






文章目录
0. 前言
-
本文内容主要参考自https://www.w3cschool.cn/apache_kafka/apache_kafka_fundamentals.html,并根据个人理解对内容进行了扩充和整理。
-
本文聚焦于 Kafka 的基础知识,旨在梳理其整体架构与核心概念,不涉及具体的技术细节与实现原理。后续将通过系列文章进一步展开 Kafka 的各个模块与使用实践,逐步构建完整的知识体系。
1. Kafka 简介
Kafka 是一个 分布式流处理平台(Distributed Streaming Platform),用于处理海量的实时数据流,被广泛应用于 日志收集、事件驱动架构、流式处理、数据管道 等场景中。
虽然 Kafka 本质上是一个流处理平台,但在实际使用中,它也常被作为一个 高吞吐、分布式、可持久化的消息队列系统,是现代数据架构中的核心基础设施。
Kafka 基于 发布-订阅模式(Pub/Sub) 构建,具有传统消息队列系统所不具备的性能优势。与 RabbitMQ、ActiveMQ 等传统消息中间件相比,Kafka 在 吞吐量、扩展性、持久化能力 等方面表现更加出色。
Kafka的核心特性:
- 高吞吐:支持每秒百万级消息传输,适用于大规模实时数据处理场景。
- 分布式架构:支持多节点集群部署,具备良好的扩展性和容错能力。
- 持久化存储:消息写入磁盘,可设置保留时间,实现“可回溯”消费。
- 生产与消费解耦:生产者和消费者之间无直接依赖,系统更加灵活。
- 消费灵活:支持单播和广播消费(通过 Consumer Group 实现负载均衡)。
凭借上述特性,Kafka 在众多场景中发挥着重要作用,例如:
- 日志收集与分析:将各系统产生的日志实时采集到 Kafka,通过 Hadoop 等系统进行统一处理与分析。
- 实时监控系统:监控指标、报警信息通过 Kafka 实时传输,支撑可视化和告警服务。
- 用户行为追踪:采集网站或 App 的用户行为数据,实现用户画像、推荐系统等分析。
- 数据管道构建:作为数据总线,连接数据库、数据仓库、消息服务,实现不同系统间的数据流转。
- 流式计算平台:结合 Kafka Streams、Flink 等工具进行数据实时计算与处理。
注:消息队列的三个主要作用:
- 异步处理:生产者将任务发送到队列,消费者异步消费,提升系统响应速度和并发能力。
- 系统解耦:生产者和消费者无需直接通信,通过消息队列解耦,降低系统耦合度,便于独立维护和扩展。
- 削峰填谷:在流量高峰期,消息队列可以缓冲大量请求,平滑峰值压力,防止后端服务过载。
2. Kafka 架构介绍
Kafka 的架构由多个关键组件协同工作构成。下图展示了 Kafka 的整体架构,而下表则简要介绍了各核心组件的作用和工作机制:
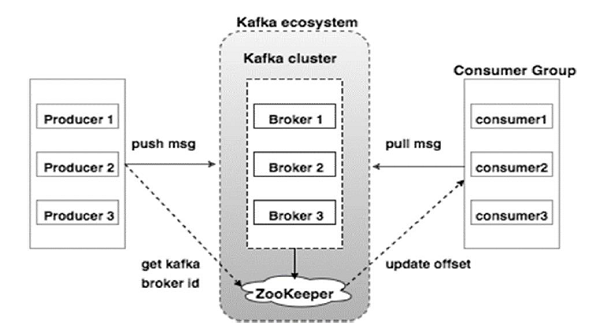
图 1:Kafka架构图(图源自 Apache kafka中文手册)
| 组件 | 描述 |
|---|---|
| Broker(代理) | Kafka 集群由多个 Broker 节点组成,每个 Broker 接收和存储消息,并处理来自生产者和消费者的请求。Broker 是无状态的,集群状态由 ZooKeeper 管理。每个 Broker 可以处理海量消息,具有极高的吞吐能力。 |
| ZooKeeper | 用于管理 Kafka 集群的元数据,负责 Broker 的注册、状态监控以及选举控制器等。它为 Kafka 提供分布式协调机制,是 Kafka 运作的基础组件之一(Kafka 2.8 开始可选)。 |
| Producer(生产者) | 生产者负责将消息发送到 Kafka 指定的 Topic。它们感知集群中新的 Broker 并自动路由消息,通常是异步发送,以提高性能和吞吐量。 |
| Consumer(消费者) | 消费者从 Topic 中拉取消息进行处理。由于 Broker 不存储消费状态,消费者通过偏移量(offset)来记录自己的消费进度,并可控制从哪个位置开始消费。 |
注:在 Kafka 的新版本中(从 2.8 开始),Kafka 引入了“无 ZooKeeper 模式”(KRaft),逐步减少对 ZooKeeper 的依赖,但传统架构中 ZooKeeper 仍是核心组成部分。
3. 核心概念介绍
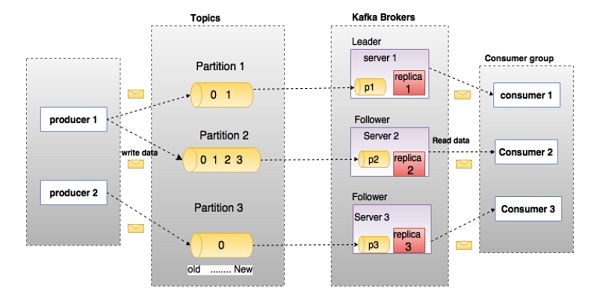
图 2:Kafka核心组件图(图源自 Apache kafka中文手册)
Kafka 的架构中包含多个关键概念,理解这些概念有助于掌握 Kafka 的运行机制和设计哲学。
-
Topic(主题)
Kafka 中消息按主题分类。每类消息流属于一个 Topic,生产者将消息发布到某个 Topic,消费者订阅后即可消费。 -
Partition(分区)
为了实现并发与扩展性,每个 Topic 可以被拆分为多个 Partition,每个 Partition 是一个有序、可追加的消息队列。 -
Offset(偏移量)
每条消息在其所属分区中都有一个唯一的偏移量(Offset),用于标识消息在分区中的位置。消费者依靠偏移量来追踪消费进度。 -
Replica(副本)
Kafka 通过为分区设置副本(Replica)实现容错。每个分区有一个 Leader 和多个 Follower,Follower 从 Leader 同步数据,在 Leader 故障时接替其工作。 -
Broker(代理)
Kafka 集群中的服务器节点称为 Broker,负责存储消息并响应 Producer 和 Consumer 的请求。一个 Broker 可管理多个分区。 -
Kafka Cluster(Kafka 集群)
多个 Broker 组成 Kafka 集群,支持动态扩容与高可用部署,Kafka 的水平扩展能力非常强。 -
Producer(生产者)
生产者将消息发布到 Kafka 的某个 Topic 中。生产者可自定义消息分区策略,或使用默认轮询策略进行分发。 -
Consumer(消费者)
消费者从 Topic 中订阅消息进行处理。消费者可通过手动或自动提交 offset 实现消费进度管理。 -
Consumer Group(消费者组)
多个消费者可组成一个 Consumer Group,实现对 Topic 的分区并发消费。每个分区同一时刻只能被组内一个消费者处理,实现负载均衡。 -
Leader / Follower
每个分区都有一个 Leader 负责处理所有读写请求,其他副本作为 Follower 与 Leader 保持同步。在 Leader 异常时,由 Kafka 自动从 Follower 中选举新的 Leader。 -
Controller(控制器)(可选)
Kafka 集群中有一个 Broker 被选为控制器,负责分区 Leader 的选举、分区变更的协调等元数据管理工作。
4. Kafka消息传递流程
[Producer] → [Broker (Partition Leader)] → [Segment File (磁盘持久化)] → [Follower Replica 同步] → [Consumer Group 拉取消费]
Kafka 的消息传递流程主要包括以下几个步骤:
- 生产者(Producer)发送消息到 Kafka 主题(Topic)
- Kafka Broker 接收消息并写入对应的分区(Partition)
- 消息被持久化到磁盘(Segment 文件)
- 消费者(Consumer)从分区中拉取消息(Pull)进行消费
4.1 Producer 发送消息
- Producer 通过 Kafka 客户端 API 构造消息,并将消息发送至指定的 Topic。
- Producer 可自定义 分区策略,决定消息应该被写入哪个 Partition。常用策略包括:
- 轮询(Round Robin,默认)
- 基于 Key 的哈希分区(如:
key % partition_num) - 自定义分区器(实现
Partitioner接口)
4.2 Broker 接收并写入消息
- Kafka Broker 接收到消息后,会将消息追加写入目标 Partition 的 segment 文件中。
- Kafka 使用顺序写入磁盘的方式,结合页缓存机制,保证 高吞吐 + 持久化。
- 同时,消息也会被复制到该分区的 Follower 副本中,确保高可用。
4.3 消息持久化机制
- Kafka 每个分区对应一组 segment 日志文件,消息被追加写入这些文件中。
- Kafka 会周期性地将内存中的消息刷新到磁盘,确保消息不会丢失。
- 每条消息在 Kafka 中包含:
offset:分区内的唯一序号timestamp:消息时间戳key/value:消息键值对内容
4.4 Consumer 拉取消息
- Kafka 的消费模型是 拉模式(pull-based),消费者主动向 Broker 发起拉取请求。
- 消费者会记录自己的 消费位移(offset),可以通过:
- 自动提交(默认)
- 手动提交(灵活控制处理/提交流程)
4.5 多消费者与负载均衡
- 多个消费者可以组成一个 Consumer Group:
- 每个分区只能被同一组中的一个消费者消费,确保并发 & 去重。
- 当有新的消费者加入/离开组时,Kafka 会进行 Rebalance 重新分配分区。
4.6 消息确认与容错
- Kafka 支持 “至少一次” 投递语义,确保消息不会丢失,但可能重复。
- 可通过
acks参数设置 Producer 的确认策略:acks=0:不等待确认,最快但可能丢失消息。acks=1:只需 Leader 写入成功,平衡效率与可靠性。acks=all:等待所有副本写入成功,最安全但延迟高。
- 可结合幂等生产(Idempotent Producer)和事务机制,支持更强一致性保障。
5. Kafka 消息传递常见注意事项
-
一条消息只能发送到一个 Topic
- 每条 Kafka 消息必须明确指定目标 Topic。
- 若需要发送到多个 Topic,需要分别发送多次。
- Kafka 并不支持一条消息同时广播到多个 Topic。
-
消息只能写入 Topic 中的某一个分区
- 同一条消息不会同时写入多个分区。
- 分区的选择方式通常有三种:
- 显式指定分区;
- 提供 Key,通过哈希分配到某一分区(用于确保不同消息写入同一分区);
- 无 Key 时轮询方式随机分配。
- 分区是 Kafka 并行处理的基本单位。
-
分区数影响吞吐量与可扩展性
- 分区越多,Kafka 的并发度越高。
- 但过多的分区会增加资源开销(如文件句柄、网络连接等)。
- 建议在创建 Topic 时合理预估所需分区数量。
-
生产者与集群交互,无需关心具体 Broker
- Kafka Producer 通过集群元数据决定消息目标分区。
- Producer 不需要知道每个消息被发送到哪个 Broker,Kafka 自动路由。
-
每个分区都有多个副本,Kafka 自动完成 Leader 选举
- Kafka 通过 副本机制 实现高可用性:每个分区可以有一个主副本(Leader)和多个从副本(Follower)。
- Leader 负责处理所有的读写请求,Follower 被动同步 Leader 的数据。
- Kafka 会通过内部机制(依赖 ZooKeeper 或 KRaft)自动进行 Leader 选举与副本切换,开发者无需手动干预。
- 当 Leader 发生故障,Kafka 会自动从 ISR(In-Sync Replica,同步副本集合)中选举新的 Leader,保障服务连续性。
-
Kafka消费者必须属于某个消费者组
- Kafka 使用消费者组实现分区的负载均衡和消费进度管理。
- 虽然技术上消费者可以不指定组ID,但客户端会自动为其生成临时组ID,实际效果类似独立消费者,无法共享进度和实现扩展。
- 所以,强烈建议在使用时明确指定消费者组,方便管理和扩展。
-
消息偏移量是针对消费者组管理的
- Kafka 的偏移量(offset)是针对消费者组维度进行管理的。
- 即:每个消费者组在每个分区中都有自己的一份消费进度,彼此之间互不干扰。
- 示例:如果有两个消费者组(如
group-A和group-B),即使它们订阅了同一个 Topic,它们也可以独立消费同一条消息,因为各自维护独立的 offset。 - Kafka 将 offset 存储在
__consumer_offsets这个内部 Topic 中,支持自动提交(enable.auto.commit=true)或手动提交(推荐在消费逻辑成功之后再提交)。
-
Kafka 中的消息不会因消费而被删除,具备持久性
- 与传统消息队列不同,Kafka 是 日志型存储结构,消息被消费后仍然保留在磁盘中,直到超过设定的保留时间(retention)或超出日志大小限制。
- 这意味着:
- 多个消费者组可以独立消费同一份数据,互不影响。
- 消费者可以基于偏移量从任意位置重新读取消息,方便数据重放与容错处理。
- Kafka 的这种机制支持 “消息回溯”、“重复消费” 和 “批量数据处理” 场景,是其用于数据管道与流处理系统的基础。
✅ 注意事项补充:
- Kafka 并不追踪“谁消费了什么”,它只负责将消息按顺序写入日志中;
- 消费状态由消费者自己维护(例如通过偏移量);
- 持久化和解耦是 Kafka 能胜任大数据场景的根本原因之一。
-
同一个消费者组中,每个分区只能被一个消费者实例消费
- Kafka 使用“每组每分区一个消费者”的消费模型,保证数据处理顺序与幂等性。
- 如果消费者实例多于分区数量,有的消费者将处于空闲状态。
-
Producer 支持不同级别的可靠性配置(acks)
acks=0:不等待确认,吞吐高但可能丢消息。acks=1:Leader Broker 确认写入即可,性能与可靠性平衡。acks=all:所有副本确认后返回,最安全但延迟较高。- 配合幂等生产者(
enable.idempotence=true)可避免重复消息。
- Kafka 默认是“至少一次”语义
- 消息可能重复但不会丢失。
- 若需要实现“精准一次”(Exactly Once)语义,需开启幂等 + 事务支持,并在应用层妥善处理。
6. 总结
本文介绍了 Kafka 的基础知识,帮助读者建立对 Kafka 的整体认识。
- Kafka 是一个分布式流处理平台,同时也是一个高吞吐、可持久化的消息队列系统,广泛应用于日志收集、实时数据管道和流式处理等场景。
- 通过多节点的 Broker 组成集群,配合 ZooKeeper 或 KRaft 实现集群管理与协调,保证系统的高可用性和扩展性。
- 核心概念包括主题、分区、消息偏移、副本机制、Leader、Follower、生产者、消费者和消费者组等,这些构成了 Kafka 高效可靠的数据传递基础。
- Kafka 的消息传递流程涉及生产者将消息发送到指定分区,Broker 负责存储并同步副本,消费者从分区中按偏移量读取消息,实现灵活的消费模式。
- Kafka 与传统消息队列的不同之处在于消息持久化保留,支持多消费者组独立消费和消息回溯,具备强大的容错和可扩展能力。
- 消费者组机制实现了分区的负载均衡和消费状态管理,确保消息处理的顺序性和幂等性。
- Kafka 通过副本和自动 Leader 选举机制保障系统的高可用性,降低单点故障风险。
后续文章将探讨 Kafka 的深入使用等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









