







前述
kafka的运行依赖于zooKeeper,所以在搭建kafka的环境之前需要搭建zookeeper环境。
zooKeeper:
ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,可以保证数据在集群间的事务一致性,提供的功能包括:配置维护、命名服务、分布式同步、组服务等。
1、zookeeper安装
zookeeper安装:KAFKA环境搭建_Zx-Deere的博客-CSDN博客_kafka环境搭建
查看进程: 方法: ps -aux | grep 'zookeeper' 系统有返回,说明zookeeper启动
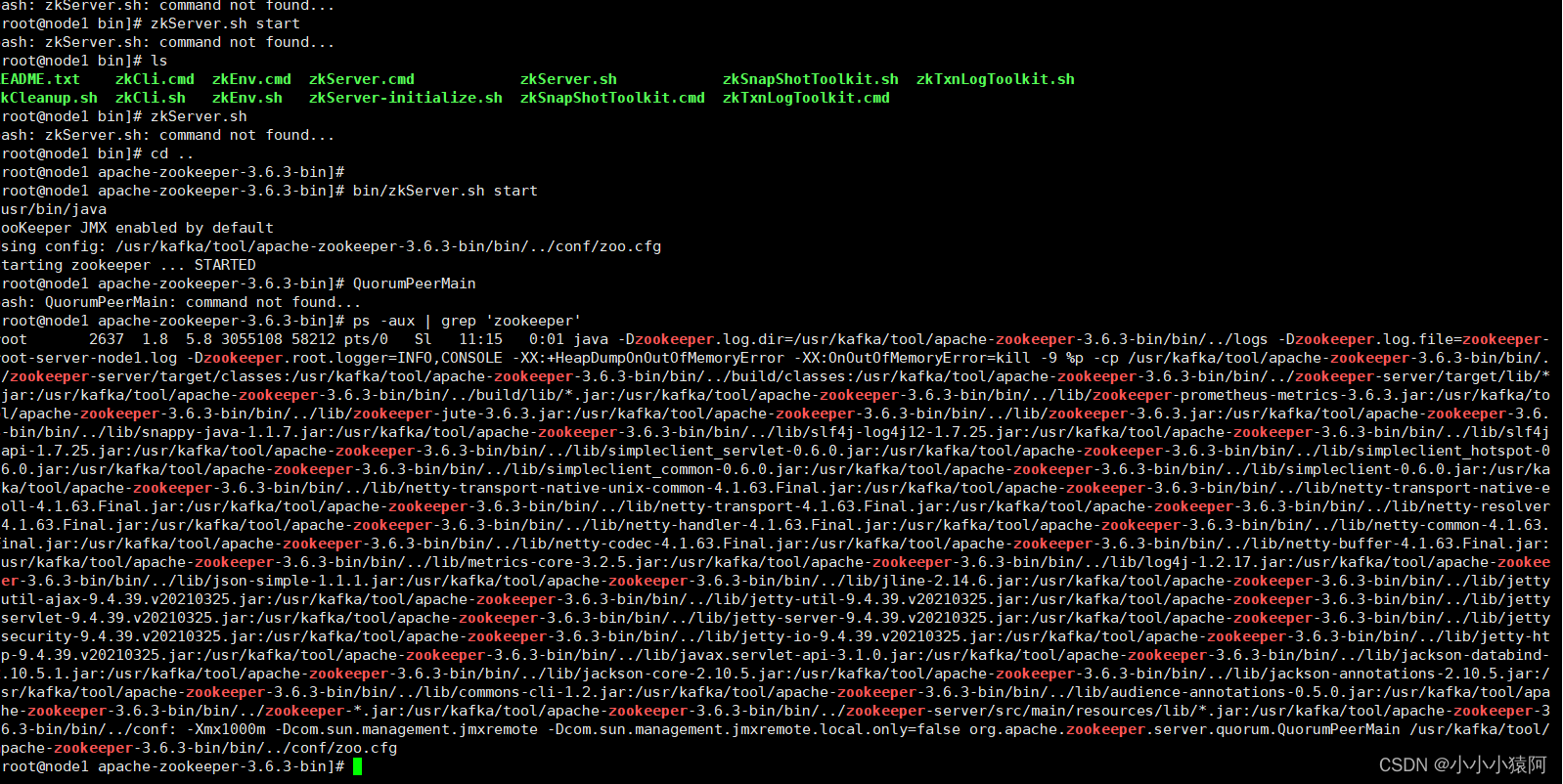
2、kafka安装
- 准备工作
(1)下载:Apache Kafka
注意:下载的版本为Binary 不是Source
(2)安装jdk
- 解压kafka
- 修改配置文件server.properties
#broker.id属性在kafka集群中必须要是唯⼀
broker.id=0
#kafka部署的机器ip和提供服务的端⼝号
listeners=PLAINTEXT://192.168.65.60:9092
#kafka的消息存储⽂件
log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect=192.168.65.60:218- 启动kafka服务
进入到bin目录,执行以下启动语句
./kafka-server-start.sh -daemon ../config/server.properties
- 查看kafka是否启动成功
执行以下语句
ps -aux | grep server.properties
- 关闭kafka服务
找到kafka进程号:ps -aux | grep server.properties
杀死该进程:kill xxx
3、通过kafka内部指令简单操作kafka
- 创建topic
(1)通过在zookeeper中存储topic(低版本kafka)
./kafka-topics.sh --create --zookeeper 172.16.253.35:2181 --replicationfactor 1 --partitions 1 --topic test_demo
(2)在kafka内部存储topic
./kafka-topics.sh --create --topic test_demo --bootstrap-server 192.168.217.131:9092
(3)查询topic列表
./kafka-topics.sh --bootstrap-server 192.168.217.131:9092 --list
(4)查询topic详情
./kafka-topics.sh --bootstrap-server 192.168.217.131:9092 --topic test_demo --describe
- 生产消息
./kafka-console-producer.sh --bootstrap-server 192.168.217.131:9092 --topic test_demo
- 消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.217.131:9092 --topic test_demo
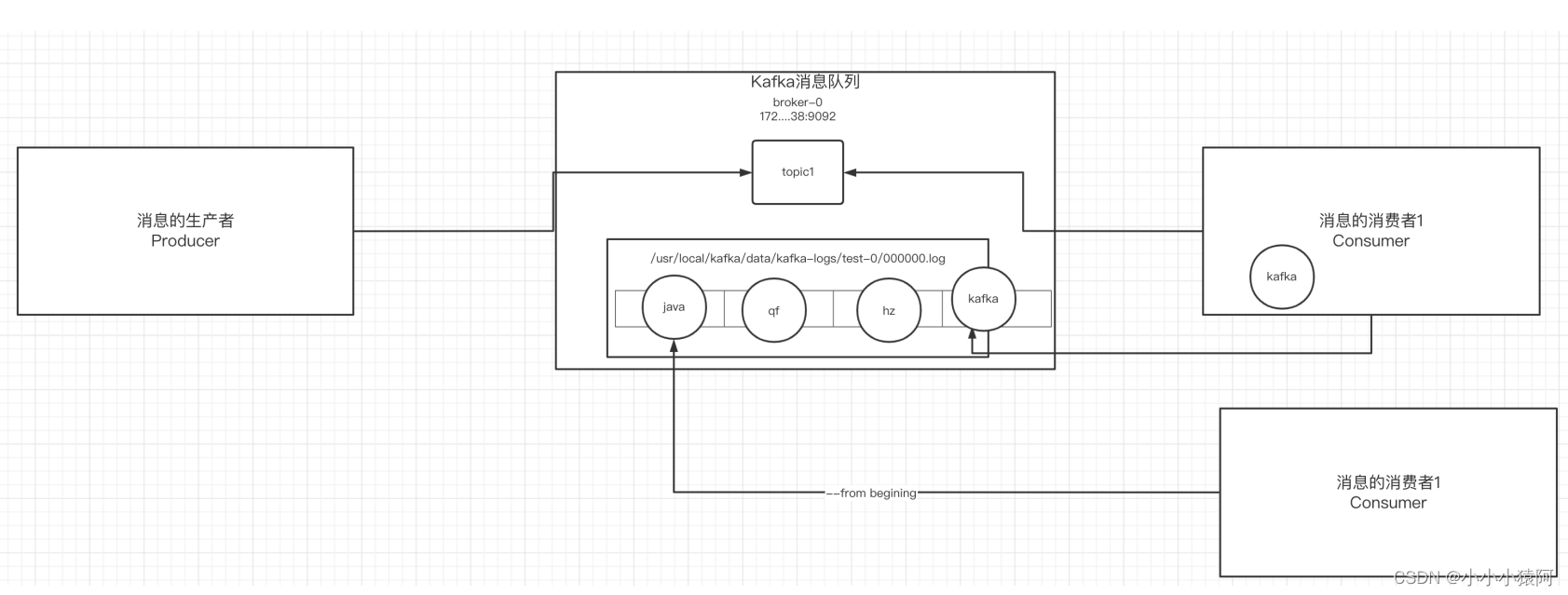
关于消息:
- 生产者发送消息到broker,broker保存消息到本地的日志文件中(路径在配置文件中配置)
- 消息的保存是有序的,通过偏移量offset来描述消息的顺序
- 消费消息时也是通过偏移量offset来指定所需要消费的位置的消息
4、单播消息和多播消息
(1)单播消息
同一个消费组内,只有一个消费者可以消费同一个topic的消息
./kafka-console-consumer.sh --bootstrap-server 192.168.217.131:9092 --
consumer-property group.id=testGroup --topic test(2)多播消息
不同消费组内,每个组内容的消费者可以消费同一个toppic的消息
./kafka-console-consumer.sh --bootstrap-server 192.168.217.131:9092 --
consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 192.168.217.131:9092 --
consumer-property group.id=testGroup2 --topic test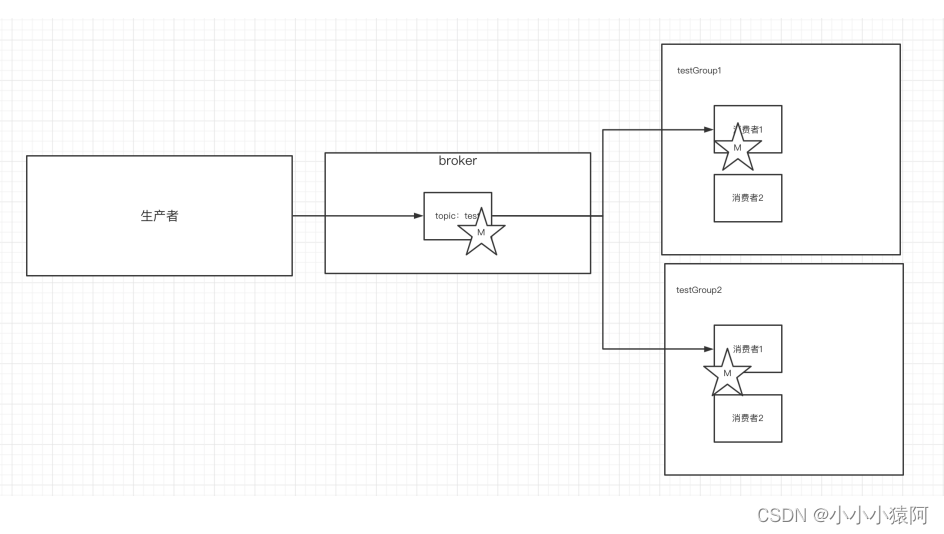
5、查看消费者组信息
./kafka-consumer-groups.sh --bootstrap-server 192.168.217.131:9092 -- describe --group testGroup
![]()
重点关注以下⼏个信息:
current-offset: 最后被消费的消息的偏移量
Log-end-offset: 消息总量(最后⼀条消息的偏移量)
Lag:积压了多少条消息
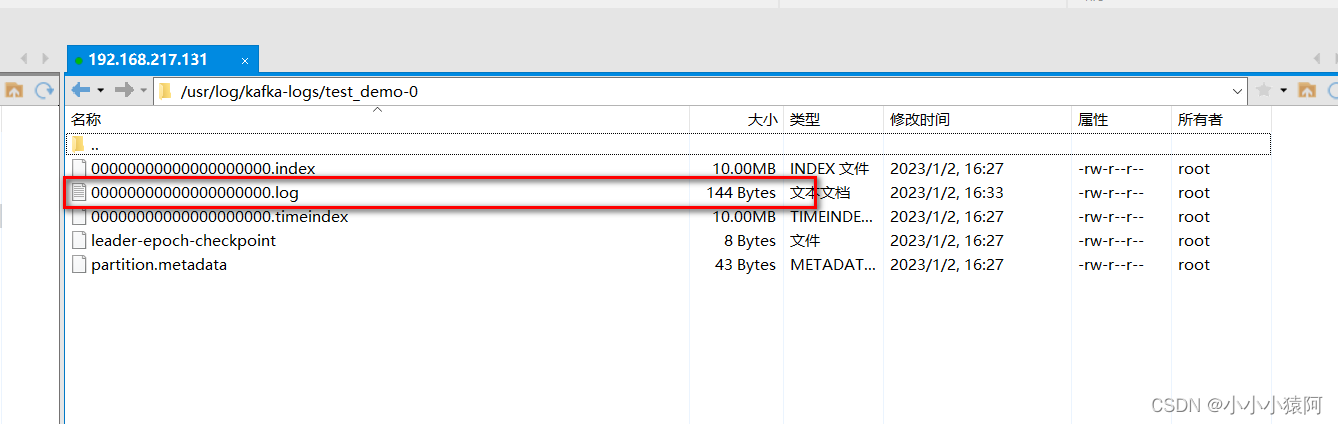
6、kafka中消息⽇志⽂件中保存的内容
- 00000.log:kafka中消息⽇志⽂件中保存的内容
- __consumer_offsets0~49
kafka内部⾃⼰创建了__consumer_offsets主题包含了50个分区。这个主题⽤来存放消费 者消费某个主题的偏移量。因为每个消费者都会⾃⼰维护着消费的主题的偏移量,也就是 说每个消费者会把消费的主题的偏移量⾃主上报给kafka中的默认主题: consumer_offsets。因此kafka为了提升这个主题的并发性,默认设置了50个分区。
- 提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets 主题的分区数
- 提交到该主题中的内容是:key是consumerGroupId+topic+分区号,value就是当前 offset的值















 3907
3907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









