







本次写的爬虫调用了jsoup jar包,jsoup是优秀的HTML解析器,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据,而且封装了get方法,可以直接调用获取页面。结合谷歌浏览器抓取页面元素快感不断。下面简单介绍一下用法顺便贴个知乎爬知乎的代码。
jsoup包的import就不说了,jsoup最主要用到的就是的elements类和select()方法。elements类相当于网页元素中的标签,而select()方法用于按一定条件选取符合条件的标签,组成符合条件的标签数组。element支持转成字符串或者文本等。总之功能很强大。只需要了解一下select()方法的过滤规则即可上手用了。但是有了谷歌浏览器!过滤规则都不用管了,直接上手用!
来个示例:
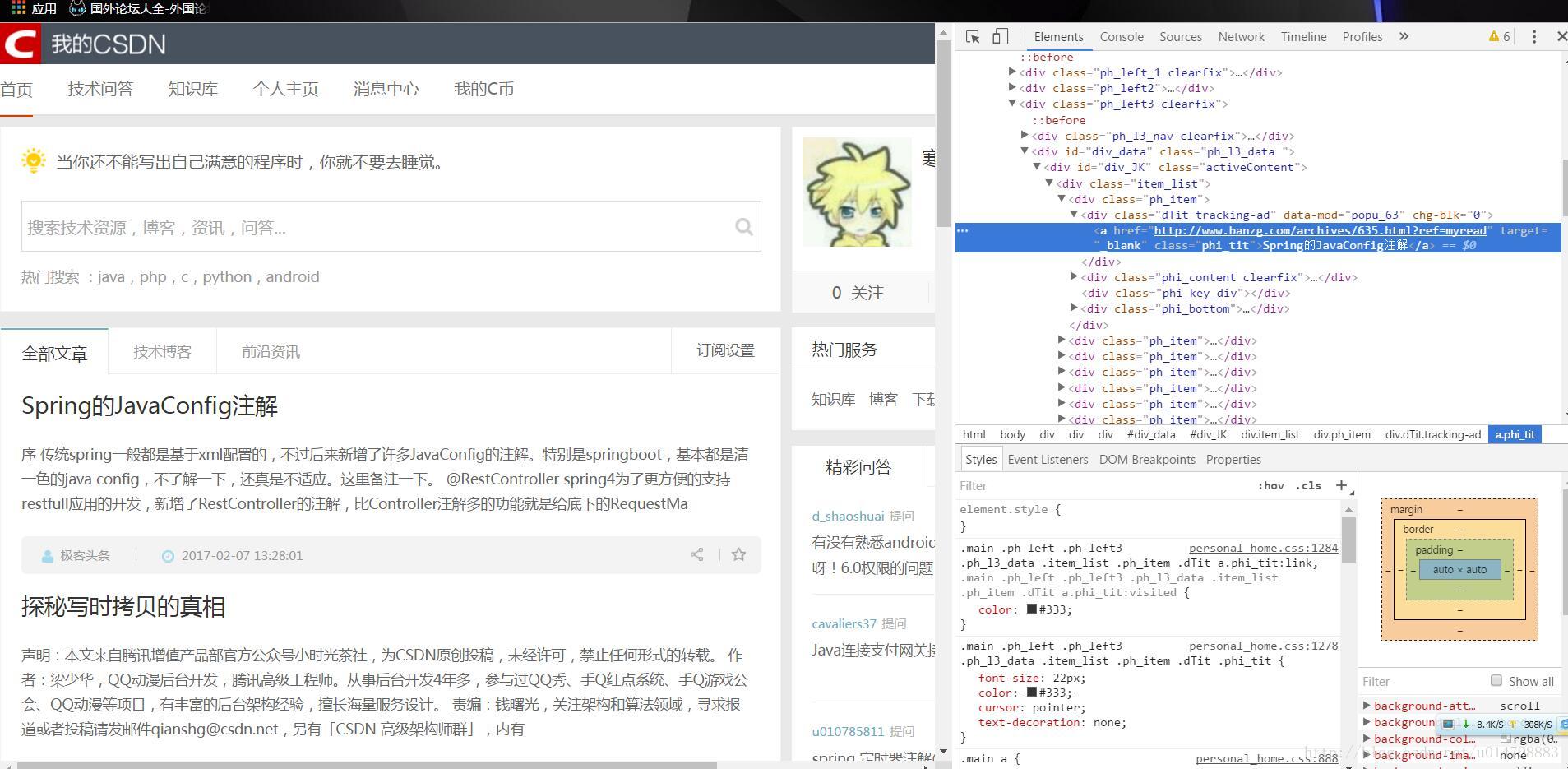
1.打开谷歌浏览器,右键单机想要抓取的元素,比如我右击了“Spring的JavaConfig注解这篇文章”选择检查,自动跳出源码框,并且定位到右键的元素的位置。
2.右键点击代码行,copy–>copy selector

3.这时候我们可以贴出来看看copy到的东西:
- 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









