







构建机器学习应用程序在许多方面与标准工程范式相似,但在一个关键方面有所不同:需要将数据作为原材料来使用。数据项目的成功在很大程度上取决于您所获取数据的质量以及处理方式。并且由于处理数据属于数据科学领域,因此有助于理解数据科学工作流程: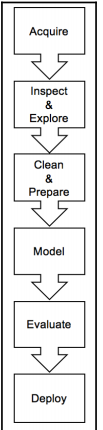
该过程按以下顺序进行以下六个步骤:采集,检查和探索,清理和准备,建模,评估和最终部署。
通常需要回溯到先前的步骤,例如在检查和准备数据或进行评估和建模时,但是可以如上图所示描述高级别的过程。现在让我们详细讨论每个步骤。
采集
机器学习应用程序的获取数据可以来自许多来源。可能会以CSV文件的形式通过电子邮件发送,也可能来自下拉服务器日志,或者可能需要构建自定义网络抓取工具。
数据也可以采用多种格式。在大多数情况下,它将是基于文本的数据,但是正如我们将要看到的那样,机器学习应用程序可以使用图像甚至视频文件轻松构建。
无论采用哪种格式,一旦保护了数据的安全,就必须了解数据中的内容以及不包含哪些内容。
检查和探索
一旦获取了数据,下一步就是检查和探索。在此阶段,主要目标是对数据进行完整性检查,而实现此目的的最佳方法是查找不可能或非常不可能的事情。
例如,如果数据具有唯一标识符,请检查是否确实只有一个。如果数据是基于价格的,请检查数据是否始终为正;以及任何数据类型
检查最极端的情况。 他们有道理吗? 一个好的做法是对数据进行一些简单的统计测试并将其可视化。
此外,某些数据可能丢失或不完整。 在此阶段要注意这一点非常重要,因为稍后在清洁和准备阶段需要解决此问题。 模型仅与输入的数据一样好,因此正确执行此步骤至关重要。
清洁和准备
当所有数据都整理好后,下一步就是将其放置在适合建模的格式中。 此阶段包含许多过程,例如过滤,聚合,估算和转换。 必需的操作类型将高度依赖于数据类型以及所使用的库和算法的类型。 例如,对于基于自然语言的文本,所需的转换将与时间序列数据所需的转换非常不同。
建模
一旦完成数据准备,下一步便是建模。
在此阶段,选择适当的算法,并根据数据训练模型。在此阶段,有许多最佳实践可以遵循,我们将详细讨论它们,但是基本步骤涉及将数据分为训练,测试和验证集。
数据的拆分似乎是不合逻辑的(尤其是当更多数据通常会产生更好的模型时),但是正如我们将看到的那样,这样做可以使我们获得有关模型在现实世界中的性能的更好反馈,并阻止我们建模的主要罪过:过拟合。
评估建立模型并做出预测后,下一步就是了解模型的效果。
这是评估寻求解决的问题。衡量模型性能的方法有很多种,并且再次很大程度上取决于数据的类型和所使用的模型,但是总的来说,我们正在寻求答案 模型的预测与实际值有多接近的问题。
有许多令人费解的术语,例如均方根误差,欧几里德距离和F1得分,但最后,它们都只是对实际值和估计的预测之间的距离的度量。
部署
一旦模型的性能令人满意,下一步就是部署。 根据使用情况,这可以采取多种形式,但是常见的场景包括在另一个较大的应用程序,定制的Web应用程序中甚至只是一个简单的cron作业中将其用作功能。















 2970
2970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









