai", Area: "xuhui", age: 12, position: "小队长", salary: 33333, } c := &david.city *c = "chengdu" fmt.Println(david) fmt.Println(david.city) } - 指向结构体的指针 也可以使用点操作符
var personPointer *Person = &david fmt.Println(personPointer.age) - 结构体不能包含自身结构体,但是指针可以
type Person struct { city, Area string age, salary int position string Person *Person } - 结构体字面量
type Point struct{ X, Y int } p := Point{1, 2} fmt.Println(p.X) fmt.Printf("%#v\n", p) // main.Circle{X:1, Y:2} p1 := Point{X: 2} p2 := Point{X: 3, Y: 3} fmt.Println(p1.X) fmt.Println(p2.X) func Scale(p Point, factor int) Point { return Point{p.X * factor, p.Y * factor} } fmt.Println(Scale(Point{1, 2}, 5)) // "{5 10}" - 因为结构体通常通过指针处理,可以用下面的写法来创建并初始化一个结构体变量,并返回结构体的地址:
pointer1 := &Point{1, 2} - 如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的
p2 := Point{X: 3, Y: 3} p3 := Point{X: 3, Y: 3} println(p2 == p3) // true - 结构体嵌入和匿名成员,只声明成员数据类型而不定义成员名就叫匿名成员,匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针
type Circle struct { X, Y, Radius int } type Wheel struct { X, Y, Radius, Spokes int } c1 := Circle{22,1,1} fmt.Println(c1.X) var c Circle c.X = 1 c.Y = 1 c.Radius = 1 fmt.Println(c.X) var w Wheel w.X = 8 w.Y = 8 w.Radius = 5 w.Spokes = 20 // ---------------- 上边的大量重复代码,可以使用结构体的嵌入 type Point struct { X, Y int } type Circle1 struct { Center Point Radius int } type Circle2 struct { // 只声明成员数据类型而不定义成员名就叫匿名成员 // 匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针 Point Radius int } - 得益于匿名嵌入的特性,我们可以直接访问叶子属性而不需要给出完整的路径。结构体字面值不可以简短表示匿名成员的语法。
指针
- 指针,基本和c语言的指针是一样的
- 任何类型的指针的零值都是nil
- 返回函数中局部变量的地址也是安全的
var p = f() func f() *int { v := 1 return &v } // 每次调用f函数都将返回不同的结果: fmt.Println(f() == f()) // "false" - 下边代码是传入变量指针,来修改变量的值并返回
func incr(p *int) int { *p++ // 非常重要:只是增加p指向的变量的值,并不改变p指针!!! return *p } v := 1 incr(&v) fmt.Println(incr(&v)) - 另一个创建变量的方法是调用内建的new函数。表达式new(T)将创建一个T类型的匿名变量,初始化为T类型的零值,然后返回变量地址,返回的指针类型为*T
new函数使用通常相对比较少p := new(int) // p, *int 类型, 指向匿名的 int 变量 fmt.Println(*p) // "0" *p = 2 // 设置 int 匿名变量的值为 2 fmt.Println(*p) // "2" // 这两个是等价的 func newInt() *int { return new(int) } func newInt() *int { var dummy int return &dummy }
make与new
new和make是内建的两个函数,主要用来创建分配类型内存new用于类型内存分配(初始化值为0), 不常用。 返回的永远是类型的指针,指向分配类型的内存地址。var i *int i=new(int)- make: 只用于slice、map以及channel的初始化
json
- 只有导出的结构体成员才会被编码,这也就是我们为什么选择用大写字母开头的成员名称。
- 定义结构体字段的tag可以改变生产json的字段
persons:= []Teacher{ { Name: "david", Age: 22, Money: 7000, }, { Name: "tom", Age: 11, Money: 3333, }, } data, err := json.MarshalIndent(persons, "", " ") if err != nil { log.Fatalf("JSON marshaling failed: %s", err) } else { fmt.Printf("%s\n", data) } var titles []Teacher if err := json.Unmarshal(data, &titles); err != nil { log.Fatalf("JSON unmarshaling failed: %s", err) } fmt.Println(titles)
文本和html模板
import (
"log"
"os"
"text/template"
)
type Student struct {
Name string
Age int
Habbits []string
Normal string
}
var students = []Student{
{Name:"tom", Age:19, Habbits:[]string{"dance", "write"}, Normal:"正常"},
{Name:"david", Age:20, Habbits:[]string{"eat"}, Normal:"正常"},
}
func addString(normal string) string {
return normal + "模式"
}
const templ = `students:
{{range .}}-------------------------------------------------------------
Name: {{.Name}}
Age: {{.Age}}
Habbits:{{range $_,$item := .Habbits}}{{$item | printf "%s\t"}}{{end}}
Normal: {{.Normal | addString}}{{printf "\n"}}
{{end}}`
func main() {
report, err := template.New("report").Funcs(template.FuncMap{"addString": addString}).Parse(templ)
if err != nil {
log.Fatal(err)
}
if err := report.Execute(os.Stdout,students); err != nil {
log.Fatal(err)
}
}
import (
"encoding/json"
"fmt"
"html/template"
"log"
"os"
)
const templ = `<!DOCTYPE html>
<html>
<meta charset="utf-8"/>
<head>
<title>主页</title>
</head>
<body>
<form>
<table align="center">
{{range .}}
<tr>
<td>Name:</td>
<td>{{.Name}}</td>
</tr>
<tr>
<td>Age:</td>
<td>{{.Age}}</td>
</tr>
<tr>
<td>Habbits:</td>
{{range $_, $habbit := .Habbits}}
<td>{{$habbit}}</td>
{{end}}
</tr>
<tr>
<td>{{.Normal | addString}}</td>
</tr>
{{end}}
</table>
</form>
<body>
</html>`
type Student struct {
Name string
Age int
Habbits []string
Normal string
}
func addString(normal string) string {
return "在" + normal
}
var students = []Student{
{Name:"Tom", Age:19, Habbits:[]string{"eat", "drink"},Normal:"吃饭"},
{Name:"Jack", Age:20, Habbits:[]string{"sleep"},Normal:"睡觉"},
}
func main() {
report, err := template.New("report").Funcs(template.FuncMap{"addString": addString}).Parse(templ)
if err != nil {
log.Fatal(err)
}
if err := report.Execute(os.Stdout, students); err != nil {
log.Fatal(err)
}
}
函数
-
函数返回值可省略,也可以定义局部变量
-
如果两个函数形式参数列表和返回值列表中的变量类型一一对应,那么这两个函数被认为有相同的类型或签名
-
每一次调用都必须按照声明顺序为所有参数提供实参(参数值)
-
Go语言没有默认参数值
-
实参通过值的方式传递,因此函数的形参是实参的拷贝
-
在函数体中,函数的形参作为局部变量,被初始化为调用者提供的值。函数的形参和有名返回值作为函数最外层的局部变量,被存储在相同的词法块中
func f1(a int, b int, c, d int) int{ return a + b } func sub(x, y int) (z int) { z = x - y return } -
多返回值
func multiReturn(a int)(b int, c int) { return a + 1, a * 2 } func main() { a, b := multiReturn(22) fmt.Println(a) fmt.Println(b) } -
匿名函数,函数字面量,闭包
var f1 = func(r rune) rune { return r + 1 } func squares() func() int { var x int return func() int { x++ return x * x } } f := squares() fmt.Println(f()) // "1" fmt.Println(f()) // "4" fmt.Println(f()) // "9" fmt.Println(f()) // "16" -
可变参数
func sum1(args ... int) int{ return 1 } var a = []int{1,2} fmt.Println(sum1(a...)) -
defer是go中一种延迟调用机制,defer后面的函数只有在当前函数执行完毕后才能执行,将延迟的语句按defer的逆序进行执行,也就是说先被defer的语句最后被执行,最后被defer的语句,最先被执行,通常用于释放资源。
defer语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。通过defer机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。释放资源的defer应该直接跟在请求资源的语句后。
defer不影响return,return之后仍然可以defer。当函数遇到panic,defer仍然会被执行。Go会先执行所有的defer链表(该函数的所有defer),当所有defer被执行完毕且没有recover时,才会进行panic。所以defer 最大的功能是 panic 后依然有效,所以defer可以保证你的一些资源一定会被关闭,从而避免一些异常出现的问题。defer fmt.Println("defer 1") defer fmt.Println("defer 2") defer fmt.Println("defer 3") fmt.Println("1") fmt.Println("2") // 结果是 // 1 // 2 // defer 3 // defer 2 // defer 1func function(index int, value int) int { fmt.Println(index) return index } defer function(1, function(3, 0)) defer function(2, function(4, 0)) // 结果是 3 4 2 1
方法
- 在函数声明时,在其名字之前放上一个变量(类型),即是一个方法。
- 可以看做是面向对象的一种另类实现,往某个对象添加方法,并且能够给任意类型定义方法。
type Point struct{ X, Y float64 } // 普通函数 func Distance(p, q Point) float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) } // 这是一个方法,附加在p上 func (p Point) Distance(q Point) float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) } x := Point{1, 2} y := Point{4, 6} fmt.Println(Distance(x, y)) // "5", function call fmt.Println(x.Distance(y)) // "5", method call fmt.Println(y.Distance(x)) // "5", method call - 基于指针对象的方法,当调用函数时会对每个参数值进行拷贝,如果函数需要更新一个变量或者函数其中一个参数太大希望能够避免默认拷贝,这种情况需要用指针。对应到这里用来更新接收器的对象的方法,当这个接受者变量比较大可以用其指针而不是对象来声明方法。如果接收器本身类型就是指针,是不行的。
func (p *Point) ScaleBy(factor float64) { p.X *= factor p.Y *= factor } r := &Point{1, 2} r.ScaleBy(2) fmt.Println(*r) // "{2, 4}" - Nil也是一个合法的接收器类型,如下是一个链表
type IntList struct { Value int Tail *IntList } // Sum returns the sum of the list elements. func (list *IntList) Sum() int { if list == nil { return 0 } return list.Value + list.Tail.Sum() } - 使用嵌入结构体来扩展类型,如果一个struct类型也可能会有多个匿名对象,那这个类型就有匿名对象所有的方法
type Point struct{ X, Y int }
type ColoredPoint struct {
Point
Color color.RGBA
}
func (p *Point) scale(size int){
p.Y += size
p.X = 12
}
func (p Point) Distance(q Point) int {
return q.X-p.X
}
func main() {
var cp ColoredPoint
cp.Point.Y = 2
fmt.Println(cp.Y)
red := color.RGBA{255, 0, 0, 255}
blue := color.RGBA{0, 0, 255, 255}
var p = ColoredPoint{Point{1, 1}, red}
var q = ColoredPoint{Point{5, 4}, blue}
fmt.Println(p.Distance(q.Point)) // 注意是q.point,不可以直接使用q
p.scale(2)
q.scale(2)
fmt.Println(p.Distance(q.Point)) // "10"
}
错误处理
- Go 采用明确的 error 值和类似异常的 panic 机制的方式作为独有的错误处理机制
- 在Go中,函数运行失败时会返回错误信息,这些错误信息被认为是一种预期的值而非异常。
- Go使用控制流机制(如if和return)处理错误。
content, err := os.ReadFile("fa.txt") if err != nil { fmt.Println(err) } fmt.Println(string(content))
panic 异常
Go的类型系统会在编译时捕获很多错误,但有些错误只能在运行时检查,如数组访问越界、空指针引用等。这些运行时错误会引起panic异常。
一般而言,当panic异常发生时,程序会中断运行,并立即执行在该goroutine(可以先理解成线程,在第8章会详细介绍)中被延迟的函数(defer 机制)。随后,程序崩溃并输出日志信息。日志信息包括panic value和函数调用的堆栈跟踪信息。
recover
通常来说,不应该对panic异常做任何处理,但有时,也许我们可以从异常中恢复,至少我们可以在程序崩溃前,做一些操作。
- recover必须搭配defer来使用,否则panic捕获不到;
- defer一定要在可能引发panic的语句之前定义;
func main() { AAA() BBB() CCC() } func AAA() { fmt.Println("func AAA") } func BBB() { defer func() { if err := recover(); err != nil { fmt.Println("recover in func BBB") fmt.Println(fmt.Sprintf("%v", err)) //...handle 打日志等 } }() panic("func BBB") //panic之前,如果没有recover,则程序会崩溃,异常退出。有则继续执行 } func CCC() { fmt.Println("func CCC") } // func AAA // recover in func BBB // err = func BBB // func CCC
接口类型
- 接口类型具体描述了一系列方法的集合,实现了这些方法的具体类型是这个接口类型的实例。接口是方法的集合也是一种类型。在Go 语言中是隐式实现的,意思就是对于一个具体的类型,不需要声明它实现了哪些接口,只需要提供接口所必需的方法。
代码实例二//声明一个接口 type Human interface{ Say() } //定义两个类,这两个类分别实现了 Human 接口的 Say 方法 type women struct {} type man struct {} func (w *women) Say() { fmt.Println("I'm a women") } func(m *man) Say() { fmt.Println("I'm a man") } var w Human w = new(women) w.Say() m := new(man) m.Say()type SalaryCalculator interface { calculate() int } type Staff struct { id int base int } type Manager struct { id int base int bonus int } func (s Staff)calculate() int { return s.base } func (m Manager)calculate() int { return m.base + m.bonus } func main() { staff1 := Staff{1, 3000} manager1 := Manager{10, 5000, 2000} employees := []SalaryCalculator{staff1, manager1} sum := 0 for _, v := range employees { sum += v.calculate() } fmt.Printf("总共发工资=%d", sum) } - 接口还可以组合已有的接口,这种方式称为接口内嵌
type Writer interface { } type ReadWriter interface { Reader Writer } - 通常一个具体的类型描述成一个特定的接口类型,类似OOP的多态
var w io.Writer w = os.Stdout // OK: *os.File has Write method w = new(bytes.Buffer) // OK: *bytes.Buffer has Write method - interface{}被称为空接口类型是不可或缺的。因为空接口类型对实现它的类型没有要求,所以我们可以将任意一个值赋给空接口类型
var any interface{} any = true any = 12.34 any = "hello" any = map[string]int{"one": 1} - 类型断言,类型断言用于提取接口的基础值,语法:i.(T)
func assert(i interface{}) { v, ok := i.(int) fmt.Println(v, ok) } var s interface{} = 56 assert(s) var i interface{} = "Steven Paul" assert(i) - 类型判断,类似于类型断言,代码如下,可以判断是具体的类型。
func findType(i interface{}) { switch i.(type) { case string: fmt.Printf("String: %s\n", i.(string)) case int: fmt.Printf("Int: %d\n", i.(int)) case float64: fmt.Printf("float64: %f\n", i.(float64)) case Manager: fmt.Println("this is manager") default: fmt.Printf("Unknown type\n") } } findType(11) findType(11.1) findType("halo") findType(manager1)
反射
反射的缺点有
- 代码不易阅读,不易维护,容易发生线上panic
- 性能很差,比正常代码慢一到两个数量级
go语言反射里最重要的两个概念是Type和Value
package main
import (
"fmt"
"reflect"
)
type Person struct {
city, Area string
age, salary int
position string
eat func()
}
func eat() {
fmt.Println("eating")
}
func (p Person) fn() int {
return 1
}
func main() {
var david = Person{
city: "shanghai",
Area: "xuhui",
age: 12,
position: "小队长",
salary: 33333,
}
typeI := reflect.TypeOf(1)
typeS := reflect.TypeOf("hello")
type2 := reflect.TypeOf(david)
fmt.Println(typeI) //int
fmt.Println(typeS) //string
fmt.Println(type2) //main.Person
fmt.Println(reflect.ValueOf(1)) // 1
fmt.Println(reflect.ValueOf(1).Type()) // int
// 获取struct成员变量的信息
fieldNum := type2.NumField() //成员变量的个数
for i := 0; i < fieldNum; i++ {
field := type2.Field(i)
fmt.Printf("%d %s offset=%d anonymous=%t type=%s exported=%t json tag %s\n", i,
field.Name, //变量名称
field.Offset, //相对于结构体首地址的内存偏移量,string类型会占据16个字节
field.Anonymous, //是否为匿名成员
field.Type, //数据类型,reflect.Type类型
field.IsExported(), //包外是否可见(即是否以大写字母开头)
field.Tag.Get("json")) //获取成员变量后面``里面定义的tag
}
fmt.Println("-------")
//获取struct成员方法的信息
methodNum := type2.NumMethod() //成员方法的个数。接收者为指针的方法【不】包含在内
for i := 0; i < methodNum; i++ {
method := type2.Method(i)
fmt.Printf("method name:%s ,type:%s, exported:%t\n", method.Name, method.Type, method.IsExported())
}
fmt.Println()
typeFunc := reflect.TypeOf(Add) //获取函数类型
fmt.Printf("is function type %t\n", typeFunc.Kind() == reflect.Func)
argInNum := typeFunc.NumIn() //输入参数的个数
argOutNum := typeFunc.NumOut() //输出参数的个数
for i := 0; i < argInNum; i++ {
argTyp := typeFunc.In(i)
fmt.Printf("第%d个输入参数的类型%s\n", i, argTyp)
}
for i := 0; i < argOutNum; i++ {
argTyp := typeFunc.Out(i)
fmt.Printf("第%d个输出参数的类型%s\n", i, argTyp)
}
}
// 获取函数的信息
func Add(a, b int) int {
return a + b
}
时间
时间类型有一个自带的方法Format进行格式化,需要注意的是Go语言中格式化时间模板不是常见的Y-m-d H:M:S而是使用Go的诞生时间2006年1月2号15点04分(记忆口诀为2006 1 2 3 4)
// 定时器
timer := time.Tick(time.Second)
for v1 := range timer {
fmt.Println(v1.Format("2006-01-02 15:04:05"))
}
// 貌似也可以你这么写
for{
time.Sleep(time.Second)
fmt.Println(v1.Format("2006-01-02 15:04:05"))
}
now := time.Now()
fmt.Printf("当前时间是:%s\n", now.String())
// 24小时制
fmt.Println(now.Format("2006-01-02 15:04:05.000 Mon Jan"))
// 12小时制
fmt.Println(now.Format("2006-01-02 03:04:05.000 PM Mon Jan"))
fmt.Println(now.Format("2006/01/02 15:04:05"))
fmt.Println(now.Format("2006/01/02"))
fmt.Printf("%d年%d月%d日", now.Year(), now.Month(), now.Day())
fmt.Printf(" %d:%d:%d", now.Hour(), now.Minute(), now.Second())
timestamp1 := now.Unix() //时间戳
timestamp2 := now.UnixNano() //纳秒时间戳
fmt.Println()
fmt.Printf("当前时间戳是:%v\n", timestamp1)
fmt.Printf("当前时间戳是:%v\n", timestamp2)
// 1个小时之后
endTime := now.Add(time.Minute * 60)
// 时间前后比较
if now.Before(endTime) {
fmt.Println("now 在 endTime 之前")
}
if now.After(endTime) {
fmt.Println("now 在 endTime 之后")
}
gap := endTime.Sub(now).Nanoseconds()
// 计算时间间隔
Duration := time.Unix(0, gap)
// 时间戳是自1970年1月1日(08:00:00GMT)到当前时间总毫秒数
fmt.Printf("时间相差: %d小时%d分钟%d秒", Duration.Hour()-8, Duration.Minute(), Duration.Second())
// 时间由字符串转化
var a, err = time.Parse("2006-01-02", "2022-07-18")
if err != nil {
fmt.Println("error")
} else {
fmt.Println(a.Month())
fmt.Println(a.Year())
}
命令行参数
flag库提供了命令行参数解析功能
import (
"flag"
"fmt"
)
var host string
flag.StringVar(&host, "host", "", "数据库地址")
flag.Parse()
fmt.Printf("数据库地址:%s\n", host)
// go run main.go -host="127.0.0.1"
// 数据库地址:127.0.0.1
文件操作
io包保证任何由文件结束引起的读取失败都返回同一个错误——io.EOF
创建文件
func fileCreate() {
var (
newFile *os.File
err error
)
newFile, err = os.Create("test.txt")
if err != nil {
log.Fatal(err)
}
log.Println(newFile)
newFile.Close()
}
文件信息、重命名和移动、删除
func fileInfo() {
var (
fileInfo os.FileInfo
err error
)
err1 := os.Rename("test.txt", "new.txt")
// 删除文件
err2 := os.Remove("test.txt")
fileInfo, err = os.Stat("test.txt")
if err != nil {
log.Fatal(err)
}
fmt.Println("File name:", fileInfo.Name())
fmt.Println("Size in bytes:", fileInfo.Size())
fmt.Println("Permissions:", fileInfo.Mode())
fmt.Println("Last modified:", fileInfo.ModTime())
fmt.Println("Is Directory: ", fileInfo.IsDir())
fmt.Printf("System interface type: %T\n", fileInfo.Sys())
fmt.Printf("System info: %+v\n\n", fileInfo.Sys())
}
裁剪文件
// Truncate裁剪文件 2个字节,
// 如果文件不存在就创建文件,不会报错
err := os.Truncate("a.txt", 2)
if err != nil {
fmt.Println("error")
}
fmt.Println("Truncate done")
读取文件
// 读取整个文件
content, err := os.ReadFile("a.txt")
if err != nil {
fmt.Println("read file error")
}
fmt.Println(string(content))
写入文件,被写入文件原来的内容会被擦除
err := os.WriteFile("a.txt", []byte("Hi\n"), 0666)
if err != nil {}
关于包
go modules是 golang 1.11 新加的特性,是用来管理包的工具。每个语言都有,类似java的maven,nodejs的npm。- main 包比较特殊,它定义了一个独立可执行的程序,而不是一个库。
- 在 main包 里的 main 函数也很特殊,它是整个程序执行时的入口
- 缺少了包或者导入多余的包,程序都无法编译通过
- 包中的变量,大写的就是导出的
- 我们可以用一个特殊的init初始化函数来简化初始化工作,不能被调用或引用外其他行为和普通函数类似,可以多个,按照顺序调用
- 导入同名包,重命名
import ( "crypto/rand" mrand "math/rand" // alternative name mrand avoids conflict )
关于并发
基本名词
相关的名词有,进程(Process)、线程(Thread)、协程(Coroutine,也叫轻量级线程)。并发是一个cpu同时执行多个线程,在一个时间点内只有一个任务在执行。并行是多个cpu上执行多个线程,就相当于一个cpu执行一个线程,在一个时间点内有多个任务在同时执行。1.8 版本以上的会自动设置Go语言运行使用的cpu核数。每一个并发的执行单元叫作一个 goroutine(协程),可以简单地把goroutine类比作一个线程。
主线程是一个物理线程,直接作用在cpu上,是重量级的,非常耗费cpu资源。协程从主线程开启,是轻量级的线程,是逻辑态,对资源的耗费相对较小,golang的协程机制是重要的特点,可以轻松的开启上万个协程(goroutine)。其他语言的并发机制是一般基于线程的,开启过多的线程耗费资源大,这里就凸显出golang的优势了,注意协程并不是go语言独有的。
goroutine使用
当一个程序启动时,其主函数即在一个单独的goroutine中运行,我们叫它main goroutine。新的goroutine会用go语句来创建。在语法上,go语句是一个普通的函数或方法调用前加上关键字go。go语句会使其语句中的函数在一个新创建的goroutine中运行。
主函数返回时,所有的goroutine都会被直接打断,程序退出。除了从主函数退出或者直接终止程序之外,没有其它的编程方法能够让一个goroutine来打断另一个的执行,但是之后可以看到一种方式来实现这个目的,通过goroutine之间的通信来让一个goroutine请求其它的goroutine,并让被请求的goroutine自行结束执行。
func main() {
go spinner(100 * time.Millisecond)
const n = 45
fibN := fib(n) // slow
fmt.Printf("\rFibonacci(%d) = %d\n", n, fibN)
}
func spinner(delay time.Duration) {
for {
for _, r := range `-\|/` {
fmt.Printf("\r%c", r)
time.Sleep(delay)
}
}
}
func fib(x int) int {
if x < 2 {
return x
}
return fib(x-1) + fib(x-2)
}
sync.Mutex 互斥锁
使用goroutine来完成,效率高,但是会出现并发/并行安全问题,不同goroutine之间如何通讯,一是全局变量互斥锁,二是使用channel来解决。如下代码,会报错 fatal error: concurrent map writes
var(
myMap=make(map[int]int,10)
)
//计算n!并放入到map里
func operation(n int) {
res:=1
for i:=1;i<=n;i++{
res*=i
}
myMap[n]=res
}
func Test3() {
//我们开启多个协程去完成这个任务
for i:=1;i<=200;i++{
go operation(i)
}
time.Sleep(time.Second*10)
fmt.Println(myMap)
}
使用互斥锁来解决问题
import (
"fmt"
"sync"
"time"
)
var(
myMap2=make(map[int]uint64,10)
//声明一个全局互斥锁,lock是一个全局互斥锁,sync是包:synchorized同步
//Mutex:是互斥
lock sync.Mutex
)
func operation2(n int) {
var res uint64=1
for i:=1;i<=n;i++{
res*=uint64(i)
}
//我们将res放入myMap
//加锁
lock.Lock()
myMap2[n]= res
//解锁
lock.Unlock()
}
func Test4() {
for i:=1;i<=200;i++{
go operation2(i)
}
time.Sleep(time.Second*10)
//这里我们输出
//加锁
lock.Lock()
fmt.Println(myMap2)
lock.Unlock()
}
使用channel
channel是一个通信机制,它可以让一个goroutine通过它给另一个goroutine发送值信息。channel本质是一个是先进先出的队列,线程安全,多个goroutine访问时,不需要加锁。channel有类型的,一个string的channel只能存放string类型的数据。
channel是引用类型,channel必须初始化才能写入数据,即make后才能用,管道是有类型的,intChan只能写入整数int。
一个channel有发送和接受两个主要操作,都是通信行为。一个发送语句将一个值从一个goroutine通过channel发送到另一个执行接收操作的goroutine。发送和接收两个操作都使用 <- 运算符。
func Test5() {
//1,创建一个可以存放3个int类型的管道
var intChan chan int
intChan=make(chan int,3)
//2,看看intChan是什么
fmt.Printf("值:%V 地址:%p\n",intChan,&intChan)
//3,向管道写入数据,注意不要超过它的容量
intChan<-10
num:=211
intChan<-num
intChan<-50
fmt.Printf("长度 len=%v cap=%v\n",len(intChan),cap(intChan))
//4,从管道里读取数据
var num2 int
num2=<-intChan
fmt.Println("num2=",num2)
fmt.Printf("长度 len=%v cap=%v\n",len(intChan),cap(intChan))
//5,在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告deadlock
num3:=<-intChan
num4:=<-intChan
num5:=<-intChan
fmt.Println("num3=",num3,"num4=",num4,"num5=",num5)
}
Channel还支持close操作,用于关闭channel,close(ch),随后对基于该channel的任何发送操作都将导致panic异常。在遍历时,如果channel没有关闭,则会出现fatal error: all goroutines are asleep - deadlock!错误。对一个已经被close过的channel进行接收操作依然可以接受到之前已经成功发送的数据;如果channel中已经没有数据的话将产生一个零值的数据。
func Test6() {
intChan := make(chan int, 5)
for a := 0; a < 5; a++ {
intChan<-a
}
close(intChan)
for a := range intChan {
fmt.Println(a)
}
}
有缓冲channel和无缓冲channel
无缓冲channel在消息发送时需要接收者就绪。声明无缓冲channel的方式是不指定缓冲大小。示例如下
func channel1() {
c := make(chan string)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
// 会在发送消息foo时阻塞,原因是接收者还没有就绪
c <- `foo`
}()
go func() {
defer wg.Done()
time.Sleep(time.Second * 1)
println(`Message: `+ <-c)
}()
wg.Wait()
}
channel的结构体hchan被定义在runtime包中的chan.go文件中。以下是无缓冲channel的内部结构(本小节先介绍无缓冲channel,所以暂时忽略了hchan结构体中和缓冲相关的属性):
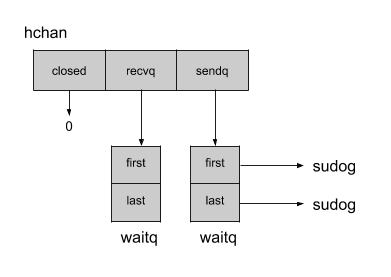
channel中持有两个链表,接收者链表recvq和发送者链表sendq,它们的类型是waitq。链表中的元素为sudog结构体类型,它包含了发送者或接收者的协程相关的信息。通过这些信息,Go可以在发送者不存在时阻塞住接收者,反之亦然。
以下是我们前一个例子的流程:
- 创建一个发送者列表和接收者列表都为空的channel。
- 第一个协程向channel发送foo变量的值,第16行。
- channel从池中获取一个sudog结构体变量,用于表示发送者。sudog结构体会保持对发送者所在协程的引用,以及foo的引用。
- 发送者加入sendq队列。
- 发送者协程进入等待状态。
- 第二个协程将从channel中读取一个消息,第23行。
- channel将sendq列表中等待状态的发送者出队列。
- chanel使用memmove函数将发送者要发送的值进行拷贝,包装入sudog结构体,再传递给channel接收者的接收变量。
- 在第五步中被挂起的第一个协程将恢复运行并释放第三步中获取的sudog结构体。
如流程所描述,发送者协程阻塞直至接收者就绪。但是,必要的时候,我们可以使用有缓冲channel来避免这种阻塞。
channel可以声明为只读或者只写
// 只写
var chan1 chan <- int
// 只读
var chan2 <- chan int
channel使用实例
开启一个writeData协程,向管道intChan中写入五十个数
开启一个readDate协程,从管道intChan中读取writeData写入数据
WriteData和readData操作的是同一个管道
主线程需要等待writeData和readData协程都完成工作才能退出管道
var intChan = make(chan int, 10)
var exitChan =make(chan bool,1)
func writeData() {
for a:=0; a< 10; a++ {
intChan<-a
fmt.Printf("write a = %d\n", a)
}
close(intChan)
}
func readData() {
for a:= range intChan {
fmt.Printf("read a = %d\n", a)
}
exitChan<-true
close(exitChan)
}
func main() {
go writeData()
go readData()
for {
_,ok:=<-exitChan
fmt.Println("finish")
if!ok{
break
}
}
}
sync.Waitgroup
go 里面的 WaitGroup 是非常常见的一种并发控制方式,它可以让我们的代码等待一组 goroutine 的结束。
import (
"fmt"
"sync"
)
func waitGroupFn() {
var wg sync.WaitGroup
// 计数器 +2
wg.Add(2)
go func() {
sendHttpRequest("https://baidu.com")
// 计数器 -1
wg.Done()
}()
go func() {
sendHttpRequest("https://baidu.com")
// 计数器 -1
wg.Done()
}()
// 在函数的最后,我们调用了 wg.Wait,这个方法会阻塞,
// 直到 WaitGroup 的计数器的值为 0 才会解除阻塞状态
wg.Wait()
}
// 发起 HTTP GET 请求
func sendHttpRequest(url string) {
fmt.Println(url)
}
func main() {
waitGroupFn()
}
WaitGroup 内部通过一个计数器来统计有多少协程被等待。这个计数器的值在我们启动 goroutine 之前先使用 Add 方法写入,然后在 goroutine 结束的时候,使用 Done 方法将这个计数器减 1。在启动这些 goroutine 的协程中会调用 Wait 来进行等待,在 Wait 调用的地方会阻塞,直到 WaitGroup 内部的计数器减到 0,也就实现了等待一组 goroutine 的目的。
信号量
在操作系统中,有多种实现进程/线程间同步的方式,如:test_and_set、compare_and_swap、互斥锁等。 除此之外,还有一种是信号量,它的功能类似于互斥锁,但是它能提供更为高级的方法,以便进程能够同步活动。
扩展 - bit数组
数据流分析领域,集合元素通常是一个非负整数,集合会包含很多元素,并且集合会经常进行并集、交集操作,这种情况下,bit数组会比map表现更加理想。 再比如我们执行一个http下载任务,把文件按照16kb一块划分为很多块,需要有一个全局变量来标识哪些块下载完成了,这种时候也需要用到bit数组。
// An IntSet is a set of small non-negative integers.
// Its zero value represents the empty set.
type IntSet struct {
words []uint64
}
// Has reports whether the set contains the non-negative value x.
func (s *IntSet) Has(x int) bool {
word, bit := x/64, uint(x%64)
return word < len(s.words) && s.words[word]&(1<<bit) != 0
}
// Add adds the non-negative value x to the set.
func (s *IntSet) Add(x int) {
word, bit := x/64, uint(x%64)
for word >= len(s.words) {
s.words = append(s.words, 0)
}
s.words[word] |= 1 << bit
}
// UnionWith sets s to the union of s and t.
func (s *IntSet) UnionWith(t *IntSet) {
for i, tword := range t.words {
if i < len(s.words) {
s.words[i] |= tword
} else {
s.words = append(s.words, tword)
}
}
}
// String returns the set as a string of the form "{1 2 3}".
func (s *IntSet) String() string {
var buf bytes.Buffer
buf.WriteByte('{')
for i, word := range s.words {
if word == 0 {
continue
}
for j := 0; j < 64; j++ {
if word&(1<<uint(j)) != 0 {
if buf.Len() > len("{") {
buf.WriteByte(' ')
}
fmt.Fprintf(&buf, "%d", 64*i+j)
}
}
}
buf.WriteByte('}')
return buf.String()
}
运行时间分析
time go run main.go
real 0m1.343s
user 0m0.000s
sys 0m0.015s
//real :从程序开始到结束,实际度过的时间;
//user :程序在用户态度过的时间;
//sys :程序在内核态度过的时间。
一般情况下 real >= user + sys ,因为系统还有其它进程。














 1490
1490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









