









题外话:有事没事的时候看过hashmap的各种文章,也艰难的“浏览“过源码。借着把好室友吊过来,让他给我理了一下hashmap~加深一下印象。
一。HashMap 是什么?
HashMap 是JAVA集合里面的Map下面的一员大将。
HashMap是一个散列桶(数组和链表) 储存的是K-V键值对。
二。HashMap的几个注意点(欢迎留言补充)
1.不是线程安全的(不同步)
2.key和value都允许空值 (注意 key为null的只有一个,这也满足了key唯一)
3.储存结构如下(转自https://blog.csdn.net/visant/article/details/80045154):

三。储存结构解析(参考上图)
主体解析:
1。左侧竖着的是数组Entry[]
2。横向朝右的为链表(储存hash碰撞后index相同的数据)
如何判断元素该丢到哪里储存?
Hashmap中的put(key,value)方法的用途就不做过多说明,这里主要说一下调用这个方法后做了什么处理.(源码解析)

看到进入put方法后其实又调用了本类里面的putVal

参数解析:
hash: 通过将key传入hash(key)方法后计算出的hash值
key: key
value : value
onlyIfAbsent : onlyIfAbsent if true, don’t change existing value (如果为真,则不改变现在的值)
evict :evict if false, the table is in creation mode. 如果为false 则表为创建模式.
这里暂时不讨论最后两个参数(put调用的putVal方法默认为 onlyIfAbsent : false evict :true)
####################这里单独解释一下hash(key)这个东西 start######################

传入key,当key为null的时候返回0
当key不为null的时候返回的是什么?
首先调用一下key自身的hashCode方法,然后进行了>>>(无符号右移)16位最后与自身进行异或运算(如果相同则为0,不相同则为1)
这里解析一下计算方式

输出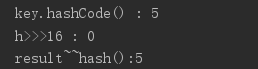
####################这里单独解释一下hash(key)这个东西 end######################
好了,接下来继续分析putVal
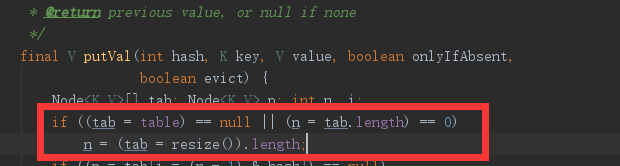
首先看数组是否为空或者长度为0,是的话需要调整数组大小(resize()这个方法很重要 后面说)。

这里用中文理一下这个if要干啥。如果数组tab在某个点(通过计算出来的)没有初始化数据则给他新建结点
这里主要说一下这个计算
这里主要说一下if里面的计算方式。
n是数组大小,n-1与之前算出来的hash进行与运算后作为数组下标。
这里有一个使用的优化:初始hashmap长度为2的次幂
举例说明一下为什么要初始为2的次幂:
例:我初始化一个2^4 = 16 容量的一个hashmap
当他在做如上计算的时候 n-1 = 16 - 1 = 15 ; 二进制为.... 0000 1111
这时如果hash为 15:... 0000 1111 则i =... 0000 1111 十进制为15
这时如果hash为 14:... 0000 1110 则i =... 0000 1110 十进制为14
这样保证了这两个对象将存在不同的桶里(一个横向链表代表一个桶)
例:我初始化一个15 容量的一个hashmap
当他在做如上计算的时候 n-1 = 15- 1 = 14; 二进制为.... 0000 1110
这时如果hash为 15:... 0000 1111 则i =... 0000 1110 十进制为14
这时如果hash为 14:... 0000 1110 则i =... 0000 1110 十进制为14
此时两个计算出的index一样了,只有存在相同的桶里了。横向列表增长意味着,纵向数组使用的比例变低。
增加了碰撞的几率,减慢了查询的效率!而且造成了空间的浪费!
接下来else里面的逻辑

走else里面就表示tab[i]里面本来存在东西了
首先看第一个if,如果tab[i]的key与新put进来的key是一样的(hash一样,equals也一样)就直接覆盖了,其实就是先与数组存的那个结点进行比较而非链表里面的。

再看第二个else if,判断p是不是树结构(jdk1.8后将单链表链表8长度以上的改成了红黑树提升效率),如果是则直接在红黑树里面进行操作了(暂时不深入)

最后一个else,遍历单链表,如果有相同key则覆盖,如果到头了都没有这个key则添加,添加的时候判断链表长度是否大于8 大于8会转成树结构

然后有一个点。put方法如果是覆盖 则会返回被覆盖的value
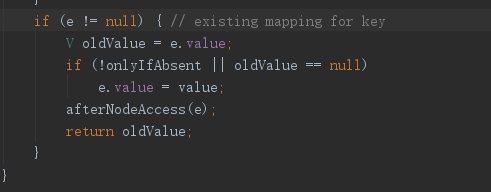
最后判断是否需要扩容

put方法最后给个图(转自https://blog.csdn.net/visant/article/details/80045154)

然后简单聊一下get方法吧。
1、指定key 通过hash函数得到key的hash值
int hash=hash(key);
2、调用内部方法 getNode(),得到桶号(一般为hash值对桶数求模)
int index=hash&( Entry[].length - 1)
3、比较桶的内部元素是否与key相等,若都不相等,则没有找到。相等,则取出相等记录的value。
4、如果得到 key 所在的桶的头结点恰好是红黑树节点,就调用红黑树节点的 getTreeNode() 方法,否则就遍历链表节点。getTreeNode 方法使通过调用树形节点的 find()方法进行查找。由于之前添加时已经保证这个树是有序的,因此查找时基本就是折半查找,效率很高。
5、如果对比节点的哈希值和要查找的哈希值相等,就会判断 key 是否相等,相等就直接返回;不相等就从子树中递归查找。

最后简单理解一下Hashmap调整容量的方法resize().
HashMap的扩容阈值,就是通过它和size进行比较来判断是否需要扩容。
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,
将会创建原来HashMap大小的两倍的数组,来重新调整map的大小,
并将原来的对象放入新的数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
所以,扩容非常消耗性能,如果知道要用的容量大小的前提下,尽量初始化准确一点。















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









