







JavaScript 的闭包原理与详解。
JavaScript的闭包是一个特色,但也是很多新手难以理解的地方,阅读过不少大作,对闭包讲解不一,个人以为,在《JavaScript高级程序设计》一书中,解释的最为详尽,结合此书,表述一下我对JavaScript闭包的理解,希望能对新手有些帮助。
闭包的例子
var count=10;//全局作用域 标记为flag1
function add(){
var count=0;//函数全局作用域 标记为flag2
return function(){
count+=1;//函数的内部作用域
alert(count);
}
}
var s=add()
s();//输出1
s();//输出2来看一下发生了什么吧,add()的返回值是一个函数,首先第一次调用s()的时候,是执行add()的返回的函数,也就是下面这个函数:
function(){
count+=1;//函数的内部作用域
alert(count);
}也就是将count+1,在输出,那count是从哪儿来的的呢,根据作用域链的规则,底层作用域没有声明的变量,会向上一级找,找到就返回,没找到就一直找,直到window的变量,没有就返回undefined。这里明显count 是函数内部的flag2 的那个count ,
var count=10;//全局作用域
function add(){
//var count=0;注释掉了
return function(){
count+=1;//函数的内部作用域
alert(count);
}
}
var s=add()
s();//输出11
s();//输出12自然这是体现不出闭包的性质,只为了说明函数作用域链 继续说明:第一次执行,是没有疑问的输出1,那第二次的过程是怎样的呢? 继续执行那个函数的返回的方法,还是count+=1;然后再输出count ,这里问题就来了,不应该继续向上寻找,找到count=0;然后输出1吗?不知道有没有注意一个问题,那就是s()执行的是下面这个函数
function(){
count+=1;//函数的内部作用域
alert(count);
}function add(){
var count=0;//函数全局作用域 标记为flag2
return function(){
count+=1;//函数的内部作用域
alert(count);
}
}也就是说add(),只被执行了一次。然后执行两次s(),那count的值就是只声明了一次。
var s=add(),函数add 只在这里执行了一次。
下面执行的都是s(),那第二次的count的值是从哪儿来的,没错它还是第一次执行add时,留下来的那个变量。
(这怎么可能,函数变量执行完就会被释放啊,为什么还在?这里就是一个垃圾回收机制的引用计数问题)。
“”如果一个变量的引用不为0,那么他不会被垃圾回收机制回收,引用,就是被调用“”。
由于再次执行s()的时候,再次引用了第一次add()产生的变量count ,所以count没有被释放,第一次s(),count 的值为1,第二次执行s(),count的值再加1,自然就是2了。
让我们返回来再看看,根据以上所说,如果执行两次add() ,那就应该输出 都是1,来改一下这个函数
function add(){
var count=0;//函数全局作用域
return function(){
count+=1;//函数的内部作用域
alert(count);
}
}
add()();//输出1
add()();//输出1<p>1</p><p>2</p><p>3</p>
<p>4</p><p>5</p><p>6</p>
var plist=document.getElementsByTagName('p');
for (var i=0;i<plist.length;i++) {
plist[i].onclick=function(){
alert(plist[i].innerHTML)//全是undefined
}
}
总结一下
JavaScript闭包的形成原理是基于函数变量作用域链的规则 和 垃圾回收机制的引用计数规则。
JavaScript闭包的本质是内存泄漏,指定内存不释放。
(不过根据内存泄漏的定义是无法使用,无法回收来说,这不是内存泄漏,由于只是无法回收,但是可以使用,为了使用,不让系统回收)
JavaScript闭包的用处,私有变量,获取对应值等,。。
下面这些是引用自原书的原文,有兴趣的朋友可以读一下,加深理解。有关于作用域链和引用计数的问题也有说明。
以下内容引用自《JavaScript高级程序设计》
执行环境及作用域
念。执行环境定义了变量或函数有权访问的其他数据,决定了它们各自的行为。每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有变量和函数都保存在这个对象中。虽然我们编写的代码无法访问这个对象,但解析器在处理数据时会在后台使用它。 全局执行环境是最外围的一个执行环境。根据 ECMAScript 实现所在的宿主环境不同,表示执行环境的对象也不一样。在 Web 浏览器中,全局执行环境被认为是 window 对象(第 7 章将详细讨论),因此所有全局变量和函数都是作为 window 对象的属性和方法创建的。某个执行环境中的所有代码执行完毕后,该环境被销毁,保存在其中的所有变量和函数定义也随之销毁(全局执行环境直到应用程序退出——例如关闭网页或浏览器——时才会被销毁)。 每个函数都有自己的执行环境。当执行流进入一个函数时,函数的环境就会被推入一个环境栈中。而在函数执行之后,栈将其环境弹出,把控制权返回给之前的执行环境ECMAScript 程序中的执行流正是由这个方便的机制控制着。 当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain)。作用域链的用途,是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链的前端,始终都是当前执行的代码所在环境的变量对象。如果这个环境是函数,则将其活动对象(activation object)作为变量对象。活动对象在最开始时只包含一个变量,即 arguments 对象(这个对象在全局环境中是不存在的)。作用域链中的下一个变量对象来自包含(外部)环境,而再下一个变量对象则来自下一个包含环境。这样,一直延续到全局执行环境;全局执行环境的变量对象始终都是作用域链中的最后一个对象。 标识符解析是沿着作用域链一级一级地搜索标识符的过程。搜索过程始终从作用域链的前端开始,然后逐级地向后回溯,直至找到标识符为止(如果找不到标识符,通常会导致错误发生)。请看下面的示例代码:
var color = "blue";
function changeColor(){
if (color === "blue"){
color = "red";
} else {
color = "blue";
}
}
changeColor();
alert("Color is now " + color);在这个简单的例子中,函数 changeColor()的作用域链包含两个对象:它自己的变量对象(其中定义着 arguments 对象)和全局环境的变量对象。可以在函数内部访问变量 color,就是因为可以在这个作用域链中找到它。 此外,在局部作用域中定义的变量可以在局部环境中与全局变量互换使用,如下面这个例子所示:
var color = "blue";
function changeColor(){
var anotherColor = "red";
function swapColors(){
var tempColor = anotherColor;
anotherColor = color;
color = tempColor;
// 这里可以访问 color、anotherColor 和 tempColor
}
// 这里可以访问 color 和 anotherColor,但不能访问 tempColor
swapColors();
}
// 这里只能访问 color
changeColor();以上代码共涉及 3 个执行环境: 全局环境、changeColor()的局部环境和 swapColors()的局部环境。全局环境中有一个变量 color 和一个函数 changeColor()。changeColor()的局部环境中有一个名为 anotherColor 的变量和一个名为 swapColors()的函数,但它也可以访问全局环境中的变量 color。swapColors()的局部环境中有一个变量 tempColor,该变量只能在这个环境中访问到。 无论全局环境还是 changeColor()的局部环境都无权访问 tempColor。然而,在 swapColors()内部则可以访问其他两个环境中的所有变量,因为那两个环境是它的父执行环境。图 4-3 形象地展示了前面这个例子的作用域链。 图 4-3
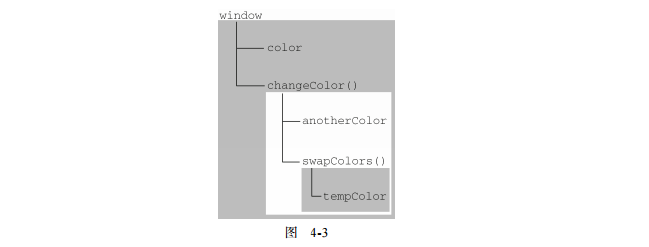
图 4-3 中的矩形表示特定的执行环境。其中,内部环境可以通过作用域链访问所有的外部环境,但外部环境不能访问内部环境中的任何变量和函数。这些环境之间的联系是线性、有次序的。每个环境都可以向上搜索作用域链,以查询变量和函数名;但任何环境都不能通过向下搜索作用域链而进入另一个执行环境。对于这个例子中的 swapColors()而言,其作用域链中包含 3 个对象:swapColors()的变量对象、changeColor()的变量对象和全局变量对象。swapColors()的局部环境开始时会先在自己的变量对象中搜索变量和函数名,如果搜索不到则再搜索上一级作用域链。changeColor()的作用域链中只包含两个对象:它自己的变量对象和全局变量对象。这也就是说,它不能访问 swapColors()的 环境。———-
JavaScript的垃圾回收机制和引用计数规则
垃圾收集JavaScript 具有自动垃圾收集机制,也就是说,执行环境会负责管理代码执行过程中使用的内存。而在 C 和 C++之类的语言中,开发人员的一项基本任务就是手工跟踪内存的使用情况,这是造成许多问题的一个根源。在编写 JavaScript 程序时,开发人员不用再关心内存使用问题,所需内存的分配以及无用内存的回收完全实现了自动管理。这种垃圾收集机制的原理其实很简单:找出那些不再继续使用的变量,然后释放其占用的内存。为此,垃圾收集器会按照固定的时间间隔(或代码执行中预定的收集时间),周期性地执行这一操作。下面我们来分析一下函数中局部变量的正常生命周期。局部变量只在函数执行的过程中存在。而在这个过程中,会为局部变量在栈(或堆)内存上分配相应的空间,以便存储它们的值。然后在函数中使用这些变量,直至函数执行结束。此时,局部变量就没有存在的必要了,因此可以释放它们的内存以供将来使用。在这种情况下,很容易判断变量是否还有存在的必要;但并非所有情况下都这么容易就能得出结论。垃圾收集器必须跟踪哪个变量有用哪个变量没用,对于不再有用的变量打上标记,以备将来收回其占用的内存。用于标识无用变量的策略可能会因实现而异,但具体到浏览器中的实现,则通常有两 个策略。
标记清除
JavaScript 中最常用的垃圾收集方式是标记清除(mark-and-sweep)。当变量进入环境(例如,在函数中声明一个变量)时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。可以使用任何方式来标记变量。比如,可以通过翻转某个特殊的位来记录一个变量何时进入环境,或者使用一个“进入环境的”变量列表及一个“离开环境的”变量列表来跟踪哪个变量发生了变化。说到底,如何标记变量其实并不重要,关键在于采取什么策略。垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记(当然,可以使用任何标记方式)。然后,它会去掉环境中的变量以及被环境中的变量引用的变量的标记。而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后,垃圾收集器完成内存清除工作,销毁那些带标记的值并回收它们所占用的内存空间。
引用计数
另一种不太常见的垃圾收集策略叫做引用计数(reference counting)。引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型值赋给该变量时,则这个值的引用次数就是 1。如果同一个值又被赋给另一个变量,则该值的引用次数加 1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数变成 0 时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。这样,当垃圾收集器下次再运行时,它就会释放那些引用次数为零的值所占用的内存。Netscape Navigator 3.0 是最早使用引用计数策略的浏览器,但很快它就遇到了一个严重的问题:循环引用。循环引用指的是对象 A 中包含一个指向对象 B 的指针,而对象 B 中也包含一个指向对象 A 的引用。请看下面这个例子:
function problem(){
var objectA = new Object();
var objectB = new Object();
objectA.someOtherObject = objectB;
objectB.anotherObject = objectA;
}在这个例子中,objectA 和 objectB 通过各自的属性相互引用;也就是说,这两个对象的引用次数都是 2。在采用标记清除策略的实现中,由于函数执行之后,这两个对象都离开了作用域,因此这种相互引用不是个问题。但在采用引用计数策略的实现中,当函数执行完毕后,objectA 和 objectB 还将继续存在,因为它们的引用次数永远不会是 0。假如这个函数被重复多次调用,就会导致大量内存得不到回收。为此,Netscape 在 Navigator 4.0 中放弃了引用计数方式,转而采用标记清除来实现其垃圾收集机制。可是,引用计数导致的麻烦并未就此终结。我们知道,IE 中有一部分对象并不是原生 JavaScript 对象。例如,其 BOM 和 DOM 中的对象就是使用 C++以 COM(Component Object Model,组件对象模型)对象的形式实现的,而 COM 对象的垃圾收集机制采用的就是引用计数策略。因此,即使 IE 的 JavaScript 引擎是使用标记清除策略来实现的,但JavaScript 访问的 COM 对象依然是基于引用计数策略的。换句话说,只要在 IE 中涉及 COM 对象,就会存在循环引用的问题。下面这个简单的例子,展示了使用 COM 对象导致的循环引用问题:
var element = document.getElementById("some_element");
var myObject = new Object();
myObject.element = element;
element.someObject = myObject;这个例子在一个 DOM 元素(element)与一个原生 JavaScript 对象(myObject)之间创建了循环引用。其中,变量 myObject 有一个名为 element 的属性指向 element 对象;而变量 element 也有一个属性名叫 someObject 回指 myObject。由于存在这个循环引用,即使将例子中的 DOM 从页面中移除,它也永远不会被回收。为了避免类似这样的循环引用问题,最好是在不使用它们的时候手工断开原生 JavaScript 对象与DOM 元素之间的连接。例如,可以使用下面的代码消除前面例子创建的循环引用:
myObject.element = null;
element.someObject = null;
将变量设置为 null 意味着切断变量与它此前引用的值之间的连接。当垃圾收集器下次运行时,就会删除这些值并回收它们占用的内存。为了解决上述问题,IE9 把 BOM 和 DOM 对象都转换成了真正的 JavaScript 对象。这样,就避免了两种垃圾收集算法并存导致的问题,也消除了常见的内存泄漏现象。















 6515
6515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









