







 本文详细介绍Filebeat作为轻量级日志采集工具的核心功能、结构原理及其配置实践。Filebeat能够有效监视并采集日志文件,支持多种输出组件如Elasticsearch、Logstash和Kafka。
本文详细介绍Filebeat作为轻量级日志采集工具的核心功能、结构原理及其配置实践。Filebeat能够有效监视并采集日志文件,支持多种输出组件如Elasticsearch、Logstash和Kafka。
目录
官网:https://www.elastic.co/cn/beats/filebeat
官方博文:https://blog.csdn.net/ubuntutouch/category_9346710.html
filebeat概述
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash或kafka进行索引。
filebeat和beats的关系
首先filebeat是Beats中的一员。
Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
目前Beats包含六种工具:
- Packetbeat:网络数据(收集网络流量数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat:日志文件(收集文件数据)
- Winlogbeat:windows事件日志(收集Windows事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)
filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder,就是filebeat。
filebeat结构原理
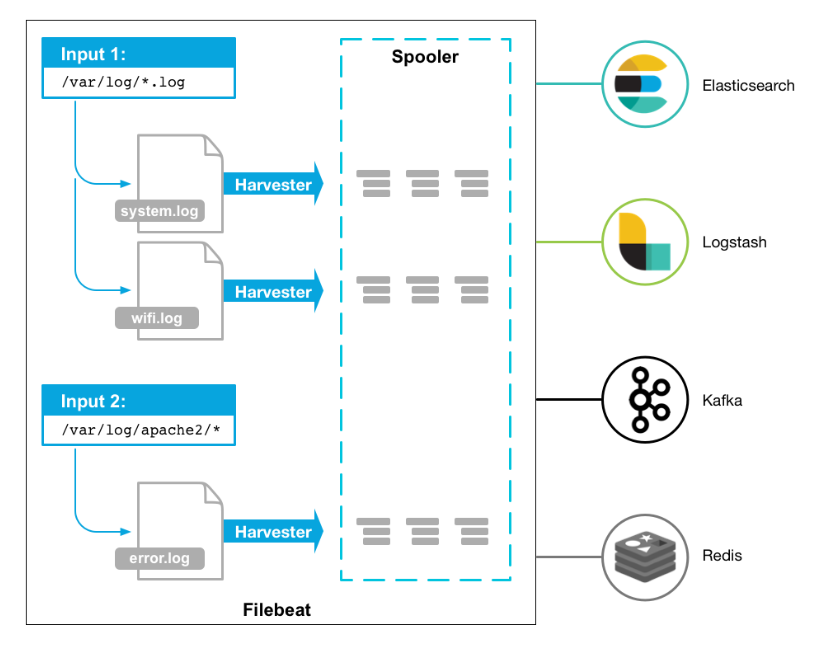
filebeat结构
Filebeat涉及两个组件:查找器prospector和采集器harvester,来读取文件(tail file)并将事件数据发送到指定的输出。
启动Filebeat时,它会启动一个或多个查找器,查看你为日志文件指定的本地路径。对于prospector所在的每个日志文件,prospector启动harvester。每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到你为Filebeat配置的输出。
当发送数据到Logstash或Elasticsearch时,Filebeat使用一个反压力敏感(backpressure-sensitive)的协议来解释高负荷的数据量。当Logstash数据处理繁忙时,Filebeat放慢它的读取速度。一旦压力解除,Filebeat将恢复到原来的速度,继续传输数据。
组件说明:
- Crawler:负责管理和启动各个 Input
- Input:负责管理和解析输入源的信息,以及为每个文件启动 Harvester。可由配置文件指定输入源信息。
- Harvester: Harvester 负责读取一个文件的信息。
- Pipeline: 负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件。
- Output: 输出源,可由配置文件指定输出源信息。
- Registrar:管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。
采集器Harvester
Harvester负责读取单个文件的内容。读取每个文件,并将内容发送到the output,每个文件启动一个harvester, harvester负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。
如果文件在读取时被删除或重命名,Filebeat将继续读取文件。这有副作用,即在harvester关闭之前,磁盘上的空间被保留。默认情况下,Filebeat将文件保持打开状态,直到达到close_inactive状态
关闭harvester会产生以下结果:
1)如果在harvester仍在读取文件时文件被删除,则关闭文件句柄,释放底层资源。
2)文件的采集只会在scan_frequency过后重新开始。
3)如果在harvester关闭的情况下移动或移除文件,则不会继续处理文件。
要控制收割机何时关闭,请使用close_ *配置选项
查找器Prospector
Prospector负责管理harvester并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。每个prospector都在自己的Go协程中运行。
Filebeat目前支持两种prospector类型:log和stdin。每个prospector类型可以定义多次。日志prospector检查每个文件来查看harvester是否需要启动,是否已经运行,或者该文件是否可以被忽略(请参阅ignore_older)。
只有在harvester关闭后文件的大小发生了变化,才会读取到新行。
注:Filebeat prospector只能读取本地文件,没有功能可以连接到远程主机来读取存储的文件或日志。
文件状态保存原理
Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。如果输出到logstash或kafka无法访问时,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
在Filebeat运行时,每个prospector内存中也会保存文件状态信息,当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。每个prospector为它找到的每个文件保留一个状态。由于文件可以被重命名或移动,因此文件名和路径不足以识别文件。对于每个文件,Filebeat存储唯一标识符以检测文件是否先前已被采集过。
数据消费不丢失原理
Filebeat将每个事件的传递状态存储在注册文件中,所以保证事件至少会被传送到配置的输出一次,并且不会丢失数据。
当输出阻塞或未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到接收端确认已收到。如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有收到事件。但在Filebeat关闭前未确认的任何事件在重新启动Filebeat时会再次发送。这可以确保每个事件至少发送一次,但最终会将重复事件发送到输出。
也可以通过设置shutdown_timeout选项来配置Filebeat以在关闭之前等待特定时间。
注意:Filebeat的至少一次交付保证包括日志轮换和删除旧文件的限制。如果将日志文件写入磁盘并且写入速度超过Filebeat可以处理的速度,或者在输出不可用时删除了文件,则可能会丢失数据。
读取日志文件被切割时设置
Logback日志切割用的是JDK里File#renameTo()方法。如果该方法失败,就再尝试使用复制数据的方式切割日志。只有当源文件和目标目录处于同一个文件系统、同volumn(即windows下的C, D盘)下该方法才会成功,切不会为重命名的后的文件分配新的inode值。也就是说,如果程序里一直保存着该文件的描述符,那么当程序再写日志时,就会向重命名后的文件中写。
当logback把日志重命名后,filebeat仍然会监控重命名后的日志,新创建的日志文件就看不到了。实际上,filebeat是通过close_inactive和scan_frequency两个参数(机制)来应对
- close_inactive
该参数指定当被监控的文件多长时间没有变化后就关闭文件句柄(file handle)。官方建议将这个参数设置为一个比文件最大更新间隔大的值。比如文件最长5s更新一次,那就设置成1min。默认值为5min。
- scan_frequency
该参数指定Filebeat搜索新文件的频率(时间间隔)。当发现新的文件被创建时,Filebeat会为它再启动一个 harvester 进行监控,默认为10s。
综合以上两个机制,当logback完成日志切割后(即重命名),此时老的harvester仍然在监控重命名后的日志文件,但是由于该文件不会再更新,因此会在close_inactive时间后关闭这个文件的 harvester。当scan_frequency时间过后,Filebeat会发现目录中出现了新文件,于是为该文件启动 harvester 进行监控。这样就保证了切割日志时也能不丢不重的传输数据。(不重是通过为每个日志文件保存offset实现的)
filebeat安装
压缩包方式安装
linux版本安详包,filebeat-7.7.0-linux-x86_64.tar.gz
curl-L-Ohttps://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.7.0-linux-x86_64.tar.gz
tar -xzvf filebeat-7.7.0-linux-x86_64.tar.gz配置示例文件:filebeat.reference.yml(包含所有未过时的配置项)
配置文件:filebeat.yml
基础命令
详情见官网:https://www.elastic.co/guide/en/beats/filebeat/current/command-line-options.html
export #导出
run #执行(默认执行)
test #测试配置
keystore #秘钥存储
modules #模块配置管理
setup #设置初始环境例如:./filebeat test config #用来测试配置文件是否正确
开启filebeat
- 调试模式下采用:终端启动(退出终端或 ctrl+c 会退出运行)
./filebeat -e -c filebeat.yml- 线上环境配合 error 级别使用:以后台守护进程启动启动 filebeats
nohup ./filebeat -e -c filebeat.yml &- 零输出启动(不推荐):将所有标准输出及标准错误输出到
/dev/null空设备,即没有任何输出信息。
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &注意:一台服务器只能启动一个filebeat进程。
停止filebeat
ps -ef |grep filebeat
kill -9 $pid输入输出
支持的输入组件:
Multilinemessages,Azureeventhub,CloudFoundry,Container,Docker,GooglePub/Sub,HTTPJSON,Kafka,Log,MQTT,NetFlow,Office365ManagementActivityAPI,Redis,s3,Stdin,Syslog,TCP,UDP(最常用的额就是log)
支持的输出组件:
Elasticsearch,Logstash,Kafka,Redis,File,Console,ElasticCloud,Changetheoutputcodec。最常用的就是Elasticsearch,Logstash,kafka
keystore的使用
keystore主要是防止敏感信息被泄露,比如密码等,像ES的密码,这里可以生成一个key为ES_PWD,值为es的password的一个对应关系,在使用es的密码的时候就可以使用${ES_PWD}使用
创建一个存储密码的keystore:filebeat keystore create
然后往其中添加键值对,例如:filebeatk eystore add ES_PWD
使用覆盖原来键的值:filebeat key store add ES_PWD–force
删除键值对:filebeat key store remove ES_PWD
查看已有的键值对:filebeat key store list
例如:后期就可以通过${ES_PWD}使用其值,例如:
output.elasticsearch.password:"${ES_PWD}"
filebeat.yml配置说明
参考官网:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-log.html
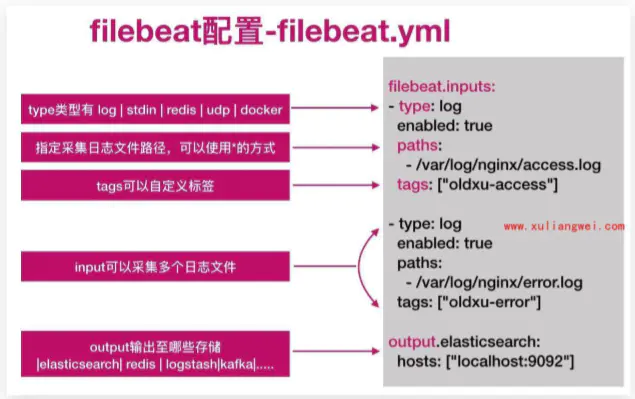
filebeat.inputs:
-type: log #input类型为log
enable: true #表示是该log类型配置生效
paths: #指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
- /var/log/* /*.log #则只会去/var/log目录的所有子目录中寻找以".log"结尾的文件,而不会寻找/var/log目录下以".log"结尾的文件。
recursive_glob.enabled: #启用全局递归模式,例如/foo/**包括/foo, /foo/*, /foo/*/*
encoding:#指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的
exclude_lines: ['^DBG'] #不包含匹配正则的行
include_lines: ['^ERR', '^WARN'] #包含匹配正则的行
harvester_buffer_size: 16384 #每个harvester在获取文件时使用的缓冲区的字节大小
max_bytes: 10485760 #单个日志消息可以拥有的最大字节数。max_bytes之后的所有字节都被丢弃而不发送。默认值为10MB (10485760)
exclude_files: ['\.gz$'] #用于匹配希望Filebeat忽略的文件的正则表达式列表
ingore_older: 0 #默认为0,表示禁用,可以配置2h,2m等,注意ignore_older必须大于close_inactive的值.表示忽略超过设置值未更新的
文件或者文件从来没有被harvester收集
close_* #close_ *配置选项用于在特定标准或时间之后关闭harvester。 关闭harvester意味着关闭文件处理程序。 如果在harvester关闭
后文件被更新,则在scan_frequency过后,文件将被重新拾取。 但是,如果在harvester关闭时移动或删除文件,Filebeat将无法再次接收文件
,并且harvester未读取的任何数据都将丢失。
close_inactive #启动选项时,如果在制定时间没有被读取,将关闭文件句柄
读取的最后一条日志定义为下一次读取的起始点,而不是基于文件的修改时间
如果关闭的文件发生变化,一个新的harverster将在scan_frequency运行后被启动
建议至少设置一个大于读取日志频率的值,配置多个prospector来实现针对不同更新速度的日志文件
使用内部时间戳机制,来反映记录日志的读取,每次读取到最后一行日志时开始倒计时使用2h 5m 来表示
close_rename #当选项启动,如果文件被重命名和移动,filebeat关闭文件的处理读取
close_removed #当选项启动,文件被删除时,filebeat关闭文件的处理读取这个选项启动后,必须启动clean_removed
close_eof #适合只写一次日志的文件,然后filebeat关闭文件的处理读取
close_timeout #当选项启动时,filebeat会给每个harvester设置预定义时间,不管这个文件是否被读取,达到设定时间后,将被关闭
close_timeout 不能等于ignore_older,会导致文件更新时,不会被读取如果output一直没有输出日志事件,这个timeout是不会被启动的,
至少要要有一个事件发送,然后haverter将被关闭
设置0 表示不启动
clean_inactived #从注册表文件中删除先前收获的文件的状态
设置必须大于ignore_older+scan_frequency,以确保在文件仍在收集时没有删除任何状态
配置选项有助于减小注册表文件的大小,特别是如果每天都生成大量的新文件
此配置选项也可用于防止在Linux上重用inode的Filebeat问题
clean_removed #启动选项后,如果文件在磁盘上找不到,将从注册表中清除filebeat
如果关闭close removed 必须关闭clean removed
scan_frequency #prospector检查指定用于收获的路径中的新文件的频率,默认10s
tail_files:#如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,
而不是从文件开始处重新发送所有内容。
symlinks:#符号链接选项允许Filebeat除常规文件外,可以收集符号链接。收集符号链接时,即使报告了符号链接的路径,
Filebeat也会打开并读取原始文件。
backoff: #backoff选项指定Filebeat如何积极地抓取新文件进行更新。默认1s,backoff选项定义Filebeat在达到EOF之后
再次检查文件之间等待的时间。
max_backoff: #在达到EOF之后再次检查文件之前Filebeat等待的最长时间
backoff_factor: #指定backoff尝试等待时间几次,默认是2
harvester_limit:#harvester_limit选项限制一个prospector并行启动的harvester数量,直接影响文件打开数
tags #列表中添加标签,用过过滤,例如:tags: ["json"]
fields #可选字段,选择额外的字段进行输出可以是标量值,元组,字典等嵌套类型
默认在sub-dictionary位置
fields:
app_id: query_engine_12
fields_under_root #如果值为ture,那么fields存储在输出文档的顶级位置
multiline.pattern #必须匹配的regexp模式
multiline.negate #定义上面的模式匹配条件的动作是 否定的,默认是false
假如模式匹配条件'^b',默认是false模式,表示讲按照模式匹配进行匹配 将不是以b开头的日志行进行合并
如果是true,表示将不以b开头的日志行进行合并
multiline.match # 指定Filebeat如何将匹配行组合成事件,在之前或者之后,取决于上面所指定的negate
multiline.max_lines #可以组合成一个事件的最大行数,超过将丢弃,默认500
multiline.timeout #定义超时时间,如果开始一个新的事件在超时时间内没有发现匹配,也将发送日志,默认是5s
max_procs #设置可以同时执行的最大CPU数。默认值为系统中可用的逻辑CPU的数量。
name #为该filebeat指定名字,默认为主机的hostname异常堆栈的多行合并问题
在收集日志过程中还常常涉及到对于应用中异常堆栈日志的处理,此时有两种方案,一种是在采集是归并,一种是 Logstash 过滤时归并,更建议在客户端 agent 上直接实现堆栈的合并,把合并操作的压力在输入源头上进行控制,filebeat 合并行的思路有两种,正向和逆向处理。由于 filebeat 在合并行的时候需要设置 negate 和 match 来决定合并动作,意义混淆,简直是一种糟糕的设计,直接附上配置源码和说明便于理解。
- 符合条件才合并,容易有漏网之鱼 说明:将以空格开头的所有行合并到上一行;并把以Caused by开头的也追加到上一行
multiline:
pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
negate: false
match: afternegate 参数为 false,表示“否定参数=false”。multiline 多行参数负负得正,表示符合 pattern、match 条件的行会融入多行之中、成为一条完整日志的中间部分。如果match=after,则以b开头的和前面一行将合并成一条完整日志;如果 match=before,则以 b 开头的和后面一行将合并成一条完整日志。
- 不符合条件通通合并,需事先约定 说明:约定一行完整的日志开头必须是以“[”开始,不符合则归并。
multiline:
pattern: '^\['
negate: true
match: afternegate 参数为 true,表示“否定参数=true”。multiline 多行参数为负,表示符合 match 条件的行是多行的开头,是一条完整日志的开始或结尾。如果 match=after,则以 b 开头的行是一条完整日志的开始,它和后面多个不以 b 开头的行组成一条完整日志;如果 match=before,则以 b 开头的行是一条完整日志的结束,和前面多个不以 b 开头的合并成一条完整日志。
配置实践
filebeat.inputs:
- type: log
enabled: true
paths:
- logPath1
scan_frequency: 3s
- type: log
enabled: true
paths:
- logPath2
scan_frequency: 3s
- type: log
enabled: true
paths:
- logPath3
scan_frequency: 3s
processors:
- drop_event:
when:
regexp:
message: "^test123"
- drop_fields:
fields: ["log", "input", "agent", "ecs", "host"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
#----------------------------- kafka output --------------------------------
output.kafka:
hosts: ["kafkaIp1","kafkaIp2","kafkaIp3"]
topic: 'logTopic'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000参考文档:https://www.jianshu.com/p/0a5acf831409

















 4966
4966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









