







Linux多线程
文章目录
1.Linux线程概念
1.1 什么是线程
- 站在内核角度来理解进程:承担分配系统资源的基本实体,叫做进程
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列"
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
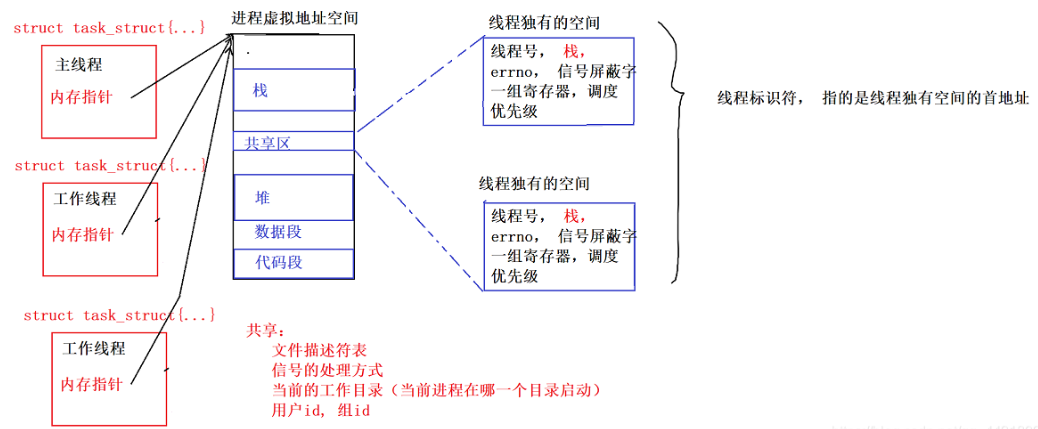
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
需要明确的是,一个进程的创建实际上伴随着其进程控制块(task_struct)、进程地址空间(mm_struct)以及页表的创建,虚拟地址和物理地址就是通过页表建立映射的,如下图:
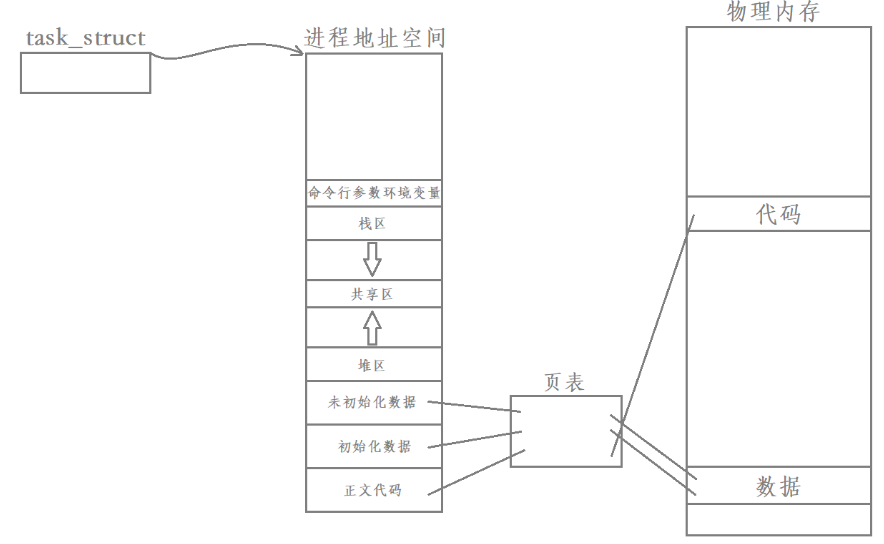
每个进程都有自己独立的进程地址空间和独立的页表,也就意味着所有进程在运行时本身就具有独立性,但如果我们在创建“进程”时,只创建task_struct,并要求创建出来的task_struct和父task_struct共享进程地址空间和页表,那么创建的结果就是下面这样的:
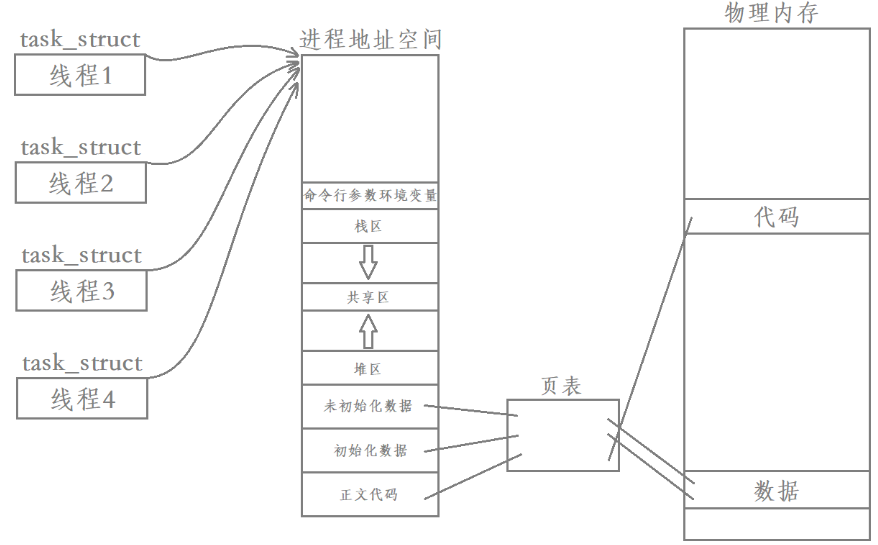
此时我们创建的实际上就是四个线程:
- 其中每一个线程都是当前进程里面的一个执行流,也就是我们常说的“线程是进程内部的一个执行分支”
- 同时我们也可以看出,线程在进程内部运行,本质就是线程在进程地址空间内运行,也就是说曾经这个进程申请的所有资源,几乎都是被所有线程共享的
线程与进程的包含问题:
- 下面用蓝色方框框起来的内容,我们将这个整体叫做进程,进程包含线程
- 因此,所谓的进程并不是通过task_struct来衡量的,除了task_struct之外,一个进程还要有进程地址空间、文件、信号等等,合起来称之为一个进程
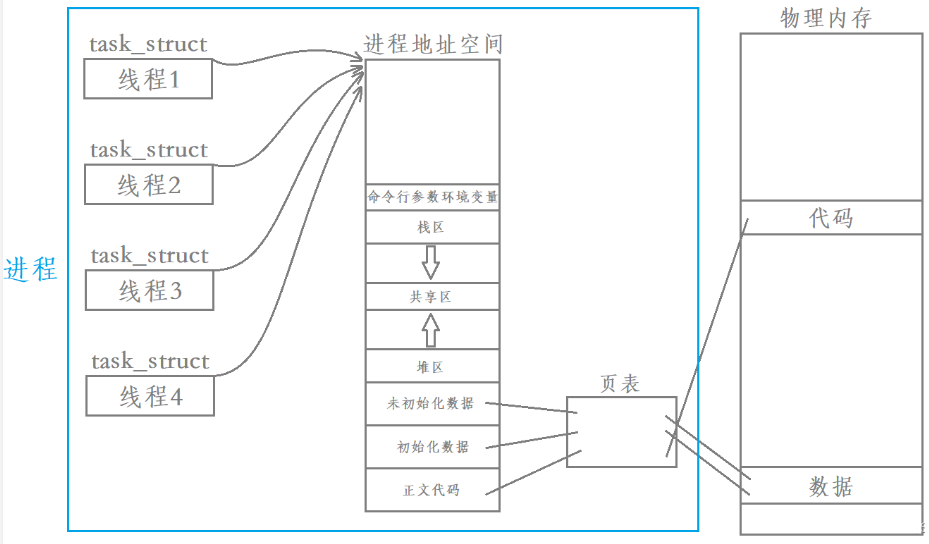
1.2 线程的执行流
- 线程是进程的一个执行分支,是在进程内部运行的一个执行流,是操作系统进行运算调度的最小单位
- 在linux里我们也把线程成为轻量级进程(LWP,LightWeightProcess),因为linux里其实没有真正的线程,线程是通过进程模拟出来的(在内核里都是一个个的task_struct)
- 没学线程前我们说进程是操作系统最小的调度单位,因为那时我们写的代码都是单线程的,一个进程只有一个执行流,所以那么说也没错,准确一点就是线程是操作系统调度的最小单位
线程的执行流分为两种:单执行流与多执行流
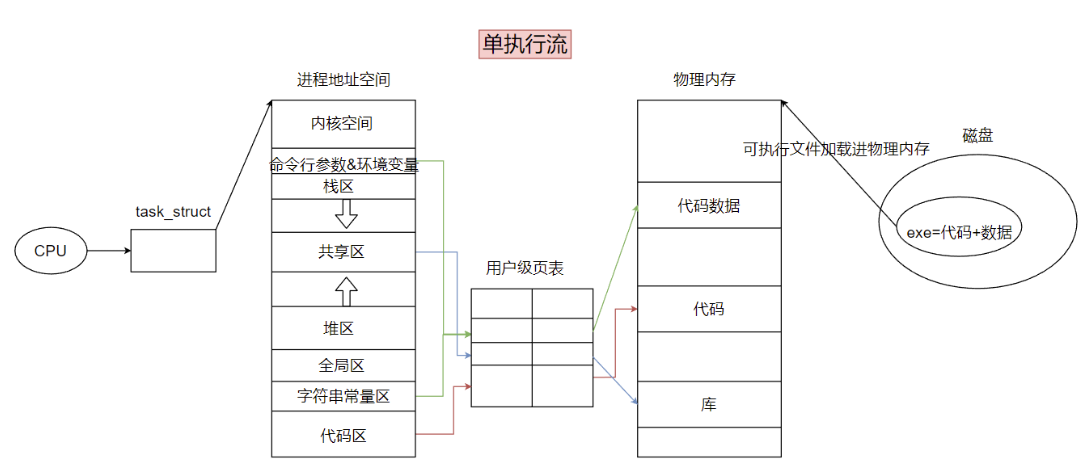

【重要】通过上面两张图得出的一些结论,同时补充一些概念:
- 站在CPU的角度,进程与线程没有任何区别,它看到的都是task_struct,这也是为什么线程在linux里也叫轻量级进程,也说明linux下没有真正意义上的线程。简单来说,CPU对线程0感知
- 线程之间是共用一个地址空间的,这说明比起进程之间的切换,线程的切换更加轻量级。因为进程切换可能要保存页表、地址空间的数据甚至缓存的数据等等,而线程之间切换时这些都不用动,自然切换的代价也比较小
- 进程:线程=1:n,说明系统内有大量的线程,所以操作系统必定要把线程管理起来,说明如果一个系统支持真正的线程,比如windows,那必然是有一个结构(TCB)来描述这个线程的属性,并且将其组织起来,但是往往比较复杂,linux下虽然没有真正的线程,但是优点就是简单
- linux下没有真正意义的线程,这就说明OS不可能在系统层面提供操作线程的接口,而是一些封装好给用户的轻量级接口
- CPU调度的都是线程,即线程是CPU调度的最小单位
- 站在系统的角度,进程是承担系统资源的基本单位。因为第二个线程用的资源都是第一个线程申请好的
- 线程在进程内部运行,这句话的意思是线程在进程地址空间内运行
- 通过页表可以看到物理内存,也即真正的资源,同时说明只要划分页表我们就可以让线程看到进程的部分资源
- 关于页表,页表不仅仅记录了虚拟地址与物理地址的映射,还有一些别的属性,如权限,是否命中等等,这说明页表的大小不是一个字节就能记录的。一般32位的机器物理内存是4G,说明有232这么多个地址要映射,即页表要记录232个映射关系,表示每一个映射关系需要的字节都大于1,说明页表整体大小大于4G,放不进内存,此时就引出了二级页表。负责这块的硬件就是MMU,具体的了解可以查询二级页表的相关资料
- 线程数越多越好吗?并不是,建议与计算机的核数相当。线程过多会导致大部分时间花在调度上,而没有花在线程的执行上,有点买椟还珠的意思
- 没有线程替换,线程替换就是整个进程被替换
- CPU不需要线程的概念,linux下线程这个概念是给用户的,因为用户需要多线程编程
- 用户层通过TCB(线程控制块)来知道线程的id、状态、优先级和其他属性,用来进行用户级的线程管理。TCB不由内核维护,而是由用户空间维护
1.3 线程的优缺点
线程的优点:
- 创建一个新的线程的代价比创建一个进程小得多。创建一个线程虽然也需要创建数据结构,但是并不需要重新开辟资源,只需要将进程的部分资源分配给线程。创建一个进程不仅需要创建大量数据结构,还需要重新创建资源
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作少。线程只是进程的部分资源,切换的资源少
- 线程占用的资源比进程少
- 能充分利用多处理器的可并行数量
- 在等待慢速的I/O操作结束的同时,程序可以执行其它的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠,线程可以同时等待不同的I/O操作。I/O操作是与外设交互数据,会很慢
线程的缺点:
- 性能缺失
- 一个处理器只能处理一个线程,如果线程数比可用处理器数多,会有较大的性能损失,会增加额外的同步和调度开销,而资源不变
- 鲁棒性降低
- 编写多线程时,可能因为共享了不该共享的变量,一个线程修改了该变量会影响另外一个线程。多线程之间变量时同一个变量,多进程之间变量不是同一个变量,写时拷贝
- 缺乏访问的控制
- 进程时访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响
- 编程难度高
1.4 线程的异常与用途
线程的异常:
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
线程的用途:
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
2.进程与线程的区别总结
- 进程是资源分配的基本单位,线程是调度的基本单位
- 进程:线程 = 1:n
- Linux中没有真正意义上的线程,线程是用进程模拟的
- 线程又称为轻量级进程
- 线程共享进程数据,但也拥有自己的一部分数据
- 进程的健壮性比线程好
- 多线程比进程消耗资源少,切换快,运行效率高
3.多进程与多线程的应用场景
多进程应用场景:shell、守护进程、分布式服务

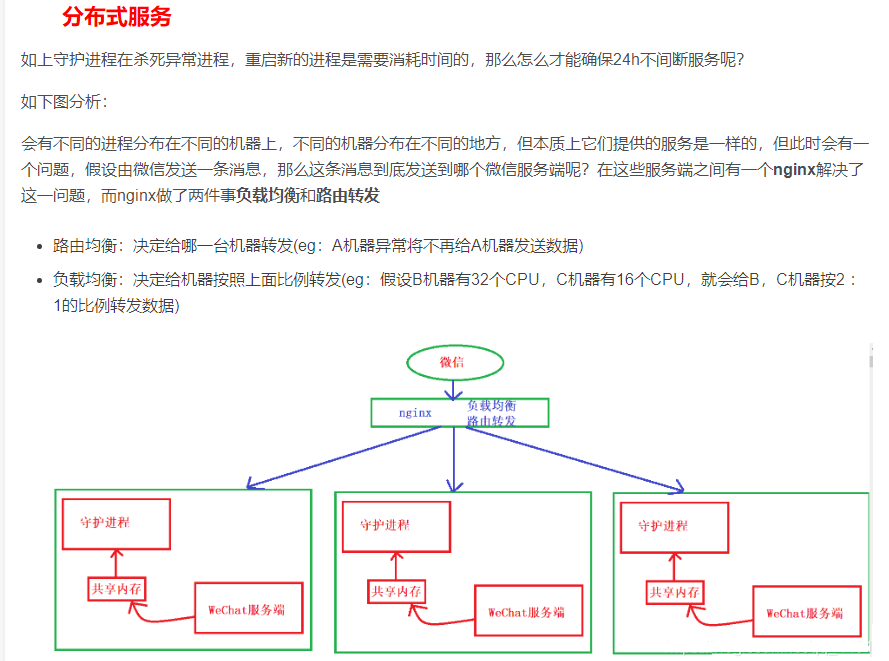
多线应用场景:
- 不同任务间需要大量共享数据或频繁通信时
- 提供非均质的服务(有优先级任务处理)事件响应有优先级
- 单任务并行计算,在非CPU Bound的场景下提高响应速度,降低时延
- 与人有IO交互的应用,良好的用户体验(键盘鼠标的输入,立刻响应)
4.线程控制
4.1 进程ID与线程ID
在Linux中由于没有真正的线程,目前的线程都是用原生线程库(Nagtive POSIX Thread Library)来实现。在这种实现下,线程又被称作轻量级进程,因为线程仍然使用进程描述符task_struct,但是只是执行进程的部分内容
没有线程之前,一个进程对应内核的一个进程描述符,对应进程的ID。引入线程之后,一个进程对应了一个或者多个线程,每一个线程作为CPU调度的基本单位,在内核态也有自己的ID
线程组,多线程的进程,又被称为线程组。每一个线程在内核中都存在一个进程描述符(task_struct),因为Linux下,用进程来模拟线程。进程结构体中的pid,表明上看是进程ID,其实不是,它实际对应线程ID,进程描述符中的tgid,对应用户层面的进程ID
我们来看看内核源码是什么样的:
- 总结:进程有自己的ID在源码中是pid,线程也有自己的ID,在源码中是tgid
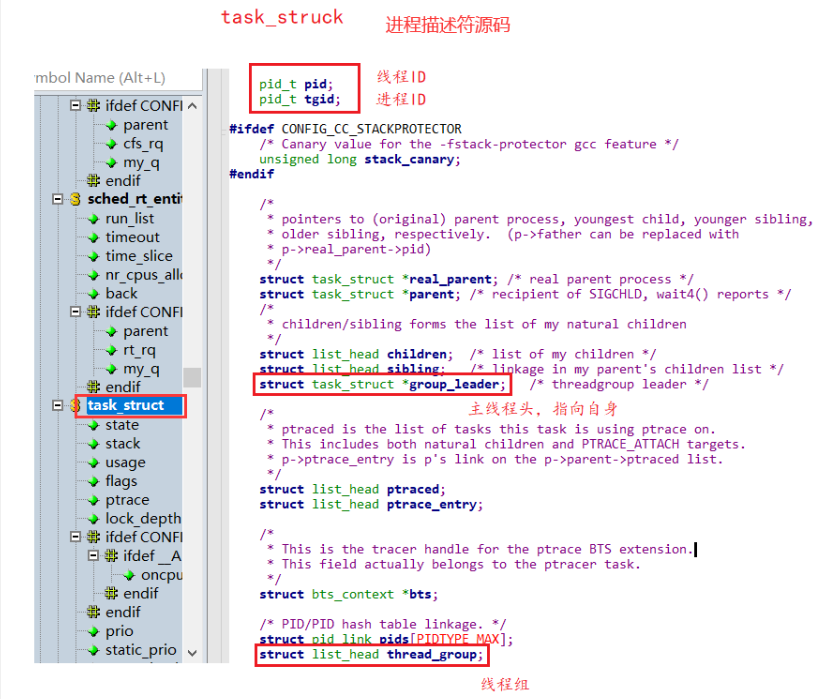
进程ID有什么用呢?可以表示线程属于哪个进程的。就可以知道进程有多少线程
在创建线程使用的函数pthread_create的第一个参数返回的也是线程的id但是和这里的线程id,不过,这里的线程id是用来标识线程的,后面有介绍创建线程函数返回的id
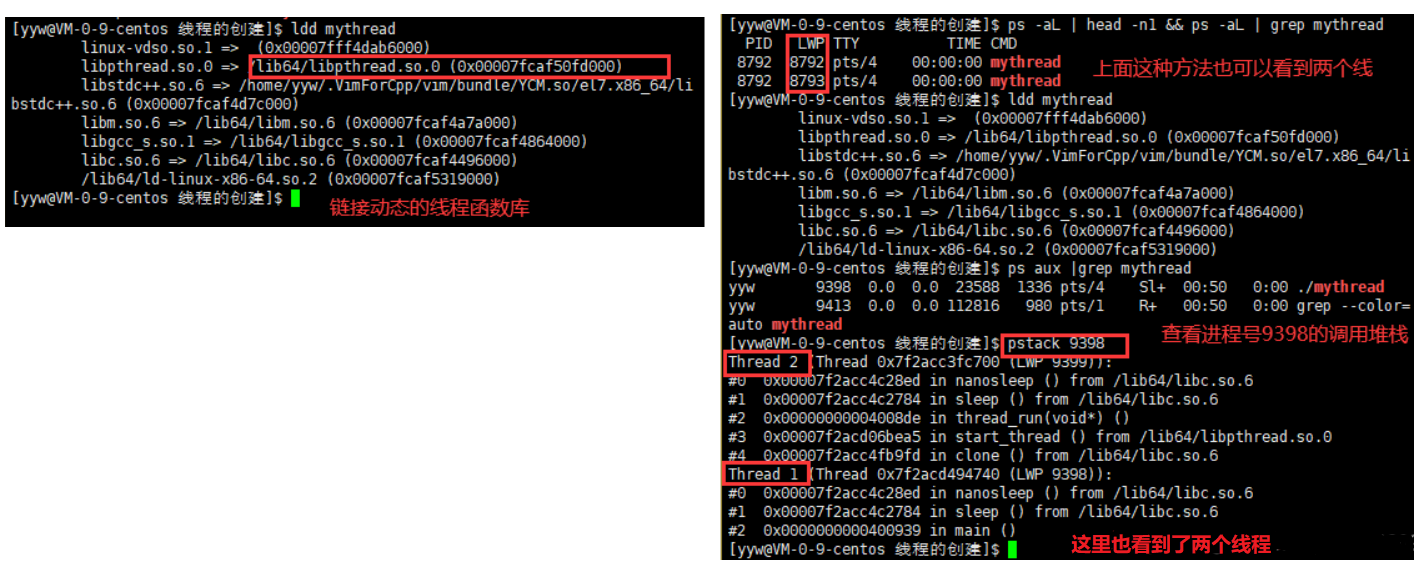
查看线程id的命令:
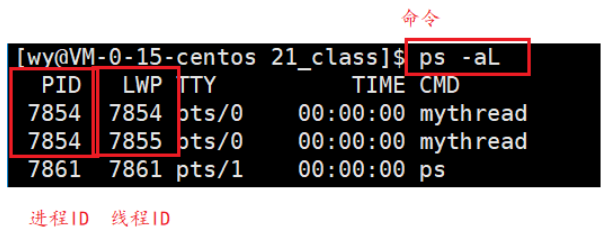
ps -aL
- PID显示的是进程ID
- LWP显示的是线程ID
我们发现进程mythread有两个线程,一个线程的id是7854,一个线程的ID是7855。整个进程的ID是7854但是有一个线程的ID和进程的ID相同,这不是巧合。线程组(进程)里的第一个线程,在用户态被称为主线程,在内核中被称为group leader。线程中创建的第一个线程,会将该线程的ID设置成和线程组的ID相同。所以线程组内存在一个线程ID和进程ID相同,这个线程为线程组的主线程- 至于线程组的其它线程ID则由内核负责分配。线程组的ID总和主线程ID一致
- 一个进程至少有一个线程。如果没有创建线程,该进程就是单线程的单进程
- 注意:线程和进程不一样,进程有父子进程的概念,但是线程没有,所有进程都是对等的关系
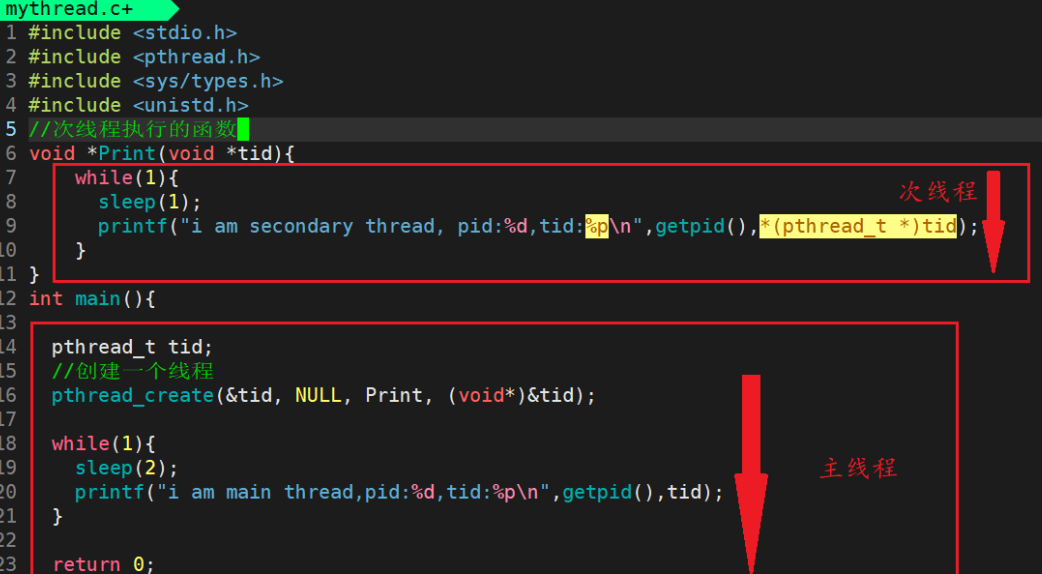
4.2 线程创建(pthread_create)
创建线程库函数是:pthread_create
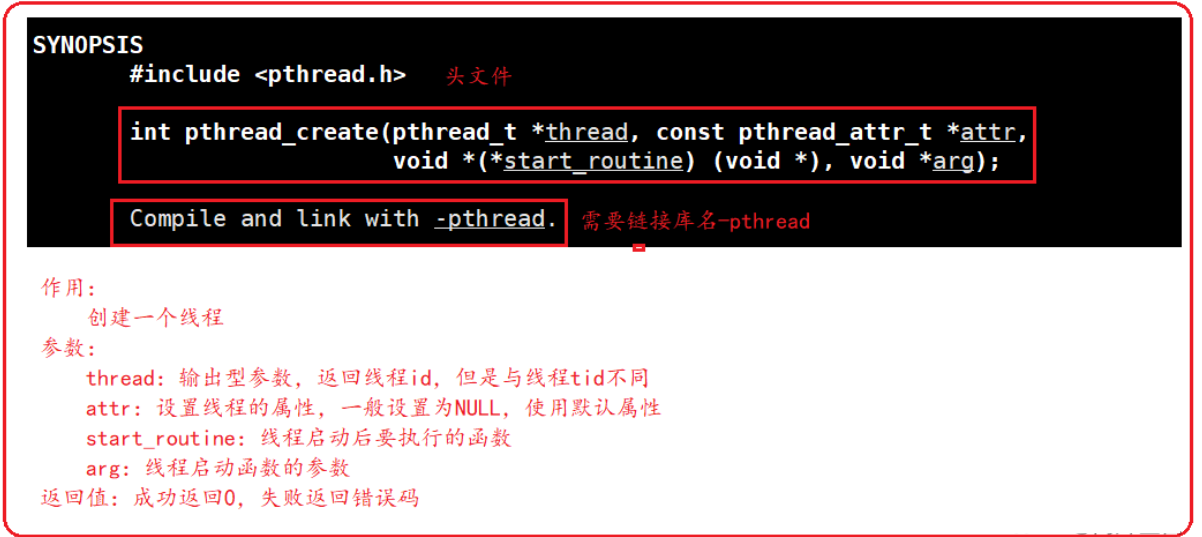
这个函数明确说明了需要链接库名-pthread,我们需要思考一些问题:
为什么连接线程库要指明库名?标准库不用指明库名?
- 因为标准库是语言自带的,第三方库不是语言自带的,可能是系统或者是用户自己安装的,线程库是Linux系统安装的,不是语言提供的,对于gcc编译器来说是第三方库。gcc默认连接库是标准库(语言提供的)。编译器命令行参数中没有第三方库的名字。所以给编译器指明库名
- 强调:找到库所在路径和使用该路径下的库文件,是两码事。找到路径找不到库,还需要指明库名。标准库中因为编译器命令行中有该库名
让我们来看看使用的例子:
mythread.cpp代码:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
using namespace std;
void* thread_run(void* arg)
{
while(1)
{
cout<<"i am "<<(char*)arg<<endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int ret=pthread_create(&tid,NULL,thread_run,(void*)"thread 1");
if(ret!=0)
{
return -1;
}
while(1)
{
cout<<"i am main thread"<<endl;
sleep(2);
}
return 0;
}
makefile代码:
mythread:mythread.cpp
g++ $^ -o $@ -lpthread
.PHONY:clean
clean:
rm -f mythread
例子结果:
4.3 线程终止(pthread_exit、pthread_cancel)
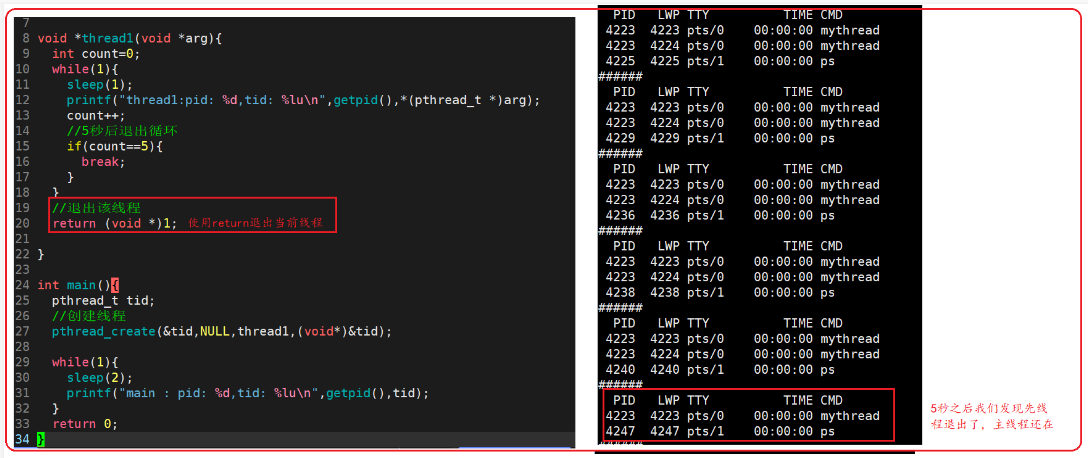
- 注意:主线程退出,整个进程就退出了
- 要某个线程终止而不让进程终止,有三种方法:
- 从线程函数return,这种情况对主线程不适用,因为主线程退出,整个进程就退出了
- 线程可以调用pthread_exit终止
- 一个线程可以调用pthread_cancel终止同一进程里的线程
新线程也可以用pthread_cancel终止主线程:
pthread_exit函数:
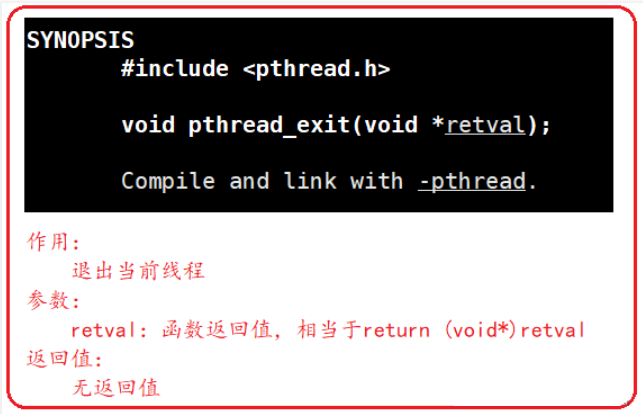
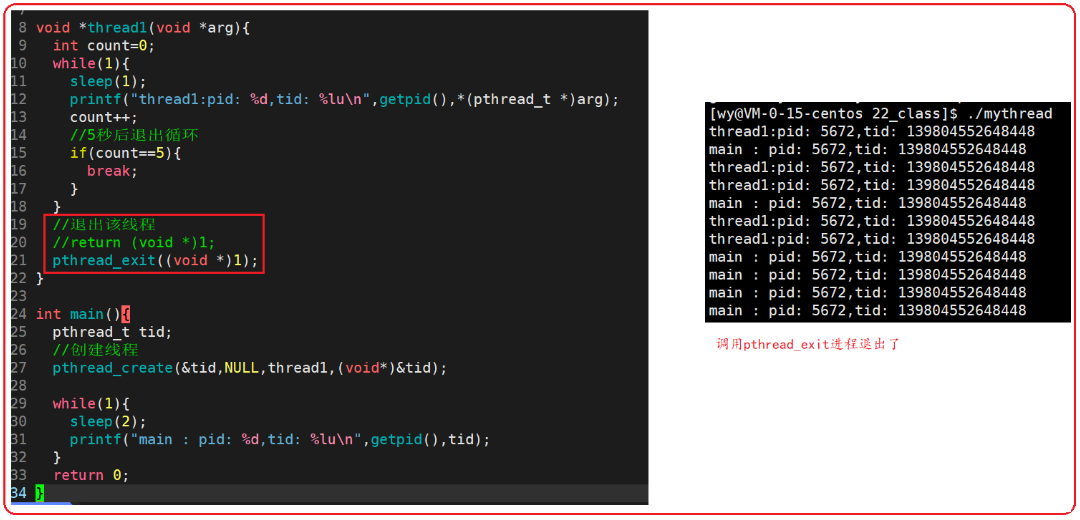
注意:使用return和pthread_exit返回的指针所指向的内存单元必须是全局或者是malloc分配的,不能是在线程函数栈上分配的,因为线程退出时,函数栈帧被释放了
pthread_cancel函数:
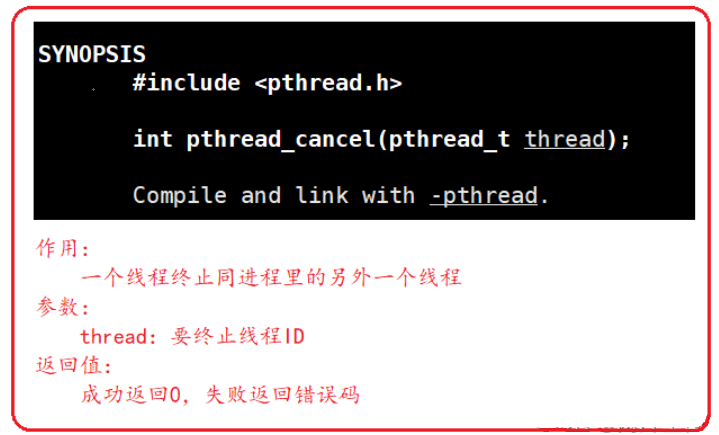
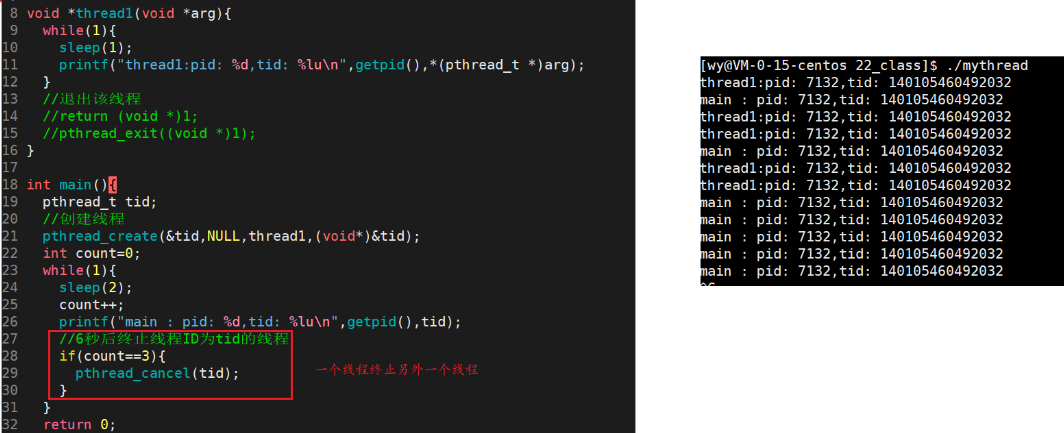
注意:不能使用exit(),exit的作用是不论在哪里调用,终止进程
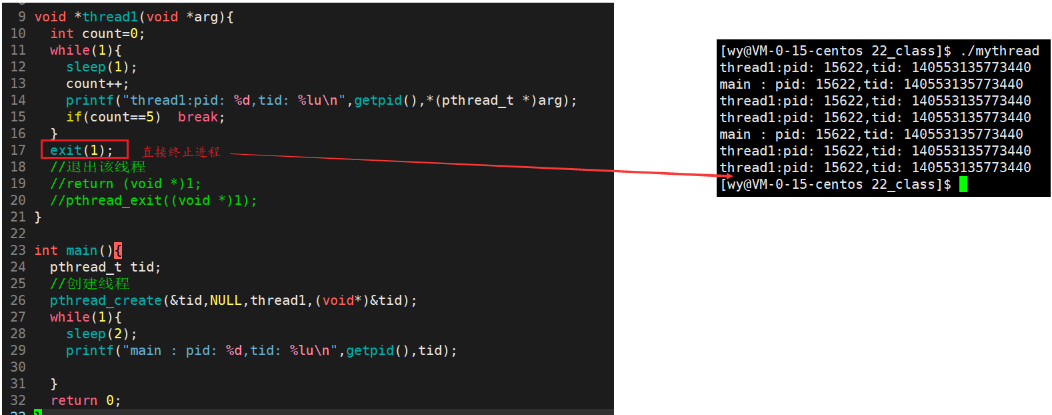
4.4 线程等待(pthread_join)
线程为什么需要等待?
- 已经退出的线程,其空间没有被释放,仍然在进程的地址空间内
- 创建的新线程不会复用刚才退出线程的地址空间
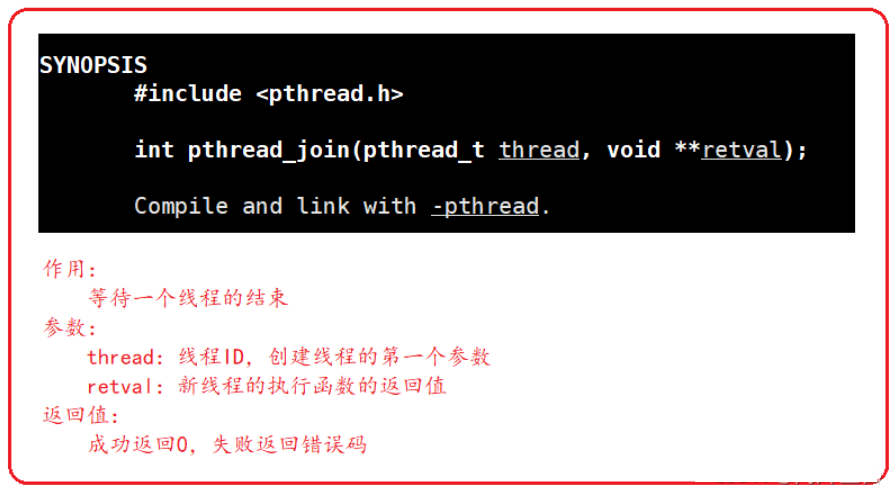
- 默认以阻塞方式等待
- 线程退出和进程退出一样,有三种状态:
代码正常运行,结果正确,正常退出代码正常运行,结果不正确,不正常退出代码出现异常,异常退出- 前两种情况以退出码来表述退出情况,后面一种以退出信号来表示
但是线程等待函数的第2个参数返回的是执行函数的返回值,也就是退出码,没有表示线程异常退出的情况,这是为什么的?
- 因为某个线程如果运行异常终止,整个进程都会终止。进程异常终止,就属于进程的等待处理的范畴了,不属于线程范畴。比如:一个线程函数有除0操作,硬件MMU发现异常,操作系统收到异常,向该进程发出信号,终止进程。信号处理的单位是进程
总的来说就是,等待线程只关心正常运行的退出情况,获取退出码。不关心异常退出情况,异常退出情况上升至进程处理范畴
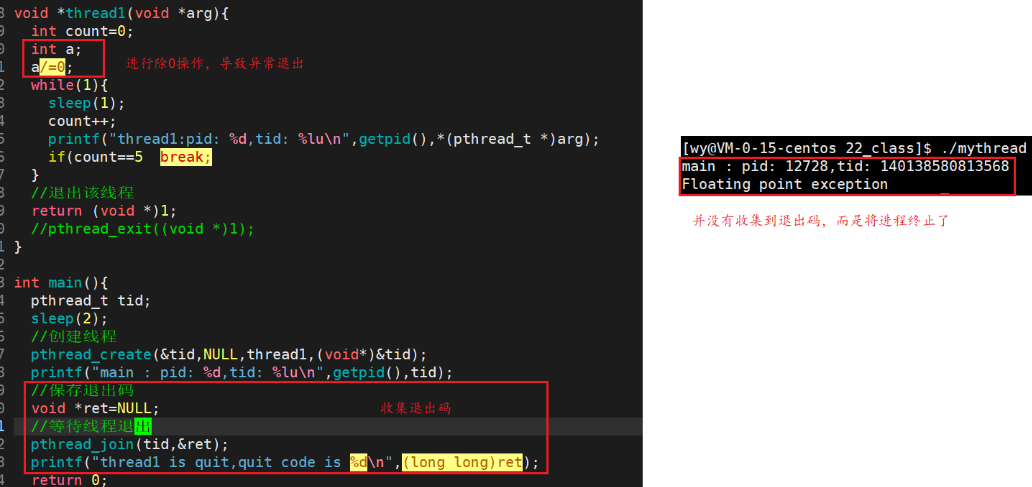
那么这里我们怎么获取退出码呢?
调用pthread_join函数的线程默认以阻塞方式等待线程id为thread参数的线程终止,线程以不同的方式终止,得到的终止状态不同
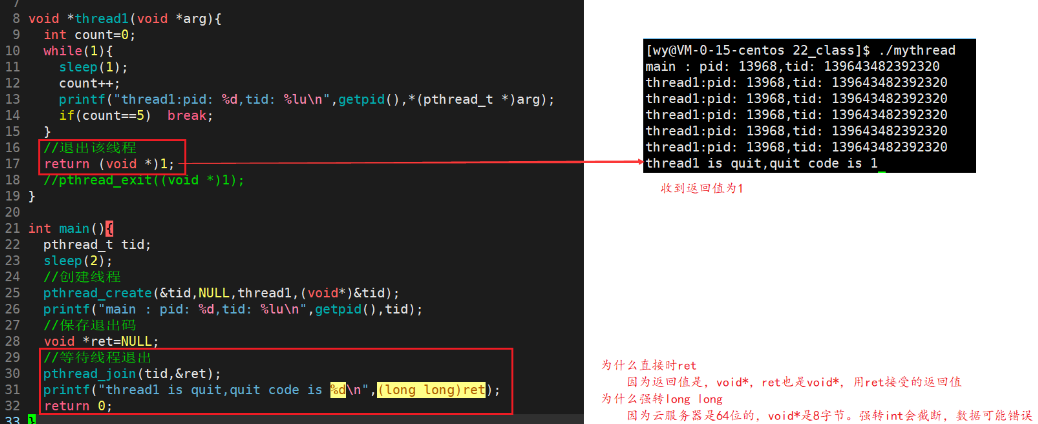
- 如果线程通过return终止,pthread_join函数的第二个参数retval直接指向return后面的返回值
- 如果线程通过pthread_exit终止,pthread_join函数的第二个参数retval直接指向pthread_exit参数‘
- 如果线程通过被其它线程调用pthread_cancel终止,pthread_join函数的第二个参数retval直接存放的是一个常数宏PTHREAD CANCELED,值是-1。
#define PTHREAD CANCELED (void *)-1- 如果对不关心返回值,可以将ret_val设为NULL
三种情况的返回值如下图:
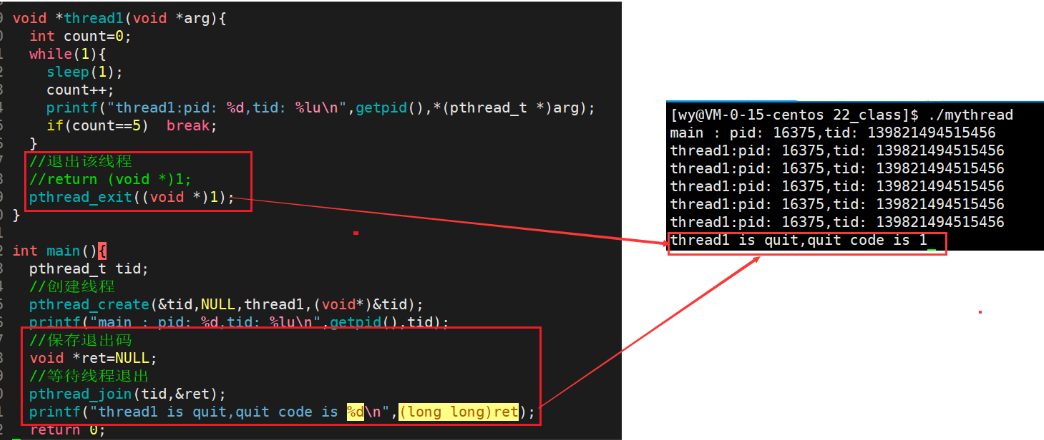
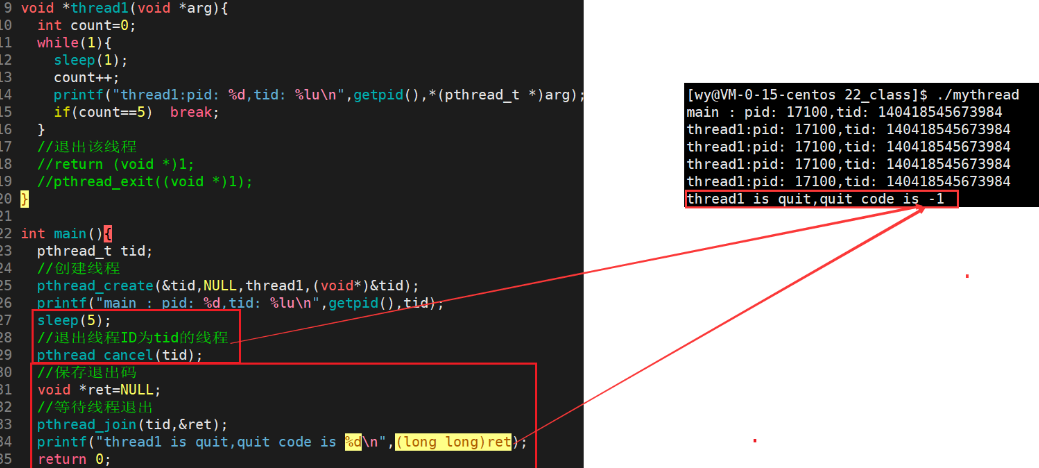
return:
pthread_exit:
pthread_cancel:
4.5 线程ID及进程地址空间布局
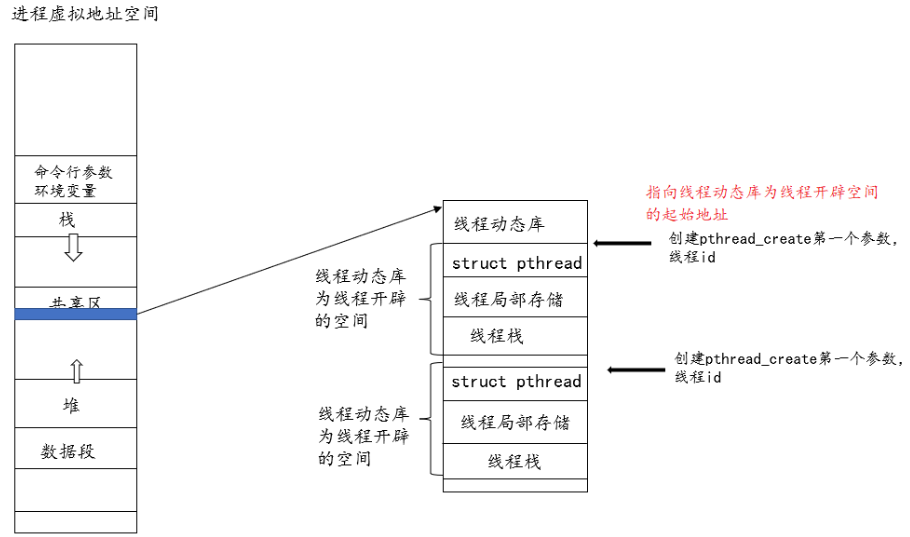
- 上面讨论的线程ID(LWP)属于进程调度范畴。因为线程是轻量级进程,是操作系统调度的基本单位,所以会需要一个ID来标识给线程
- 这里讨论的线程ID,是创建线程函数pthread_create的第一个参数。该内存是线程第三方库为线程在内存中开辟的一块空间。该线程ID返回该空间的起始地址。这个进程ID数据线程库的范畴,线程库的后序操作,就是根据该线程ID来操作的
为什么线程ID返回的是起始地址?
由于Linux没有真正意义上的线程,线程管理需要线程库来做,线程库管理线程也是要先描述再组织,描述如下图,组织成一个数组,再返回数组的起始地址
可以通过函数查询当前线程ID:
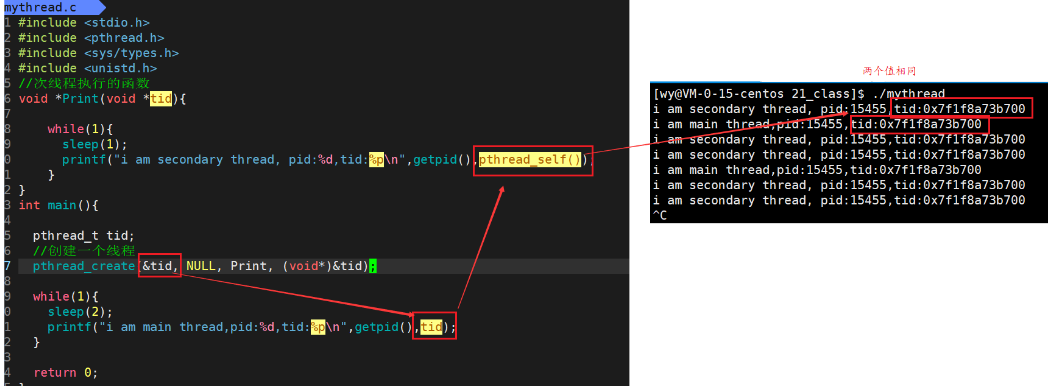
4.6 POSIX线程库与内核线程的关系
- 由于在Linux中没有真正的线程,所以系统没有提供接口(系统调用),需要用户自己来编写。但是我们有一个第三方库,POSIX线程库给我们提供了管理线程的功能,但是线程需要内核来调度和执行
- 要使用这些库函数需要引入头文件<pthread.h>
- 链接这些线程函数库时要使用编译器命令"-lpthread"选项

4.3 pthread_create的传参问题
传参问题的探讨与验证:
- 假设要往创建的工作线程中传入一个参数1,首先要将参数强转为
(void*)类型,然后将参数的地址传入,而在工作线程中使用是只需将(void*)转换为(int*)即可,如下代码:
#include<iostream>
#include<unistd.h>
#include<pthread.h>
using namespace std;
void* MyThreadStrat(void* arg)
{
int* i=(int*)arg;//(void*)变成了(int*)
while(1)
{
cout<<"MyThreadStrat:"<<*i<<endl;
sleep(1);
}
return NULL;
}
int main()
{
pthread_t tid;
int i=1;
int ret=pthread_create(&tid,NULL,MyThreadStrat,(void*)&i);
if(ret!=0)
{
cout<<"线程创建失败!"<<endl;
return 0;
}
while(1)
{
sleep(1);
cout<<"i am main thread"<<endl;
}
return 0;
}
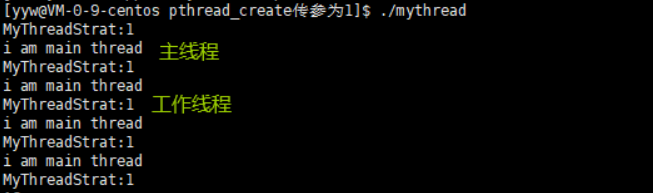
从上面的结果可以看出,虽然参数可以正常传入,但实际是存在一定的错误的,因为局部变量 i 传入的时候生命周期未结束,而在传递给工作线程的时候生命周期结束了,那么这块局部变量开辟的区域就会自动释放,而此时工作线程还在访问这块地址,就会出现非法访问
让我们将代码改成循环的来看看:
#include<iostream>
#include<unistd.h>
#include<pthread.h>
using namespace std;
void* MyThreadStrat(void* arg)
{
int* i=(int*)arg;
while(1)
{
cout<<"MyThreadStrat:"<<*i<<endl;
sleep(1);
}
return NULL;
}
int main()
{
pthread_t tid;
int i=0;
for( i=0;i<4;i++)
{
int ret=pthread_create(&tid,NULL,MyThreadStrat,(void*)&i);
if(ret!=0)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2849
2849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











